作者 | 陈迪豪
责编 | 何永灿
机器学习与人工智能,相信大家已经耳熟能详,随着大规模标记数据的积累、神经网络算法的成熟以及高性能通用GPU的推广,深度学习逐渐成为计算机专家以及大数据科学家的研究重点。近年来,无论是图像的分类、识别和检测,还是语音生成、自然语言处理,甚至是AI下围棋或者打游戏都基于深度学习有了很大的突破。而随着TensorFlow、Caffe等开源框架的发展,深度学习的门槛变得越来越低,甚至初中生都可以轻易实现一个图像分类或者自动驾驶的神经网络模型,但目前最前沿的成果主要还是出自Google、微软等巨头企业。
Google不仅拥有优秀的人才储备和大数据资源,其得天独厚的基础架构也极大推动了AI业务的发展,得益于内部的大规模集群调度系统Borg,开发者可以快速申请大量GPU资源进行模型训练和上线模型服务,并且通过资源共享和自动调度保证整体资源利用率也很高。Google开源了TensorFlow深度学习框架,让开发者可以在本地轻易地组合MLP、CNN和RNN等模块实现复杂的神经网络模型,但
TensorFlow只是一个数值计算库,并不能解决资源隔离、任务调度等问题,将深度学习框架集成到基于云计算的基础架构上将是下一个关键任务。
除了Google、微软,国内的百度也开源了PaddlePaddle分布式计算框架,并且官方集成了Kubernetes等容器调度系统,用户可以基于PaddlePaddle框架实现神经网络模型,同时利用容器的隔离性和Kubernetes的资源共享、自动调度、故障恢复等特性,但平台不能支持更多深度学习框架接口。而亚马逊和腾讯云相继推出了面向开发者的公有云服务,可以同时支持多种主流的开源深度学习框架,阿里、金山和小米也即将推出基于GPU的云深度学习服务,还有无数企业在默默地研发内部的机器学习平台和大数据服务。
面对如此眼花缭乱的云服务和开源技术,架构师该如何考虑其中的技术细节,从用户的角度又该如何选择这些平台或者服务呢。
我将介绍小米云深度学习平台的架构设计与实现细节,希望能给AI领域的研发人员提供一些思考和启示。
云深度学习平台,我定义为Cloud Machine Learning
,就是基于云计算的机器学习和深度学习平台。首先TensorFlow、MXNet是深度学习框架或者深度学习平台,但并不是云深度学习平台,它们虽然可以组成一个分布式计算集群进行模型训练,但需要用户在计算服务器上手动启动和管理进程,并没有云计算中任务隔离、资源共享、自动调度、故障恢复以及按需计费等功能。因此我们需要区分深度学习类库以及深度学习平台之间的关系,而这些类库实现的随机梯度下降和反向传播等算法却是深度学习应用所必须的,这是一种全新的编程范式,需要我们已有的基础架构去支持。
云计算和大数据发展超过了整整十年,在业界催生非常多优秀的开源工具,如实现了类似AWS IaaS功能的OpenStack项目,还有Hadoop、Spark、Hive等大数据存储和处理框架,以及近年很火的Docker、Kubernetes等容器项目,这些都是构建现代云计算服务的基石。这些云服务有共同的特点,例如我们使用HDFS进行数据存储,用户不需要手动申请物理资源就可以做到开箱即用,用户数据保存在几乎无限制的公共资源池中,并且通过租户隔离保证数据安全,集群在节点故障或者水平扩容时自动触发Failover且不会影响用户业务。虽然Spark通过MLib接口提供部分机器学习算法功能,但绝不能替代TensorFlow、Caffe等深度学习框架的作用,因此
我们仍需要实现Cloud Machine Learning服务,并且确保实现云服务的基本特性
——我将其总结为下面几条:
-
屏蔽硬件资源保证开箱即用
-
缩短业务环境部署和启动时间
-
提供“无限”的存储和计算能力
-
实现多租户隔离保证数据安全
-
实现错误容忍和自动故障迁移
-
提高集群利用率和降低性能损耗
相比于MapReduce或者Spark任务,深度学习的模型训练时间周期长,而且需要调优的超参数更多,
平台设计还需要考虑以下几点
:
-
支持通用GPU等异构化硬件
-
支持主流的深度学习框架接口
-
支持无人值守的超参数自动调优
-
支持从模型训练到上线的工作流
这是我个人对云深度学习平台的需求理解,也是小米在实现cloud-ml服务时的基本设计原则。虽然涉及到高可用、分布式等颇具实现难度的问题,但借助目前比较成熟的云计算框架和开源技术,我们的架构和实现基本满足了前面所有的需求,当然如果有更多需求和想法欢迎随时交流。
遵循前面的平台设计原则,我们的系统架构也愈加清晰明了,为了满足小米内部的所有深度学习和机器学习需求,需要有一个多租户、任务隔离、资源共享、支持多框架和GPU的通用服务平台。通过实现经典的MLP、CNN或RNN算法并不能满足业务快速发展的需求,因此我们需要支持TensorFlow等用户自定义的模型结构,并且支持高性能GPU和分布式训练是这个云深度学习平台的必须功能,不仅仅是模型训练,我们还希望集成模型服务等功能来最大化用户的使用效益。
计算机领域有句名言“任何计算机问题都可以通过增加一个中间层来解决”。
无论是AWS、OpenStack、Hadoop、Spark还是TCP/IP都是这样做的,通过增加一个抽象层来屏蔽底层资源,对上层提供更易用或者更可靠的访问接口。小米的cloud-ml平台也需要实现对底层物理资源的屏蔽,尤其是对GPU资源的抽象和调度,但我们不需要重新实现,因为社区已经有了很多成熟的分布式解决方案,如OpenStack、Yarn和Kubernetes。目前OpenStack和Yarn对GPU调度支持有所欠缺,虚拟机也存在启动速度慢、性能overhead较大等问题,而容器方案中的Kubernetes和Mesos发展迅速,支持GPU调度等功能,是目前最值得推荐的架构选型之一。
目前小米cloud-ml平台的任务调度和物理机管理基于多节点的分布式Kubernetes集群,对于OpenStack、Yarn和Mesos我们也保留了实现接口,可以通过实现Mesos后端让用户的任务调度到Mesos集群进行训练,最终返回给用户一致的使用接口。目前Kubernetes最新稳定版是1.6,已经支持Nvidia GPU的调度和访问,对于其他厂商GPU暂不支持但基本能满足企业内部的需求,而且Pod、Deployment、Job、StatefulSet等功能日趋稳定,加上Docker、Prometheus、Harbor等生态项目的成熟,已经在大量生产环境验证过,可以满足通用PaaS或者Cloud Machine learning等定制服务平台的需求。
使用Kubernetes管理用户的Docker容器,还解决了资源隔离的问题,保证不同深度学习训练任务间的环境不会冲突,并且可以针对训练任务和模型服务使用Job和Deployment等不同的接口,充分利用分布式容器编排系统的重调度和负载均衡功能。但是,Kubernetes并没有完善的多租户和Quota管理功能,难以与企业内部的权限管理系统对接,这要求我们对Kubernetes API进行再一次“抽象”。我们通过API Server实现了内部的AKSK签名和认证授权机制,在处理用户请求时加入多租户和Quota配额功能,并且对外提供简单易用的RESTful API,进一步简化了整个云深度学习平台的使用流程,整体架构设计如图1。
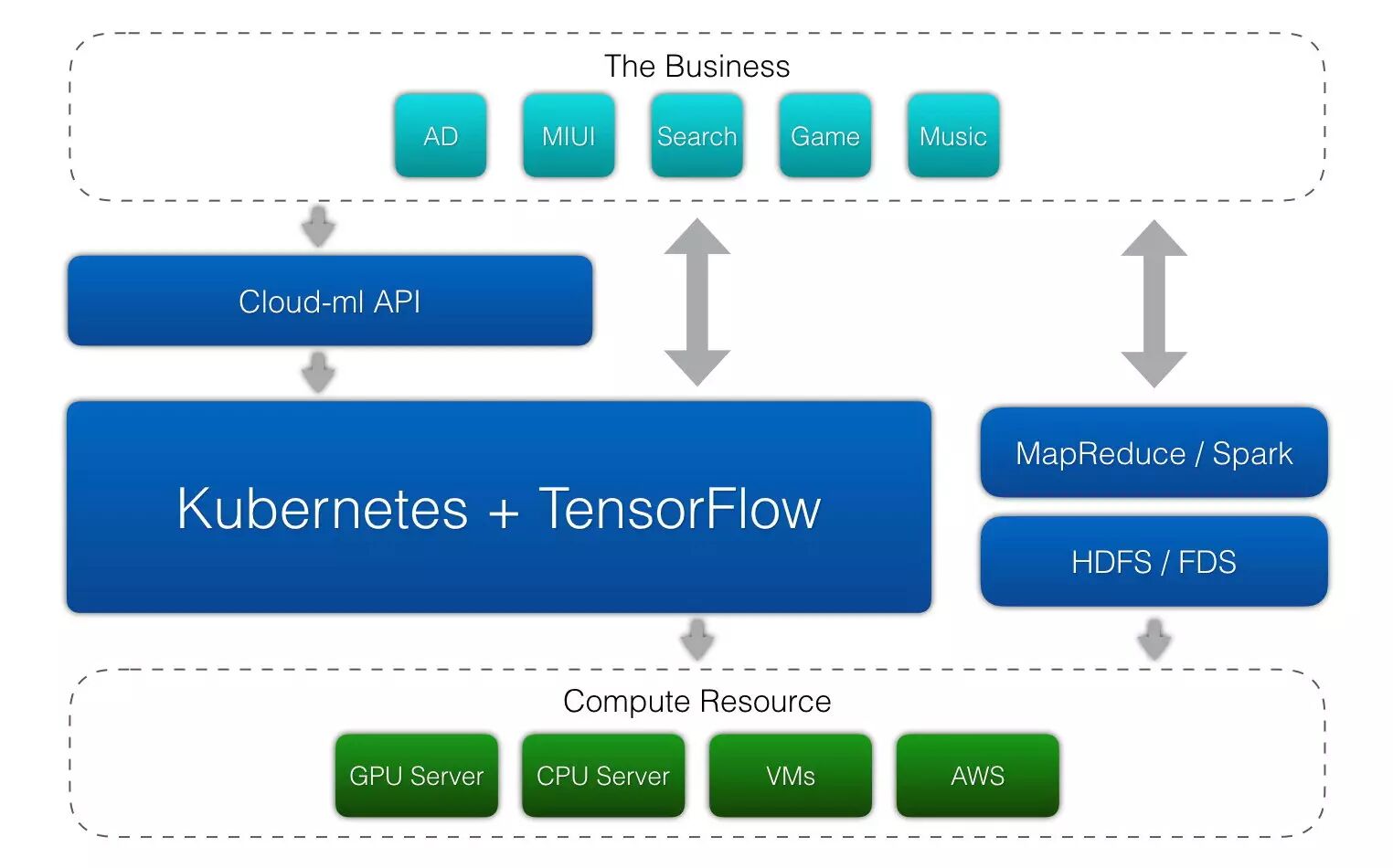
图1 云深度学习平台整体架构
通过实现API Server,我们对外提供了API、SDK、命令行以及Web控制台多种访问方式,最大程度上满足了用户复杂多变的使用环境。集群内置了Docker镜像仓库服务,托管了我们支持的17个深度学习框架的容器镜像,让用户不需要任何初始化命令就可以一键创建各框架的开发环境、训练任务以及模型服务。多副本的API Server和Etcd集群,保证了整个集群所有组件的高可用,和Hadoop或者Spark一样,我们的cloud-ml服务在任意一台服务器经历断网、宕机、磁盘故障等暴力测试下都能自动Failover保证业务不受任何影响。
前面提到,我们通过抽象层定义了云深度学习平台的接口,无论后端使用Kubernetes、Mesos、Yarn甚至是OpenStack、AWS都可以支持。通过容器的抽象可以定义任务的运行环境,目前已经支持17个主流的深度学习框架,用户甚至可以在不改任何一行代码的情况下定义自己的运行环境或者使用自己实现的深度学习框架。在灵活的架构下,我们还实现了分布式训练、超参数自动调优、前置命令、NodeSelector、Bring Your Own Image和FUSE集成等功能,将在下面逐一介绍。
前面提到我们后端使用Kubernetes编排系统,通过API Server实现授权认证和Quota配额功能。由于云深度学习服务是一个计算服务,和我以前做过的分布式存储服务有着本质的区别,计算服务离线运算时间较长,客户端请求延时要求较低而且吞吐很小,因此我们的API服务在易用性和高性能上可以选择前者,目前主流的Web服务器都可以满足需求。基于Web服务器我们可以实现集成内部权限管理系统的业务逻辑,小米生态云提供了类似AWS的AKSK签名认证机制,用户注册登录后可以自行创建Access key和Secret key,请求时在客户端进行AKSK的签名后发送,这样用户不需要把账号密码或密钥加到请求中,即使密钥泄露也可以由用户来禁用,请求时即使签名被嗅探也只能重放当前的请求内容,是非常可靠的安全机制。除此之外,我们参考OpenStack项目的体系架构,实现了多租户和Quota功能,通过认证和授权的请求需要经过Quota配额检查,在高可用数据库中持久化相应的数据,这样平台管理员就可以动态修改每个租户的Quota,而且用户可以随时查看自身的审计信息。
小米cloud-ml服务实现了深度学习模型的开发、训练、调优、测试、部署和预测等完整功能,都是通过提交到后
端的Kubernetes集群来实现,完整的功能介绍可以查看官方文档
http://docs.api.xiaomi.com/cloud-ml/
。Kubernetes对外提供了RESTful API访问接口,通过YAML或者JSON来描述不同的任务类型,不同编程语言实现的系统也可以使用社区开发的SDK来访问。对于我们支持的多个深度学习框架,还有开发环境、训练任务、模型服务等功能,都需要定制Docker镜像,提交到Kubernetes时指定使用的容器镜像、启动命令等参数。通过对Kubernetes API的封装,我们可以简化Kubernetes的使用细节,保证了对Mesos、Yarn等后端支持的兼容性,同时避免了直接暴露Kubernetes API带来的授权问题以及安全隐患。
除了可以启动单个容器执行用户的训练代码,小米cloud-ml平台也支持TensorFlow的分布式训练,使用时只需要传入ps和worker个数即可。考虑到对TensorFlow原生API的兼容性,我们并没有定制修改TensorFlow代码,用户甚至可以在本地安装开源的TensorFlow测试后再提交,同样可以运行在云平台上。但本地运行分布式TensorFlow需要在多台服务器上手动起进程,同时要避免进程使用的端口与其他服务冲突,而且要考虑系统环境、内存不足、磁盘空间等问题,代码更新和运维压力成倍增加,Cloud Machine Learning下的分布式TensorFlow只需要在提交任务时多加两个参数即可。有人觉得手动启动分布式TensorFlow非常繁琐,在云端实现逻辑是否更加复杂?其实并不是,通过云服务的控制节点,我们在启动任务前就可以分配不会冲突的端口资源,启动时通过容器隔离环境资源,而用户不需要传入Cluster spec等繁琐的参数,我们遵循Google CloudML标准,会自动生成Cluster spec等信息通过环境变量加入到容器的启动任务中。这样无论是单机版训练任务,还是几个节点的分布式任务,甚至是上百节点的分布式训练任务,cloud-ml平台都可以通过相同的镜像和代码来运行,只是启动时传入的环境变量不同,在不改变任何外部依赖的情况下优雅地实现了看似复杂的分布式训练功能。
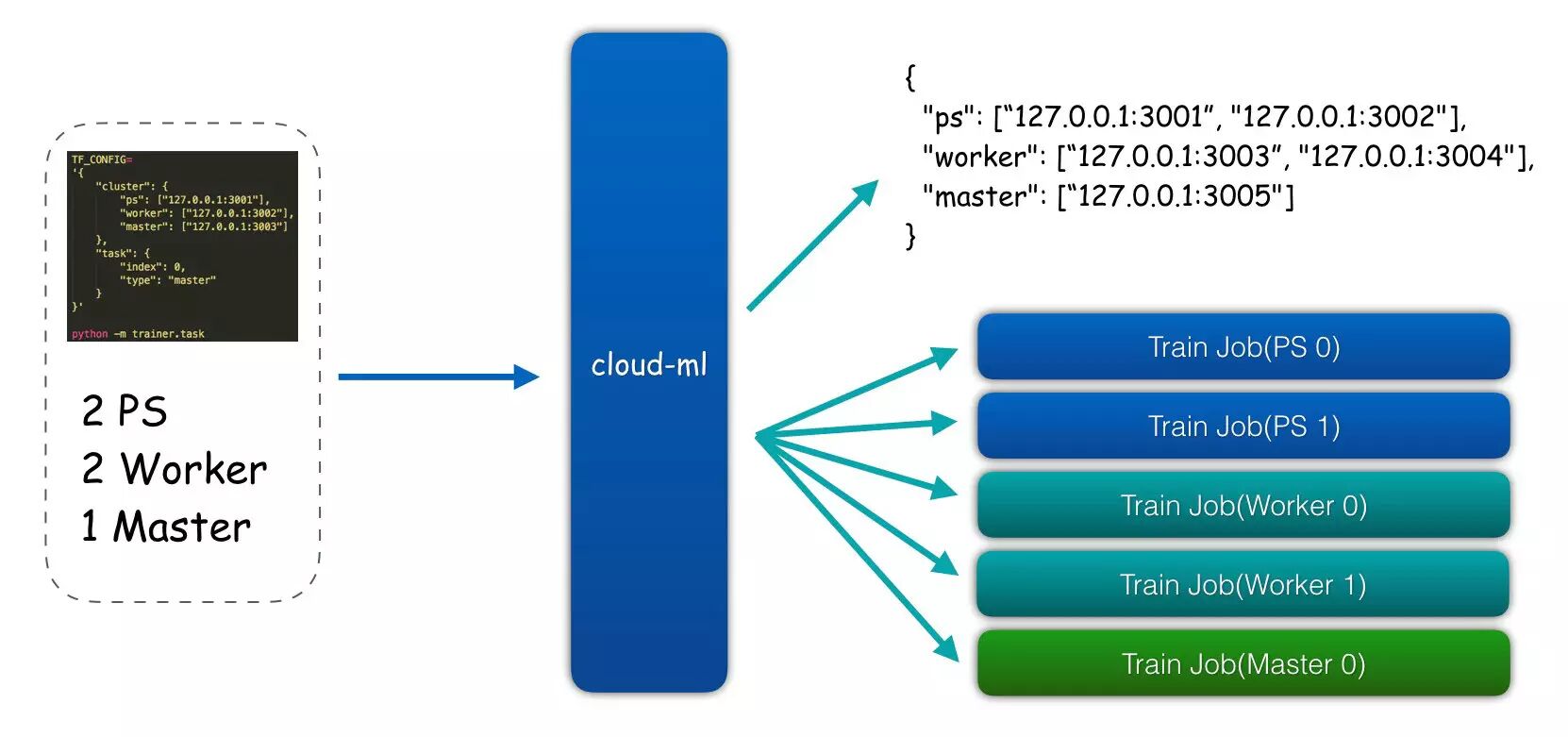
图2 云深度学习平台分布式训练
看到这里大家可能认为,小米的cloud-ml平台和Google的CloudML服务,都有点类似之前很火的PaaS(Platform as a Service)或者CaaS(Container as a Service)服务。确实如此,基于Kubernetes或者Mesos我们可以很容易实现一个通用的CaaS,用户上传应用代码和Docker镜像,由平台调度和运行,但不同的是Cloud Machine Learning简化了与机器学习无关的功能。我们不需要用户了解PaaS的所有功能,也不需要支持所有编程语言的运行环境,暴露提交任务、查看任务、删除任务等更简单的使用接口即可,而要支持不同规模的TensorFlow应用代码,用户需要以标准的Python打包方式上传代码。Python的标准打包方式独立于TensorFlow或者小米cloud-ml平台,幸运的是目前Google CloudML也支持Python的标准打包方式,通过这种标准接口,我们甚至发现Google CloudML打包好的samples代码甚至可以直接提交到小米cloud-ml平台上训练。这是非常有意思的尝试,意味着用户可以使用原生的TensorFlow接口来实现自己的模型,在本地计算资源不充足的情况下可以提交到Google CloudML服务上训练,同时可以一行代码不用改直接提交到小米或者其他云服务厂商中的云平台上训练。如果大家在实现内部的云深度学习平台,不妨也参考下标准的Python打包方式,这样用户同一份代码就可以兼容所有云平台,避免厂商绑定。
除了训练任务,Cloud Machine Learning平台最好也能集成模型服务、开发环境等功能。对于模型服务,TensorFlow社区开源了TensorFlow Serving项目,可以加载任意TensorFlow模型并且提供统一的访问接口,而Caffe社区也提供了Web demo项目方便用户使用。目前Kubernetes和Mesos都实现了类似Deployment的功能,通过制作TensorFlow Serving等服务的容器镜像,我们可以很方便地为用户快速启动对应的模型服务。通过对Kubernetes API的封装,我们在暴露给用户API时也提供了replicas等参数,这样用户就可以直接通过Kubernetes API来创建多副本的Deployment实例,并且由Kubernetes来实现负载均衡等功能。除此之外,TensorFlow Serving本身还支持在线模型升级和同时加载多个模型版本等功能,我们在保证TensorFlow Serving容器正常运行的情况下,允许用户更新分布式对象存储中的模型文件就可以轻易地支持在线模型升级的功能。
对于比较小众但有特定使用场景的深度学习框架,Cloud Macine Learning的开发环境、训练任务和模型服务都支持Bring Your Own Image功能,也就是说用户可以定制自己的Docker镜像并在提交任务时指定使用。这种灵活的设置极大地降低了平台管理者的维护成本,我们不需要根据每个用户的需求定制通用的Golden image,事实上也不可能有完美的镜像可以满足所有需求,用户不同的模型可能有任意的Python或者非Python依赖,甚至是自己实现的私有深度学习框架也可以直接提交到Cloud Machine Learning平台上训练。内测BYOI功能时,我们还惊喜地发现这个功能对于我们开发新的深度学习框架支持,以及提前测试镜像升级有非常大的帮助,同时用户自己实现的Caffe模型服务和XGBoost模型服务也可以完美支持。
当然Cloud Machine Learning平台还可以实现很多有意思的功能,例如通过对线上不同GPU机型打label,通过NodeSelector功能可以允许用户选择具体的GPU型号进行更细粒度的调度,这需要我们暴露更底层Kubernetes API实现,这在集群测试中也是非常有用的功能。而无论是基于GPU的训练任务还是模型服务,我们都制作了对应的CUDA容器镜像,通过Kubernetes调度到对应的GPU计算节点就可以访问本地图像处理硬件进行高性能运算了。小米cloud-ml还开放了前置命令和后置命令功能,允许用户在启动训练任务前和训练任务结束后执行自定义命令,对于不支持分布式存储的深度学习框架,可以在前置命令中挂载S3 fuse和FDS fuse到本地目录,或者初始化HDFS的Kerberos账号,灵活的接口可以实现更多用户自定义的功能。还有超参数自动调优功能,与Google CloudML类似,用户可以提交时指定多组超参数配置,云平台可以自动分配资源起多实例并行计算,为了支持读取用户自定义的指标数据,我们实现了类似TensorBoard的Python接口直接访问TensorFlow event file数据,并通过命令行返回给用户最优的超参数组合。最后还有TensorFlow Application Template功能,在Cloud Machine Learning平台上用户可以将自己的模型代码公开或者使用官方维护的开源TensorFlow应用,用户提交任务时可以直接指定这些开源模板进行训练,模板已经实现了MLP、CNN、RNN和LR等经典神经网络结构,还可以通过超参数来配置神经网络每一层的节点数和层数,而且可以支持任意稠密和稀疏的数据集,这样不需要编写代码就可以在云平台上训练自己的数据快速生成AI模型了。
在前面的平台设计和平台架构后,要实现完整的云深度学习服务并不困难,尤其是集成了Docker、Etcd、Kubernetes、TensorFlow等优秀开源项目,组件间通过API松耦合地交互,需要的重复工作主要是打通企业内部权限系统和将用户请求转化成Kubernetes等后端请求而已,而支持标准的打包方式还可以让业务代码在任意云平台上无缝迁移。
目前小米云深度学习平台已经在内部各业务部门推广使用,相比于直接使用物理机,云服务拥有超高的资源利用率、快速的启动时间、近乎“无限”的计算资源、自动的故障迁移、支持分布式训练和超参数自动调优等优点,相信可以得到更好的推广和应用。
除了完成上述的功能,我们在实践时也听取了用户反馈进行改进。例如有内部用户反馈,在云端训练的TensorFlow应用把event file也导出到分布式存储中,使用TensorBoard需要先下载文件再从本地起服务相对麻烦,因此我们在原有基础架构实现了TensorboardService功能,可以一键启动TensorBoard服务,用户只需要用浏览器就可以打开使用。








