公众号ID
|
计算机视觉研究院
学习群
|
扫码在主页获取加入方式

地址:
https://github.com/all-things-vits/code-samples
Column of Computer Vision Institute
注意力机制已经彻底改变了许多学科的深度学习研究,从NLP开始,扩展到视觉、
语言
等
。
与其他机制不同,elegant和一般的注意力机制很容易适应,并消除了特定模态的感应偏见。随着
注意力
越来越受欢迎,开发工具让研究人员能够理解和解释机制的内部运作,以促进更好、更负责任地使用它,这一点至关重要。

今天分享的侧重于在视觉和多模态环境中理解和解释注意力。我们介绍了关于表征探索、可解释性和基于注意力的语义指导的最新研究,以及促进互动的实践演示。此外,我们还讨论了最近工作中出现的悬而未决的问题和未来的研究方向。
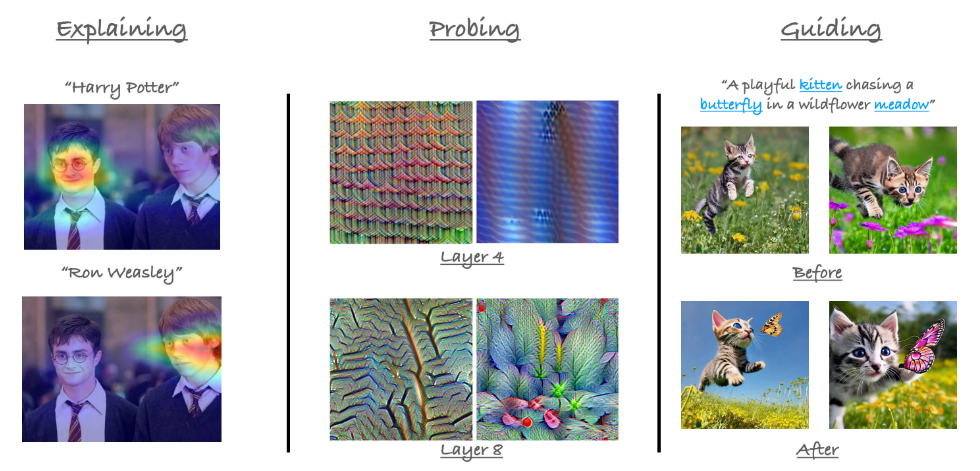
在今天分享中,我们将探讨注意力在视觉中的应用。从左到右:(i)注意力可用于解释模型的预测(例如,图像-文本对的CLIP)(ii)基
于注意力的探索模型的示例(iii)多模态模型的交叉注意力图可用于指导生成模型(例如,
mitigating neglect in Stable Diffusion
)。
以下是我们介绍的主题的概述。详细说明见本文件。
https://docs.google.com/document/d/1AHYQyi5rvTGZC8kKS1TEOMewl5_b1M6gHrTyUt38oFs/edit#heading=h.4fa4qoz6sg55
Interpreting Attention
-
Brief history of interpretability for DNNs
-
Attention vs. Convolutions
-
Using attention as an explanation
Probing Attention
Leveraging Attention as Explanation
References
[1]
Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers,
Chefer et al.
[2]
Do Vision Transformers See Like Convolutional Neural Networks?,
Raghu et al.
[3]
What do Vision Transformers Learn? A Visual Exploration,
Ghiasi et al.
[4]
Quantifying Attention Flow in Transformers,
Abnar et al.
[5]
Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models,
Chefer et al.
[6]
Prompt-to-Prompt Image Editing with Cross-Attention Control,
Hertz et al.
[7]
NULL-text Inversion for Editing Real Images using Guided Diffusion Models,
Mokady et al.
转载请联系本公众号获得授权
计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
VX:2311123606










