
数据挖掘入门与实战 公众号: datadw
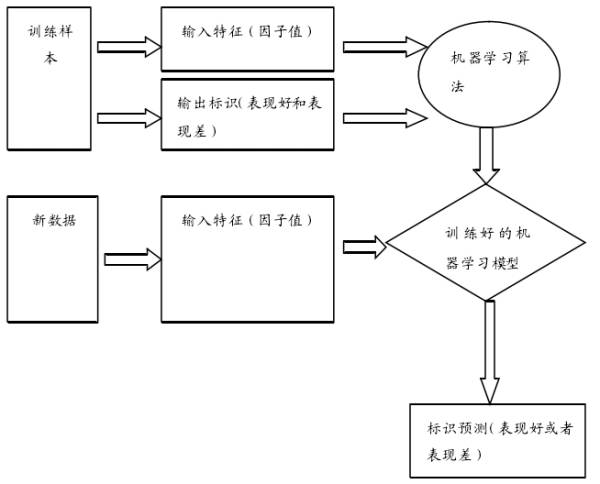
监督式学习是机器学习的一个分支,可以通过训练样本而建立起一个输入和输出之间的函数,并以此对新的事件进行预测。
典型的监督学习流程如下:
支持向量机
是监督学习中一种常用的学习方法。
支持向量机( Support Vector Machines SVM )是一种比较好的实现了结构风险最小化思想的方法。它的机器学习策略是结构风险最小化原则 为了最小化期望风险,应同时最小化经验风险和置信范围)。具体就不详细介绍了,百度有很多资料。
http://scikit-learn.org/stable/modules/svm.html#svm 中是SVM函数和简单介绍。
from sklearn.svm import SVR 可以构造支持向量回归(Support Vector Regression)模型
from sklearn.svm import SVC 可以用于分类(Support Vector Classification)
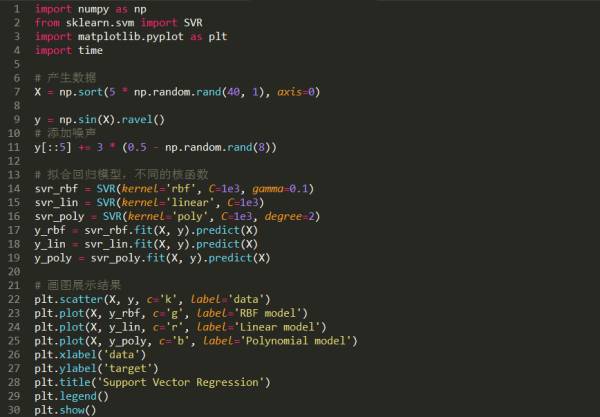
Support Vector Regression官网的一个简单例子。
http://scikit-learn.org/stable/auto_examples/svm/plot_svm_regression.html#example-svm-plot-svm-regression-py
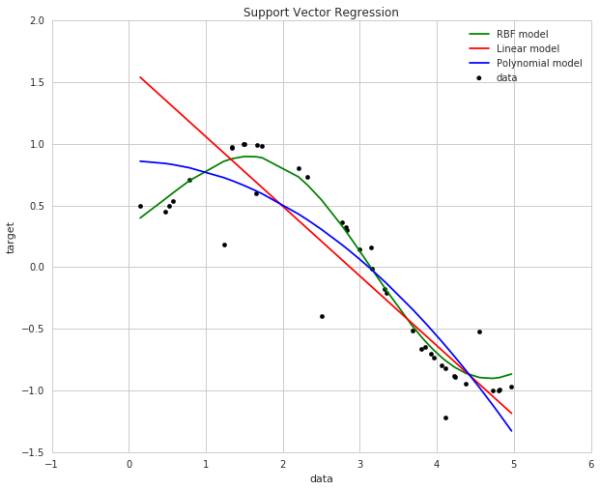
从回归的角度,可以根据之前的历史数据,预测下一个时间点的股价。
分类的角度,可以根据历史数据,预测下一个时间点股价的正负。
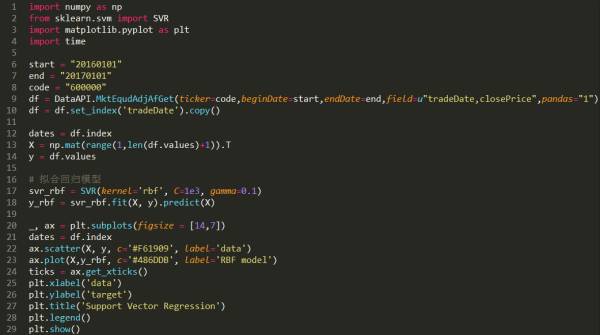
下面对股票数据进行回归建模。
特征选择
基本面因子:PE,PB,ROE等
技术指标因子:RSI、KDJ、MA、MACD等
蜡烛图形态因子:三乌鸦、锤子线等
输出
股价
股价涨跌分类
未来一段时间收益率
利用非监督学习甚至深度学习找到特征
比如找到大涨的股票,然后看大涨前一段时间的形态有没有相似的,利用非监督学习的方法。显然,这样的关系可能不是那么明显地存在于股票的价格中,可能存在于收益曲线中或者方差曲线中,甚至更高复杂度的统计量中。深度学习提供了将原数据投影到另一个特征空间中的方法,而且是高度非线性的。那么,原数据中没有体现出来的相关性,会不会在这种高度非线性的投影空间中体现出来呢?这个问题值思考。
SVR (Support Vector Regression)
SVR是SVM(Support Vector Machine)中的一个版本,可以用于解决回归问题。
 -0.192138249253
-0.192138249253
0.897470249992 4.88498130835e-17 1.0
array([[ 0.22282753, 0.25228758, 0.3448784 , 0.33066172], [ 0.26034535, 0.27540362, 0.24237401, 0.20206961]])
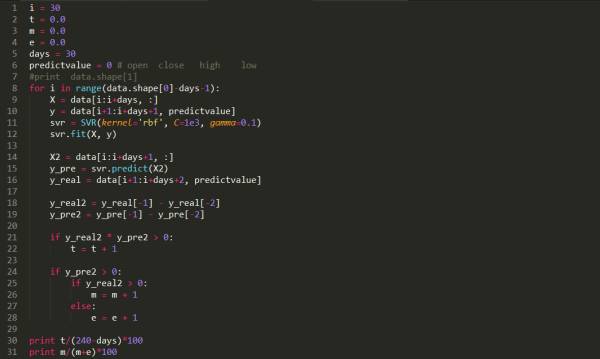
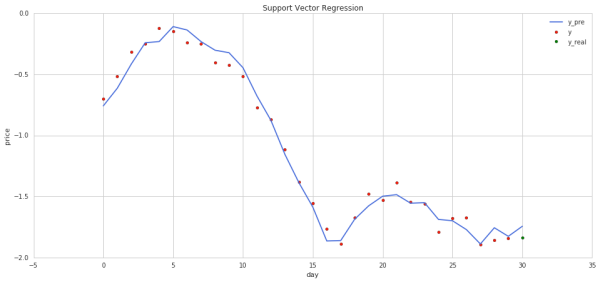
拟合与预测
假设i为1,days为30,
X:第i~i+days 天的开盘,收盘,最高,最低数据。
y:第i+1~i+days+1 天(对应的第二天)的开盘价。
X2:第i~i+days+1天的开盘,收盘,最高,最低数据。
yrep:第i+1~i+days+2天(对应的第二天)的预测开盘价。
yreal:第i+1~i+days+2天的开盘价。
yreal2:第i+days+2天的开盘价减第i+days+1天的开盘价。(真实趋势,大于0表示涨了)
yrep2:第i+days+2天的开盘价减第i+days+1天的预测开盘价。(预测趋势,大于0表示涨了)
同号相乘大于零,这里统计的是所有预测趋势的正确数量,预测涨和跌都算在里面了。
t:预测成功次数。
后面的两个if统计的是当预测为涨的时候,实际涨的次数和跌的次数。这个胜率只统计预测涨的成功率。
m:预测上涨,且真实情况上涨的次数。
e:预测上涨,但真实情况下跌的次数。
70.9523809524
66.3636363636
(结果还不错)
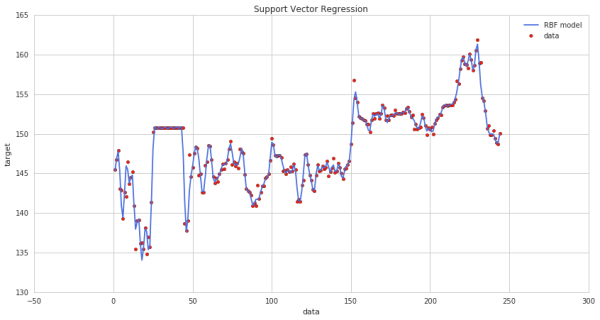
图中蓝线代表的是预测的走势,红点代表输入的训练集,绿点代表未来值,可以看到,蓝线最后一段的走势和红点很接近。
链接:https://zhuanlan.zhihu.com/p/24779083










