
“我听过AlphaGo很多传闻哈,第一步棋黑子的胜率为45%,白子的胜率为55%。所以我想在最后一天的比赛中仍然执白棋。”
文 | 宇多田
在这场三番棋比赛第二局进行到下午1点37分时,柯洁主动投子认输,台下观众一脸懵逼还没有反应过来(因为提前昨天很多时间),AlphaGo提前昨天近一个小时在中盘战胜柯洁。
这也基本意味着,这场三番棋大战以柯洁的认输而告终,不过27号将是柯洁有机会扳回一局的最后一战。

比赛结果
在这次比赛中,围棋国手古力、张璇(曾获得过中国冠军)、刘菁、周睿羊担当开局时段的解说员。
古力认为,在特别难判断的盘面上,AlphaGo比我们要思考地更加准确,也就是说从一步看未来几十步的“本事”。
从开局来看,柯洁想把时间多用在对布局的策略方面,而且在前十手时打的一直非常不错,盘面很稳,而且被预测赢面很大。柯洁甚至预料到AlphaGo多步棋的下子位置。
而反观AlphaGo,古力认为其开局表现跟人类无异,每一步下的都很平常,甚至很多步都被他预测到。
但是我们需要清楚,在前天进行的第一场比赛时,柯洁一开始的胜率其实也是非常高的,但越往后,AlphaGo的胜率就逐渐慢慢提高了。
比较有意思的是,从一开局柯洁二手点了三三后,AlphaGo又在左下角下了“三三”。这个位置很令人惊讶,因为古力解释一般棋手为了遵循礼仪都会下在左上角。而哈克比斯在赛后这样解释:
“对于AlphaGo来说,它根本分不清什么是左上角和右下角,在它眼里这些都一样。”
一开始,比赛的赛时也没有像昨天那样被拉开,对弈双方的时间差也一直维持在十几分钟左右。但随着战局的推进,柯洁扯头发的次数越来越多(头发越来越乱),面部的表情也越来越焦虑。
最终,让所有人都没有想到的是,开局2个多小时后,局面出现反转,柯洁变得力不从心,然后突然在下午1点37分主动投子认输,AlohaGo在中盘执黑子赢得胜利!随后进行了复盘。
在整个比赛过程中,古力曾着重分析了AlphaGo的厉害之处:
在判断大局的方面真的非常厉害,也就是在所谓的“虚着”(类似于声东击西,在围棋中很多时候都需要声东击西才能摆脱困境或者是翻盘)上更胜一筹。你看那些稀疏的地方我可能真的判断不好。
通俗来讲,就是在棋子比较密布的某一区块上面,我们谁能猜到AlphaGo的落子结果;但在盘面比较虚的地方,例如棋子稀疏的下方(如图),我们根本无法猜到。而AlphaGo就是在这种情况下,不知不觉地积累优势。
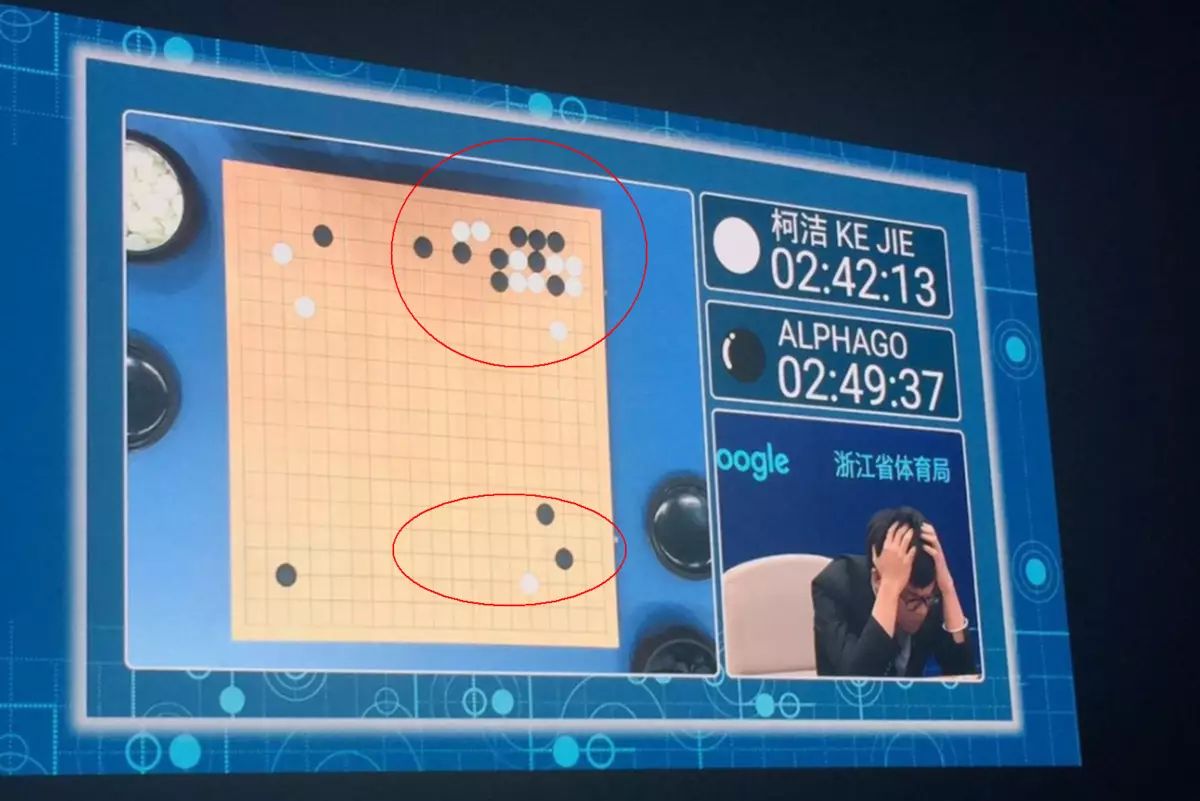
右上角是密集处。而在下方稀疏的地方,虚着的盘面很难判断
其实,早在AlphaGo与柯洁未开赛前,我们曾经提出一个脑洞大开的问题:AlphaGo会不会故意输给柯洁?
这个命题可以设定为存在两种情况:
第一个猜测被DeepMind创始人Demis以一个玩笑否认了:
这个建议太好了,看来我们以后也应该为AlphaGo安装一些传感器与摄像头。你要知道,AlphaGo一定是会有弱点的。而柯洁据说也通过分析AlphaGo掌握了一些它的套路,两位选手是势均力敌的。
而第二个猜测,的确是DeepMind持续提升AlphaGo能力的一个方向,但从目前来说,AlphaGo还做不到。
在在昨天的人工智能闭门大会上,DeepMind首席科学家Davis Silver已经非常清晰地解释了这个新一代AlphaGo的过人之处:
第2代“深度强化学习系统”AlphaGo Fan(共4代)共有12层卷积神经网络,而第4代AlphaGo(也就是与柯洁比赛的这一代)通过进行“自我学习”(监督学习与强化学习)已经训练出了40层神经网络(由策略网络与神经网络组成)。
在整个学习过程中,系统要对棋局进行图像扫描,分成无数个小块依次进行处理,最终构成整个全局观。具体来说,它可以近乎准确地判断棋盘上现有的棋子能给周围区域带来多大的影响力。
这个“全局观”,就是AlphaGo与人类最不一样的地方,也是古力在解说时特意强调的AlphaGo具备的一个能力:
策略网络,就是让AlphaGo先自己跟自己比,下个几万场,目的就是要“走对子”,选择最好的一步走,判断哪个策略最有效。
而在这个步骤结束后,继而形成价值网络,用来负责估算胜率。“策略网络”能够对所有落子位置进行概率分布,然后再将这些估算出的信息投入到蒙特卡罗搜索树中,推算出胜率最高的一些算法。
换句话说,就是每走出一步,价值网络就是通过这样的函数来预测未来的输赢,而不是静态地去考虑这步棋。
两者一前一后,就形成了AlphaGo的杀手锏——“在最后结果为‘赢’的前提下,去选择每一步最可行的路径”。
这也能解释为何AlphaGo在去年与李世石三番棋的第二局比赛中,狗的第37子被称为“牵一发而动全身”的一步棋。在赛后复盘后,人类棋手才发现这步棋完全决定了后面50步棋的下法。
照这样来看,层数越来越多的神经网络决定了AlphaGo学习的深度正在越来越大,这就相当于AlphaGo不管是在思考每一步策略,还是在判断胜率的精准度上都有了很大的提高。
但如果要故意“输给柯洁”,不仅需要AlphaGo的自我学习能力,还需要获得柯洁这位棋手足够多的数据,因为获得固定的胜率需要他去“揣摩”柯洁的直觉。
从理论上来说,如果AlphaGo能通过自我学习来掌握柯洁足够多的数据,是有可能控制胜率的(几率会更高)。

赛后发布会
而这个决定三番棋胜局的关键第二场比赛,柯洁的主动投子认输,虽然让我们再次见识到了AlphaGo的厉害之处,但柯洁的表现也十分惊艳。
在赛后的发布会上,DeepMind联合创始人兼CEO哈克比斯先生给了柯洁的开局表现一个极高的评价。他认为柯洁与AlphaGo的前15手,甚至在前100手的对弈中几乎是势均力敌的。
在前100步棋之前,哈克比斯就兴奋地发了一条Twitter称赞柯洁的高水平打法:
在第一盘到达“官子”的时候,AlphaGo让自己获胜的概率达到最大化,因此它要放弃一些点,其主要目的就是赢得比赛。但在这一场中,特别是在前100手,两者的差距非常小。因此,前半段双方赢得比赛的机会都非常大。
而且,这是AlphaGo打了这么多比赛以来,我觉得最势均力敌的一场比赛,柯洁的前半段表现真的十分完美。我发的Twtter也是这个意思,非常敬佩柯洁先生,他真的非常了不起”
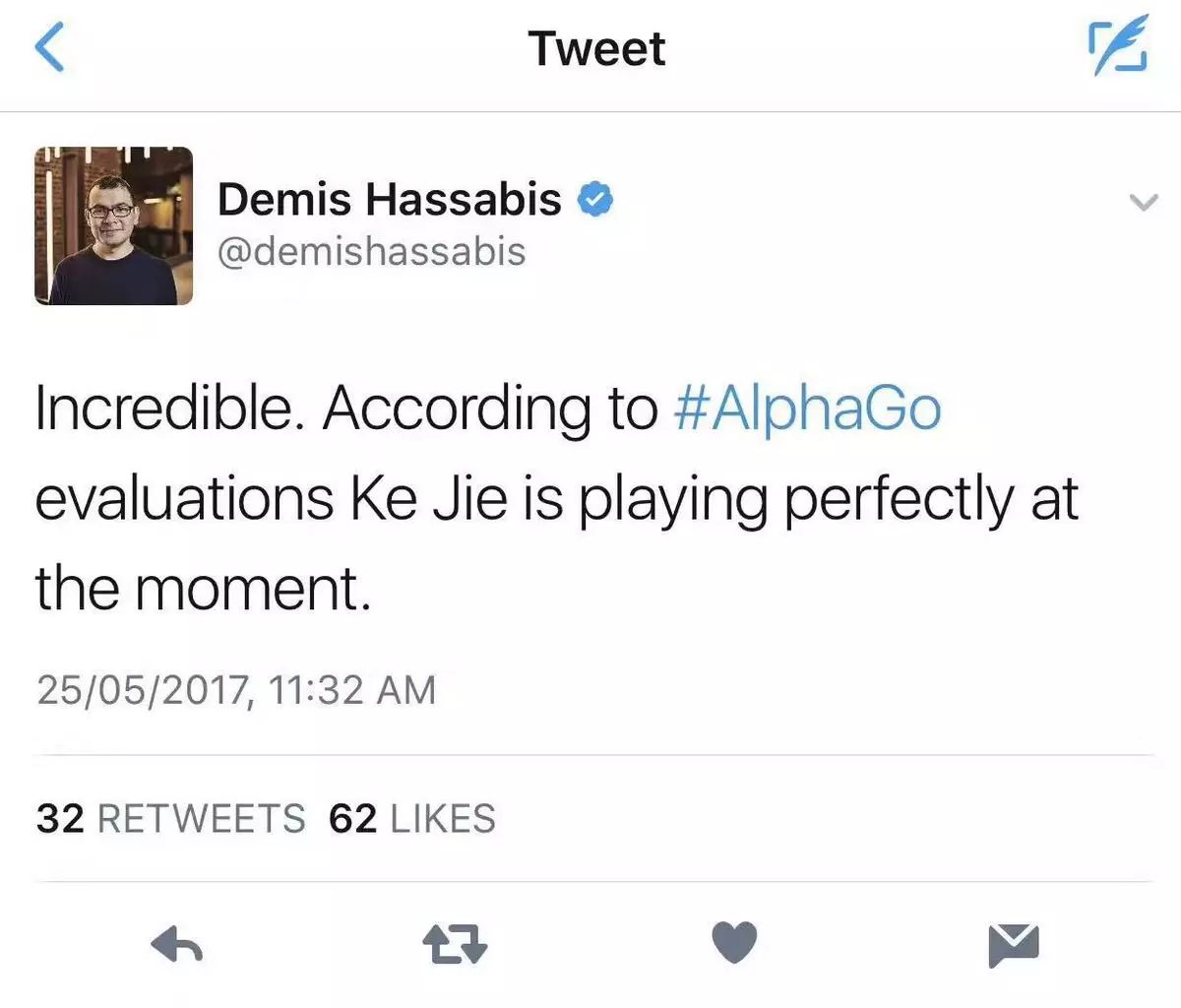
哈克比斯的Twitter
柯洁赛后的心情虽然看起来还不错,他认为自己的对决很棒,甚至一度以为自己接近了胜利,能战胜Alphago:
在中途时我以为自己离胜利很接近了,我难道快接近胜利了吗? 因此我才有了按心的动作。因为太紧张,后面又下了一些不好的棋。这一点我觉得有点遗憾。
但我认为自己发挥的挺好,我不认为我布局有什么差的地方。前半段很精彩,只是后半段有一个地方就突然松弛了下来。
我不喜欢安乐死,之后也会好好下,但这场真的很紧张。
柯洁也在最后幽默了一把,他觉得坐在对面的黄博士没什么人类感,就是一个AI机器人:
黄博士在我对面,就像一个AI一样。我想黄博士是看着AlphaGo从小长大的,因为他可能更了解AlphaGo。你们知道我比赛喜欢乱动,挠头发什么的。但黄博士却一动不动,甚至不喝水,不吃东西,真的像个机器人……我还是挺适应黄博士坐在对面的。

两位大神的签名(昨边的人为哈克比斯,右边的人为柯洁)
而DeepMind首席科学家David则又披露了更多关于新一代AlphaGo版本的技术细节:
“Master版本已经完全脱离了人类的训练,是完全靠自我对弈来实现训练的,它可以进行自我对弈,也弥补了去年与李世石对弈的第4局第67手时犯下的错误(弱点) 他会在不断的自我学习中寻找弱点,然后再自动修复这些弱点,因此你才看到了AlphaGo更加优秀的表现。”










