
让大家在网上看到消息的时候,如果有一个地方查一查、问一问,就能让这个世界更加真实,所以我把这个伪造检测的工具公布出来了。
曹娟 · 中国科学院计算技术研究所研究员
格致论道第 78 期 | 2022 年 03 月 26 日 北京
大家好,我是曹娟,来自中科院计算所。我研究的方向和大家的生活息息相关,是互联网上的虚假新闻检测。
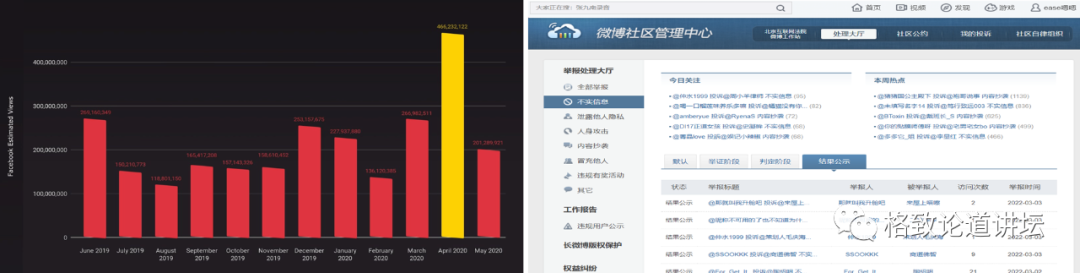
左:AVAAZ《Facebook's Algorithm: A Major Threat to Public Health》右:2021 年度微博辟谣数据报告
在现在的互联网上,让人一惊一乍的谣言实在是太多了。根据统计,Facebook 上 82 家不实信息源的年浏览量达到了 38 亿;在中国,2021 年度微博共有效处理不实信息 6 万多条。
大家有没有觉得,我们每天都在跟谣言斗智斗勇。尤其在重大事件发生的时候,谣言更像炸弹一样,来势凶猛。每当这个时候,我都特别地忙,因为身边的朋友、同学、领导都会纷纷发来信息,让我去求证:曹娟,你看这条信息是真的假的?同学群为了某件事发生争吵的时候,他们就会@我出来:曹娟,你来看一下这个东西是不是假的?
我真的非常的感谢每一位给我发来求证信息的人,是你们的需要,让我觉得这份工作特别的有价值、有意义。
言归正传,回到我们的话题:为什么现在互联网上的谣言这么多呢?其实谣言从古至今都有,而且它的破坏力一点儿都不亚于今天的谣言。
让我们回到两千年前的西周。当时年幼的周成王继位,由他的叔叔周公摄政辅助。但是另外一个叔叔管叔非常妒忌,他就四处散布谣言:“周公要夺位了!周公要夺位了!”流言可畏,周公就被赶走了,但其实想要夺位的恰恰是管叔。这件事就是白居易诗里面所写到的“周公恐惧流言日”。
但这是古代的谣言,再怎么厉害也只能口口相传,它的传播力是有限的。现在互联网出现了,随便一条新闻就可以影响到成千上万的人。
比如大家是不是经常看到这样的消息:水果要空腹才能吃,吃了醋会导致骨质疏松……这些新闻最后都被证实是假的。这样的文字新闻很容易就可以发布,造谣的成本很低。所以大家会想:文字都不靠谱,要有图才能有真相。
但有图一定能有真相吗?让我们看一下这个例子。

这是 2015 年的一条非常“热”的图片新闻,说成都的一个小伙子把火锅店开到了南极。后面被证实,图片里南极科考站墙壁上的“成都火锅”是 PS 上去的。由于 P 图技术非常好,人眼很难分辨它的真假,所以很多大媒体都转载了。
我们发现,技术的进步已经颠覆了“有图有真相”的传统认知。图像已经不可信了,那么视频总可以眼见为实了吧?好,我们再看一下。
这个视频是 2018 年通过人脸驱动重演技术伪造奥巴马讲话的一个视频。右边是真正说这一段话的人,左边是通过他的讲话驱动奥巴马视频生成的伪造讲话。我们看到,这个视频看着非常真实对不对?那视频也很难相信了。
如果说前面的文字新闻可以通过人工审核判断真假,那么图片和视频一定需要技术揭示出伪造的本质,才能识别出来。我们现在要做的事情就是跟上技术的进步,使得社会的认知达到一个新的平衡。“魔高一尺”,我们要“道高一丈”,这就是我选择这个方向的原因。
在做这个方向的过程中,我们遇到了第一个问题:我要检测谣言,那谣言长什么样子呢?具备什么样的特征呢?
谣言最早的一个定义来自于社会心理学,他把谣言定义为一种被广泛传播的、未经证实的信息。广泛传播和未经证实就是谣言的本质特性。
举个例子,比如说我为了让这次演讲效果更好,今天吃了兴奋剂。但我就算吃兴奋剂其实也并不重要,对不对?所以也就没有核查价值,因为它不会引起广泛传播。但是如果我说某个运动员吃了兴奋剂,这个事情就非常关键——它会引起广泛的传播,那么核查它的真假就非常有价值、有意义。所以广泛传播是谣言的一个本质特点。
为了探索这两个特点,我们需要大量数据的支撑,所以我们要做的第一件事就是建一个谣言大数据平台。团队花了大半年的时间,用几十台机器搭建了一个分布式的采集平台,每 10 分钟为一个采集周期,每天能发现上百条争议性的新闻线索。从 2014 年至今积累了 8 年,达到了百万级的争议性新闻线索,其中有十万级的人工精标注的谣言数据。

这个平台对我们的研究非常重要,我后面要介绍的所有工作都是基于这个平台开展的。
首先,我们发现谣言有自己的语言学的模式。比如它是未经证实的,它的信息是不可信的,那就经常会出现“网传”“据说”“爆料”“有消息称”……因为它未经证实,所以就有人去质疑,问“真的假的”?甚至去否定它,说这是不实的,这是谣言,这是假的。
又由于谣言要达到广泛传播的目的,它会煽动你、影响你,所以它的情绪会非常饱满,比如说“太可怕了”“太惨了”,有这样一些浓烈的情感;它甚至会告诉你“求转发”“求扩散”。

Guo et al., Rumor Detection with Hierarchical Social Attention Network.CIKM 2018.
我们分别在 Twitter 的英文环境和微博的中文环境数据上进行过验证,确实具有这样的语言模式。如果你以后看到具有这些关键词的新闻,一定要小心点哦。

Zhang et al., Mining Dual Emotion for Fake News Detection. WWW 2021.
第二个是谣言的情感模式,它要影响你、让你去传播,就得在情感上煽动你。比如上图左边的新闻,它本身带有很强烈的情感,“不作为的”“惨案”等等就会去煽动你。但还有一类新闻非常隐蔽,像右边这样的新闻,它会模仿官方的发文,一本正经地在说谎。他知道他的话题一定会戳中大家的痛点、热点或者关注点,这时就会在社区评论引起大规模的社会情绪。据我们提出的双流情感检测模型,就能分别检测这两类谣言。

Sheng et al., Zoom Out and Observe: News Environment Perception for FakeNews Detection. ACL 2022.
最后一类是谣言的视觉模式。图像和视频是最容易煽动人、最容易迷惑人的。但是由于造假难度很大、成本很高,所以也很容易抓到漏洞、抓到破绽。我们从谣言视觉上的造假痕迹到它的造假意图,在每个层次都进行了建模。
我们发现,因为谣言要说的是假事件,所以没有对应的图片,就会去造一个假图片。在这个过程中,就会在像素级或者局部边缘留下很多篡改的痕迹;其次,它在伪造的时候,一定会伪造一些非常关键的语义对象,比如说某个人、某个场景、某个标志或者某个动作等等;最后,为了让你去点击它、传播它,它一定会充满视觉冲击,具有情绪煽动性。

我们来举两个例子。比如说这两张图片,左边是原图,中图对背景里面的观众进行了替换。通过检测这个图片的噪声图像(右),我们发现它在右上角留下了一个非常明显的痕迹,这就是篡改痕迹。
Qi et al. Improving Fake News Detection by Using anEntity-enhanced Framework to Fuse Diverse Multimodal Clues, MM2021 亓鹏等,语义增强的多模态虚假新闻监测,计算机研究与发展,2021 年第 7 期
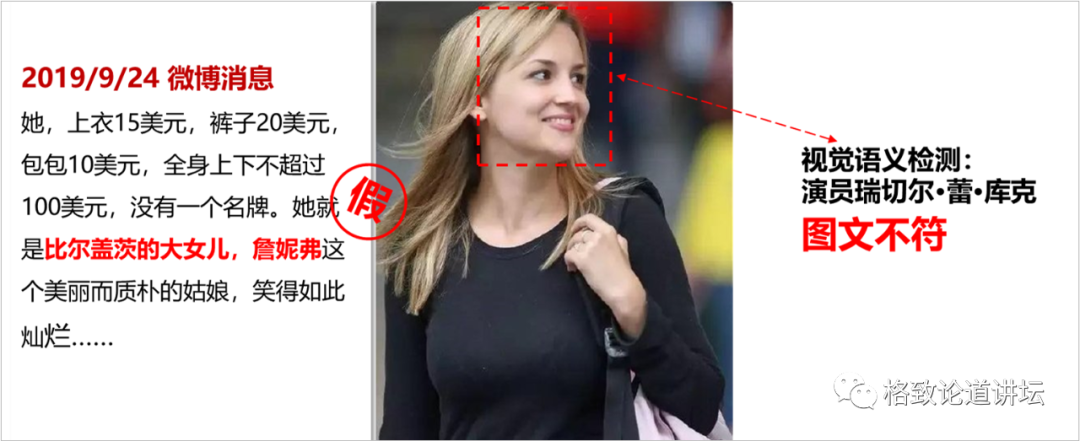
再比如这个新闻。文字新闻说他们拍到了比尔盖茨的女儿,但是我们通过检测这个配图,人脸识别后发现她并不是盖茨的女儿,而是一个女明星。图文不符,所以这是一条假新闻。这就是在视觉方面去做虚假新闻的识别。
讲完这么多的谣言模式,大家很容易想到:既然谣言有这么多特点,我们能不能基于这些特点,在海量的信息中自动地、快速地发现谣言呢?但这个时候,我们又遇到了新的问题,这是一个很大的难点。我们可以看一下这两组对比数据。

Silverman, This Analysis Shows How Viral Fake Election News StoriesOutperformed Real News On Facebook. Buzzfeed News, 2016.
这张图是 2016 年美国大选期间的虚假新闻数据,红色的线是虚假新闻的互动量(阅读量、点击量),黑色的线是正常新闻的互动量。可以看到,在大选的最后时刻,虚假新闻的互动量已经超过了真实新闻。也就是说那个时候,美国人看到的大选新闻大部分是假的,是不是觉得很恐怖?
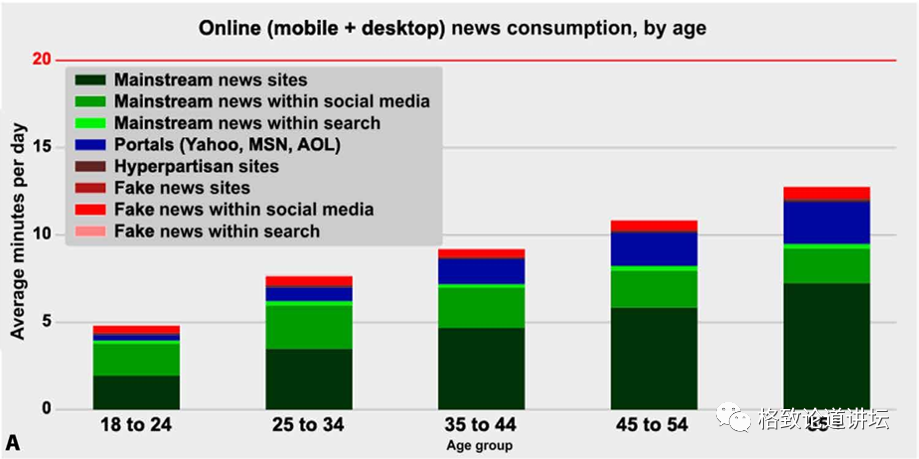
红色部分代表假新闻 Allen et al., Evaluating the Fake News Problem at the Scale of theInformation Ecosystem. Science Advances, 2020.
在这样一个局部事件里面,虚假新闻是特别的多,影响特别的大。但如果我们把这个虚假新闻放到整个互联网上,又会有什么样的结果呢?我们看一下上图,图中的红色部分就是虚假新闻的数量。其实在整个互联网上,虚假新闻只占了人们新闻阅读量的 7%。而我们在现实空间中检测虚假新闻,就是要做这样的事情——在海量的数据规模里,如何快速检测到虚假新闻?这就是它的难点。
我们探索了两种方案。第一种就是,有没有可能去模拟一些伪造数据,去生成更大的数据库,模拟未来的、可能的未知空间;还有一种就是能不能把问题缩小,在小领域中一个一个地去解决。
这两种方案都是可行的,我们先来看一下第一种。比如要检测我的伪造图像,现在网上关于我的伪造图像肯定不多,那未来可能的伪造图像会是什么样子的呢?我不知道。那么我们就自己去模拟吧,把可能的伪造情景都造出来。他们有可能会改变我的发型,有可能会改变我的动作、我的姿态,还有可能改变我的妆容等等。通过自己模拟有可能的伪造信息,那么这个数据就变大了。

Li et al., Progressive Domain Expansion Network for Single DomainGeneralization. CVPR 2021.
要完成这个功能需要两个步骤。第一个就是整理、研发和生成大量的算法工具集,我们已经整理和研发了 80 多款这样的生成工具集,第二个就是在生成的过程中需要有一定的标准:首先生成的数据必须是安全的,也就是说你生成的必须是我,不能生成“林志玲”;其次生成的数据必须是有效的,每一个图片要有差异,是去描述未知空间的。如果都跟原来的图片一样,它就没有效果。
通过这两个规则,我们就可以把小数据变成大数据,从而解决我们可能从来没有见过、但是未来可能伪造的一些情形。如果见过它了,以后我就能准确地检测到,所以这就解决了大数据的问题。
第二,有没有可能把这个问题缩小,针对特定领域的造假,一个一个地去解决它呢?我们发现,虽然都是伪造,但是不同领域的伪造特点不一样。

左:文字图片伪造检测 中:高清精修新闻配图伪造检测 右:网络低分辨率视频伪造检测
文字、图片的伪造其实有很多的固定区域,比如会特别想伪造金额、数字、签名等等。对于高清的、新闻精修图片的伪造,它要挑战的地方就是强对抗性。因为是由专业人士伪造,把一般能被检测到的伪造痕迹抹除了,所以需要强对抗。对于互联网上的低分辨率的图像和视频,它最大的难点就是抗压缩。同样一个视频,可能在这个平台上能检测到,传到另外一个平台就检测不到了。这是因为经过几轮压缩以后,很多造假痕迹都变模糊了。
通过这样分析以后,我们就开始分门别类地、按小领域一个一个地进行技术突破、解决,才有可能达到实用。最终我们针对于不同的行业,提出了不同的伪造检测的方案。
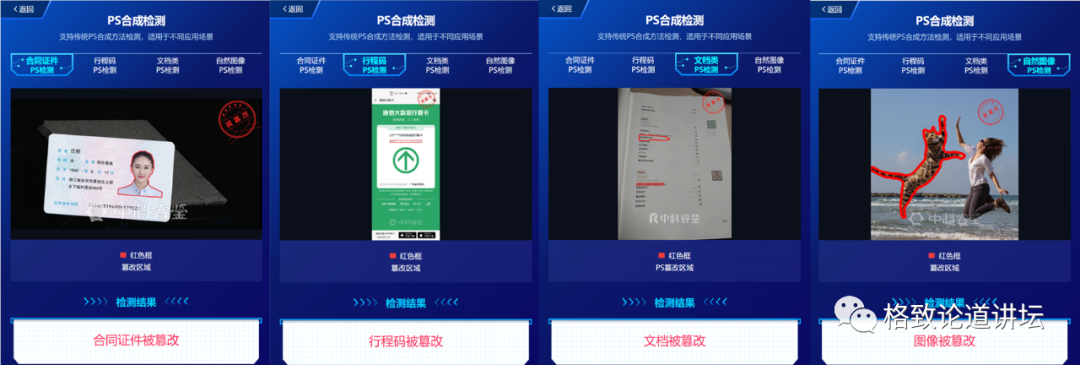
比如针对证件,我们有专门针对证件的伪造检测的方案;针对于行程码这个小类,我们也有行程码的解决方案,因为它的日期、星号经常会被篡改;针对合同,我们会有合同的解决方案;针对自然的图像的 PS,也有它的单独的解决方案。这样就能各个击破,基本达到实用的效果。
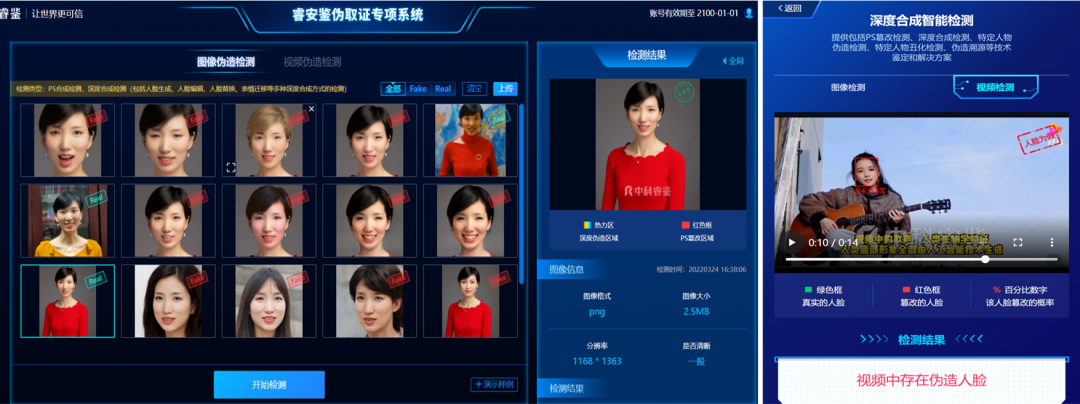
针对人脸伪造也是一样的。针对某个特定的人物,我去搜集有关他的大量数据,提取他的固有特征,比如我的唇纹是什么样子的,我笑的时候皱纹是什么样子的,每个人都会不一样。通过提取特定人物的固有信息,我就能更加精准、更加快速地去检测有关他的伪造。比如现在检测特定人物就能达到一个很高的精度,我们的速度能达到每张图片 10 毫秒以内,基本接近实时处理。
大家看完以后,会觉得谣言检测已经这么准了,这个问题就解决了,是不是?但我们在研究的过程中,又发现了一个难点:很多谣言的传播是在辟谣以后才发生的,反而辟完谣以后还有大量的传播。这是为什么呢?虽然你辟谣了,但没有告诉我它为什么假,我还不相信。所以怎么去降低谣言的传播呢?

在半个世纪之前,社会学专家已经对这个问题进行过研究,提出了一个非常经典的谣言公式,他们认为:谣言的传播力=事件的重要性×事件的模糊性。如果要降低谣言的传播,要不就降低它的重要性,让它无处可传;要不就是降低它的模糊性,通过取证、解释告诉别人它为什么假,那么大家就不会再传了,对不对?我们就试图通过降低事件的模糊性来解决这个问题。
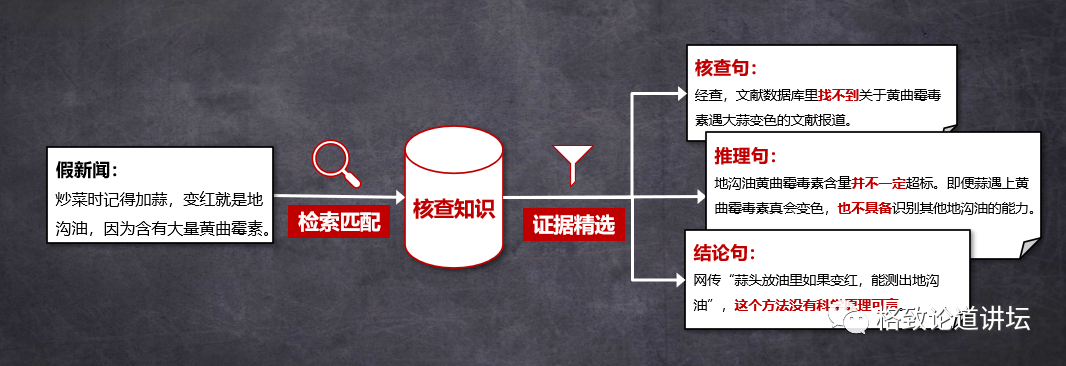
伪造证据核查取证 Sheng et al., Article Reranking by Memory-Enhanced Key Sentence Matchingfor Detecting Previously Fact-Checked Claims. ACL 2021.
首先,找到一条谣言以后,我们会从大量的数据里去匹配、去寻找它为什么是假,哪个地方错了。通过快速地找证据,告诉用户假的地方在哪里,从而达到谣言核实取证的效果。
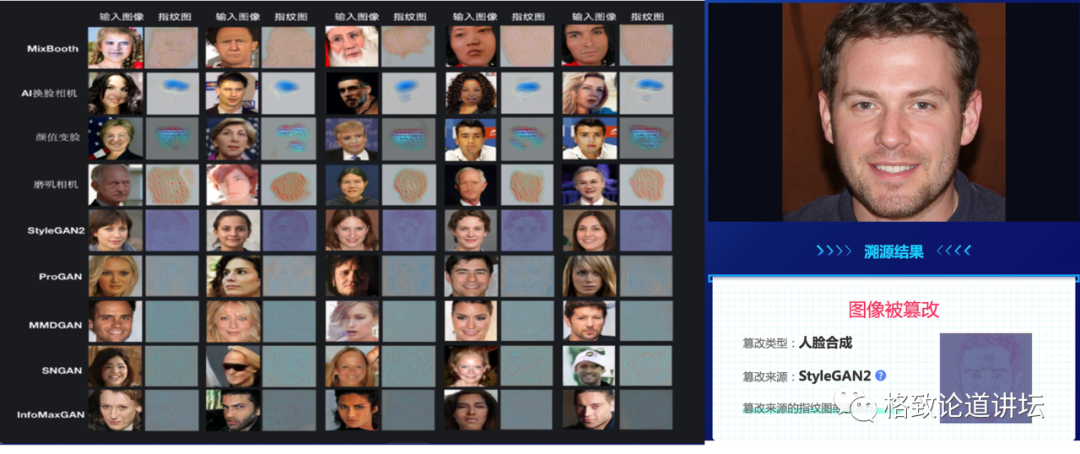
伪造算法溯源 Yang et al., Deepfake Network Architecture Attribution. AAAI 2022.
其次,如果我不仅告诉你这个图片是假的,我还告诉你它是用哪个算法做的,你是不是会更加相信我了?既然图片的造假是无中生有的,那么它一定是基于某种规则去生成的,这就会留下很多的痕迹,我们把它叫做模型指纹。就像人的指纹一样,拿到这个指纹之后,通过溯源模型,我们就能知道它的伪造算法是哪一个,这能让你更加相信。
上面两个方法都是通过技术去试图降低谣言的传播。但我在这 10 年里面发现,其实谣言的治理不止是一个技术问题,它更是一个社会问题。

只要关注消息“准确度”,转发假新闻的意愿会下降 21.4% Pennycook et al., Shifting attention to accuracy can reduce misinformationonline. Nature 592, 2021.
同学、朋友在给我发信息求证的时候,我相信他们心里一定已经有了答案:我要不要转发这条信息,是不是?我的想法也正好得到了《自然》(Nature)2021 年一项工作的证实。这个工作证明一个人在阅读虚假信息的时候,你只要在中间插入一个环节,问他“这个信息是真的吗?”,他转发谣言的意愿就会降低 21%。也就是说,只要你开始关注“信息是不是准确的”这个问题以后,你转发的动力就会降低。
所以回顾这 10 年里面,我已经在点点滴滴中影响到了身边的人,在他们建立媒体的思辨习惯的时候做了一点小小的贡献。
因此,这个事件启发了我。我认为我们的工作、我们的研发成果应该更加开放,让大家在消费互联网新闻的时候有一个地方查一查、问一问,让这个世界更加真实,多一份美好。所以我把这个伪造检测的工具公布出来了,也欢迎大家来使用。
最后,我希望在这个领域里面继续探索,做一个更加专业的“女侦探”,用技术让生活更加美好。谢谢大家!
来源丨格致论道讲坛(ID:SELFtalks)
责编丨钟艳平
审校丨徐来 林林
本文封面图片及文内图片来自版权图库
转载使用可能引发版权纠纷
原创图文转载请后台回复“转载”










