
本文简要介绍了
CVPR 2020
录用论文
“UnrealText:Synthesizing Realistic Scene Text Images from the Unreal World”的主要工作。论文针对场景文字检测和场景文字识别对数据量的需求以及对真实数据的依赖性,提出了一种基于虚拟引擎的场景文字数据合成方法(UnrealText)
,并提出了一个大规模的场景文字合成数据集,以提高场景文字检测器和识别器的性能。
在深度学习时代,场景文字检测和场景文字识别都取得了突破性的进展。但是,这些算法对数据的需求量非常大,而对于场景文字数据的标注成本很高,尤其是字符级别甚至是像素级别的标注,于是学者提出了许多合成数据的方法
[1][2][3]
。对于场景文字识别,这些合成数据是非常有效的,但是对于一些情况,例如模糊图片以及曲线文本并不能很好泛化。而场景文字检测非常依赖真实的数据,之前的合成数据并不是非常真实,对算法的提升并不是非常明显。因此,这篇文章提出一种基于虚拟引擎
4、从3D
视觉场景合成场景文字数据的方法
(UnrealText)
,它能让文本出现在更加合理的位置,合成更加真实的数据
(将自然场景下的亮度、光照等条件也考虑在内),并提出了一个大规模的场景文字合成数据集,该合成方法以及这些数据对检测器和识别器的性能都有比较高的提升。图1是UnrealText的合成数据的示例。

UnrealText的数据合成可以分为四个步骤:A.
场景搜索;
B.环境初始化;C.文本区域生成;D.文本数据合成。图2则是UnrealText的方法框图。
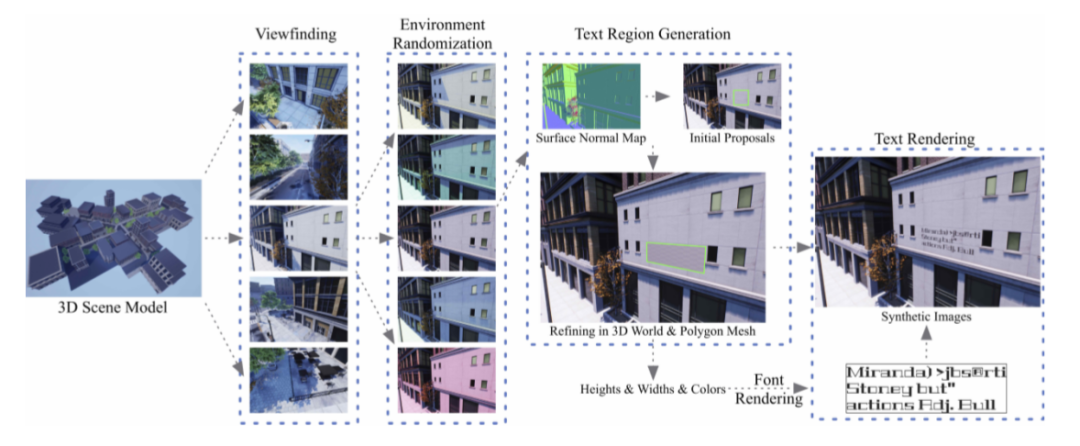
场景搜索
(
V
iewfinding
):
其目标是能从图
2的3D
场景模型中自动寻找到合理的场景视角
(Camera Viewpoints)
。本文中作者设计了一种搜索方法
:基于Auxiliary Camera Anchors的Physically-Constrained 3D Random Walk
。
Physically-Constrained 3D Random Walk
是通过不断的迭代从
3D
场景模型中选取有效而且合适的位置作为合成数据的背景,在每次迭代过程中,首先随机改变
3D
模型的俯仰和偏航参数
(Pitch And Yaw Values)
以得到一个新的位置视角,然后从相机的位置向视角的方向投射光线并得到一条路径,最后在该路径的
1/3
到
2/3
处随机采样一个点作为新的位置点。为了提高搜索方法的效率,作者预设了
N个Camera Anchors作为开始点。图3
为
Physically-Constrained 3D Random Walk
的流程示意图。

环境初始化(
Environment Randomization
)
:
对场景搜索得到的合适合理的背景进行环境初始化,包括亮度、颜色以及雾条件等,以得到在不同环境条件下的背景图片。
文本区域生成(
Text Region Generation
)
:为了将文本合成到合适的位置,作者提出了一个两阶段的Pipeline:
首先通过检索背景的
Surface Normal Map以初始化有效的文本区域,检索是通过64×64
的滑窗并根据任意像素之间余弦相似度去判断是否为有效区域;初始化得到的有效区域是水平矩形,之后通过一个微调的过程
(Refine)能去得到任意四边形的目标文本区域以提供给后续合成,微调的过程如图4所示。该微调过程首先将初始化的区域映射回原3D
场景模型并得到类似于图
4(2)的Front View,然后根据Front View中旋转的区域重新初始化得到图4(3)的正交矩形,之后映射回原生成背景,并交替增大该区域的宽和高以得到微调后的目标文本区域。

文本数据合成(
Text Rendering
)
:
给定了背景和相应的文本区域,这一步将与文本区域尺寸相适应的文本行合成到目标区域当中,从而得到最终的合成数据。为了后续实验公平的对比,文本字体的来源与
SynthText[1]
一致,均来自
Google Fonts。
本文通过UnrealText合成了一批场景文字检测和识别的数据并验证了该合成方法的有效性。
1. 对
于场景文字检测,作者使用了EAST[4]作为检测器,在ICDAR 2013, ICDAR 2015以及MLT 2017上验证了UnrealText合成数据在检测上的有效性。
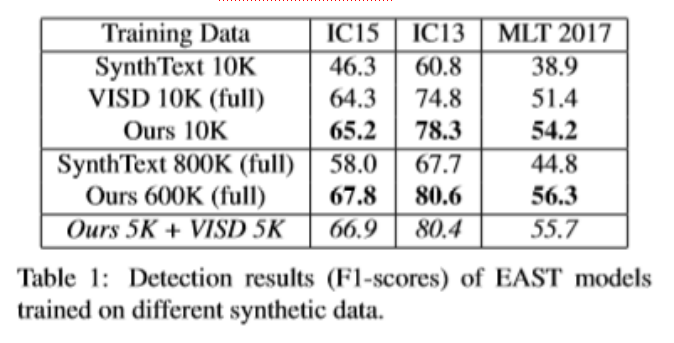
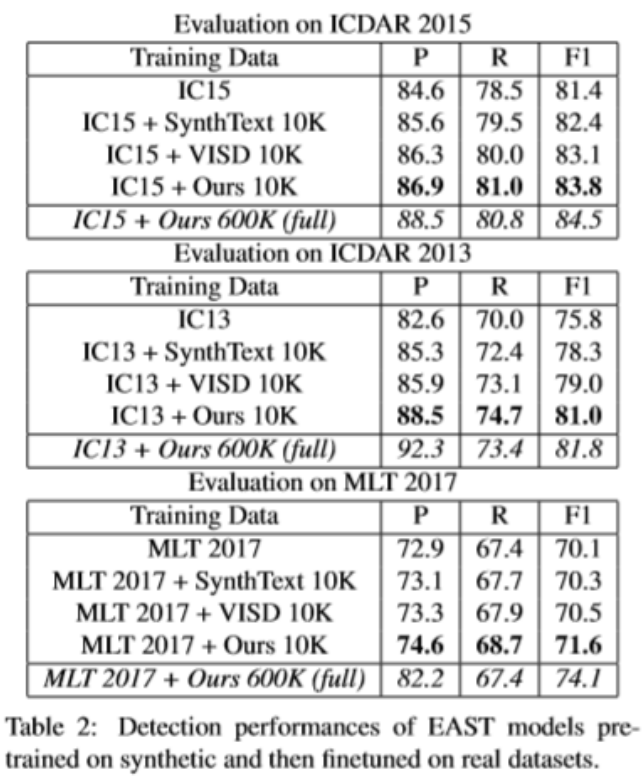
Table 1是只在合成数据上训练,然后在三个不同的基准数据集上测得的结果.而Table 2则是在各自数据集加上不同的合成数据集下得到的结果,可以看出用UnrealText合成的数据对于检测器的训练,比起其他方式合成数据所得到的效果要好很多。
2.
对于场景文字识别,作者使
用了ASTER[5]作为识别模型,在MLT 2017多语种识别数据集以及各常用英文识别数据集上也验证了UnrealText在识别上的有效性。
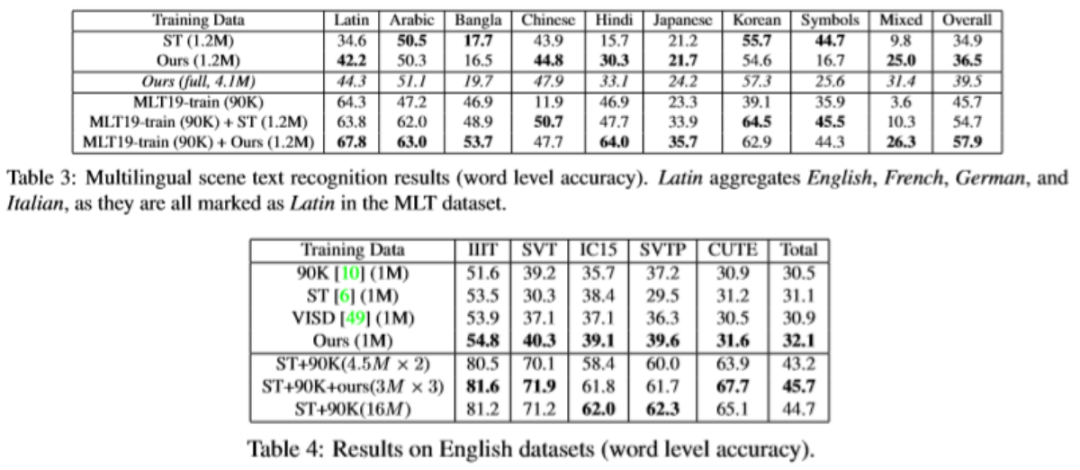
Ta
ble 3和4分别验证了作者提出的UnrealText用于多语种识别上和常规英文识别上的提升。
该论文提出一种基于虚拟引擎4、从3D视觉场景合成场景文字数据的方法(UnrealText),它能合成更加真实的数据,同时也提出了一个大规模的场景文字合成数据集,该合成方法以及这些数据对检测器和识别器的性能都有比较高的提升。这是对场景文本数据合成的进一步探索,怎么去合成更加真实的数据,去更好的提高算法的性能并更好的降低人工标注的成本,依旧是个主要的问题,值得我们探索和深究。
[
1] Fangneng Zhan, Shijian Lu, and Chuhui Xue. Verisimilar image synthesis for accurate detection and recognition of texts in scenes. In Proc. ECCV, 2018.
[2] Ankush Gupta, Andrea Vedaldi, and Andrew Zisserman. Synthetic data for text localization in natural images. In Proc. CVPR, pages 2315–2324, 2016.
[
3] Max Jaderberg, Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Synthetic data and artificial neural networks for natural scene text recognition. In NIPS, 2014.
[
4] Xinyu Zhou, Cong Yao, He Wen, Yuzhi Wang, Shuchang Zhou, Weiran He, and Jiajun Liang. EAST: An efficient and accurate scene text detector. In Proc. CVPR, 2017.
[
5] Baoguang Shi, Mingkun Yang, XingGang Wang, Pengyuan Lyu, Xiang Bai, and Cong Yao. Aster: An attentional scene text recognizer with flexible rectification. IEEE transactions on pattern analysis and machine intelligence, 31(11):855– 868, 2018.
原文作者:
Shangbang Long
,
Cong Yao


