作为目前最为高效的流处理框架之一,Flink在我们的大数据平台产品中得到了广泛运用。为了简化开发,我们对Flink做了一些封装,以满足我们自己的产品需求。
我们开发的一个基于大数据平台的数据仓库,选择了Flink作为数据处理的底层框架。我们主要看重于它在流处理的低延迟性,消息传递保证的extractly once特性;它为流处理和批处理提供了相对统一的API,支持Java、Scala和Python等主流开发语言,同时还较好地支持了SQL。Flink搭建了非常棒的基础设施,例如它可以和ZooKeeper、YARN集成起来,保证处理功能的高可用性与水平扩展的集群能力,同时还提供了相对开放的扩展能力,使得我们可以较容易地在已有功能基础之上实现定制开发。
我们基于Flink开发了自己的底层框架“海纳(haina)”,这是取“海纳百川有容乃大”之意。haina以库的形式为我们的产品提供了数据采集、治理和共享等功能,是整个平台最核心的数据处理基础设施,逻辑架构如下图所示:
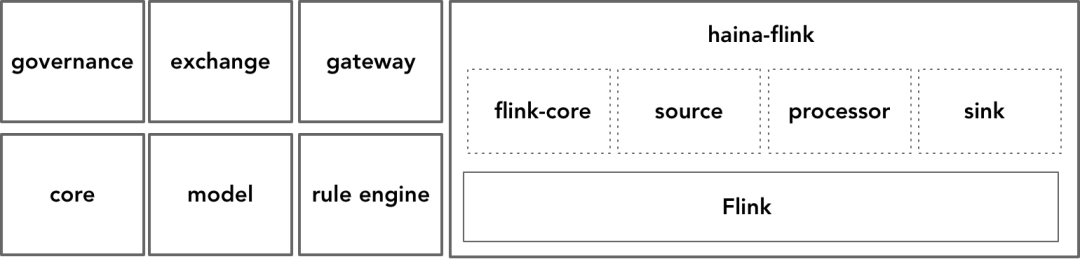
由于我们的产品对数据的处理主要包括三个方面:采集、治理与共享,这之间流转的皆为采集器从上游系统采集获得的数据。我们结合Flink的架构,并参考了Apex、Storm、Flume等其他流处理框架,抽象出自己的流处理模型。这个模型中各个概念之间的关系与层次如下图所示:
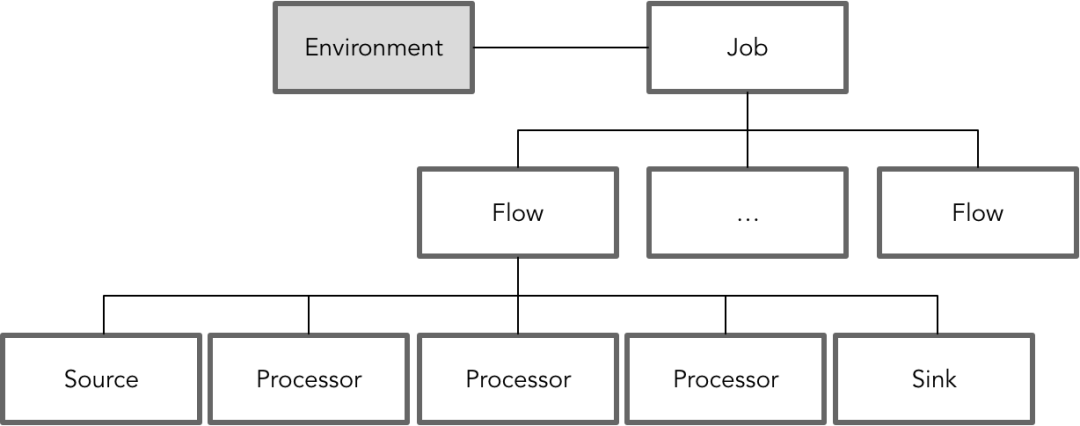
在这个流处理模型中,一个Job对应一个实际的物理环境(Environment)。多数情况下,为了保证Job运行的独立性,可以为每个Job分配一个单独的运行节点,提供专有的运行资源。每个Job核心的逻辑概念是Flow,它由Source、Processor和Sink组成,它们都是Flink的Operator,其中Processor对应于Flink的Transformation Operator。在实时流处理中,一个典型的Processor其实就是我们常用的map、filter或flatMap函数。例如:
public class ArchiveJsonMetaProcessor implements MapFunction<String, String> {
private String target;
public ArchiveJsonMetaProcessor(String target) {
this.target = target;
}
@Override
public String map(String msg) {
JSONObject message = JSONObject.parseObject(msg);
String messageId = message.getString("messageId");
String originTimestamp = message.getString("originalTimestamp");
String archivedTimestamp = DateUtil.transformTime(new Date(), DateUtil.YYYYMMDDHHMMSSS);
ArchivedMetaData archivedMetaData = ArchivedMetaData.fillArchivedMetaData(messageId, target, originTimestamp, archivedTimestamp);
return JSON.toJSONString(archivedMetaData);
}
}
我们之所以要抽象出Processor概念,是因为我们遵循了管道-过滤器模式,希望每个operator都是一个最小的可以重用的逻辑单元。管道就是我们定义的Flow,Source是管道的上游入口,Sink是管道的下游出口,每个细粒度的Processor就是每个负责处理数据流的过滤器。我们的底层框架haina实现了这些逻辑单元,至于它们该如何组装,则交由框架的使用者。正因为此,我们制定了Processor的设计原则,其根本思想就是保持Processor的细粒度,严格分离与业务无关和有关的Processor,保证Processor在组成Flow时尽可能被重用。
如下为设计Processor应该遵循的原则:
-
业务上对数据流的处理可以拆分为多个阶段,每个Processor对应一个阶段。
-
尽可能把有副作用的和无副作用的职责分离到不同的Processor。
-
把需要访问外部资源的职责尽可能分离到不同的Processor。
-
尽可能确保Processor的代码短小,这样可以保证将Processor真正的职责转移到别的类,例如对象的转换逻辑。转移出去的类与Flink平台无关,有利于编写和运行单元测试。
-
每个Processor的上游与下游,即MapFunction或其他接口对应的类型参数T与O,应尽量采用平台定义的模型对象,而非如String之类的基础类型。这样就能保证调用者对Processor进行组装时,通过编译就能检查到不必要的组装错误。
-
每个Processor的命名采用动宾短语,并以Processor作为类的后缀。例如将一条航班信息拆分成多个机位信息,命名为SplitFlightToStandsProcessor。好的命名可以帮助我们更容易发现它,进而促进调用者对它的重用。例如在IntelliJ中,就可以直接以*Processor来搜索所有的Processor,然后根据它的命名就能推测出这个Processor到底是做什么的。
-
每个Processor需要的外部数据,都通过Processor的构造函数来传递。
-
每个Processor都应该实现Flink提供的transfomation接口。
-
第一个Processor接收的是String类型的消息,则要求必须对传入的消息进行验证。用于验证的Processor应该实现FilterFunction
。
-
应保证每个Processor都不要抛出出人意料不可控制的异常,否则可能导致执行Job时出现错误从而导致整个Application停止或者重启。
针对Source与Sink,除了重用Flink本身提供的source与sink之外,我们还开发了大量的满足自己需求的自定义Source与Sink。例如,我们为独立开发的ESB系统提供了Source,为关系型数据库和WebService提供了具有轮询能力的Source,为ElasticSearch开发了满足批量添加数据的Sink,同时还实现了具有回调能力的自定义Sink。如下就是针对Oracle编写的具有轮询能力的自定义Source:
public class OracleClobSource extends RichSourceFunction<String> {
private static final Logger log = LoggerFactory.getLogger(OracleClobSource.class);
private JdbcGateway jdbcGateway;
private Long period;
private DSLContext executor;
public OracleClobSource(JdbcGateway jdbcGateway, Long period) {
this.jdbcGateway = jdbcGateway;
this.period = period;
}
@Override
public void open(Configuration parameters) throws Exception {
executor = jdbcGateway.executor();
}
@Override
public void run(SourceContext ctx) throws Exception {
while (true) {
Result results = executor.select().from(table(tableName)).where(rownum().le(10)).fetch();
for (Record record : results) {
String msgcontext = record.get(field(filedName), String.class);
ctx.collect(msgcontext);
Long id = record.get(field("ID"), Long.class);
executor.delete(table(tableName)).where(field("ID").equal(id)).execute();
}
Thread.sleep(period);
}
}
@Override
public void cancel() {
executor.close();
}
}
为了便于使用,我们还为这些内置与定制source和sink分别定义了静态工厂。
Flow相当于是传递DataStream的拓扑图,由Source、Processor和Sink组成。我们之所以引入这个概念,一方面是为Job提供更粗粒度的重用单元,另一方面也承担了封装业务流程的主要职责。例如,一个航班数据从上游系统进入我们的大数据平台,需要进行多次数据格式的转换、验证与治理,我们就可以定义一个FlightFlow来完成这些细小职责的组装:
public class FlightFlow extends AbstractFlow {
public FlightFlow(Environment env, Config config) {
super(env, config);
}
private static final String FLIGHT = "flight";
@Override
public void run() {
DataStream source = env.addSource(sourcesFactory.createSslKafkaSource("INBOUND"));
SingleOutputStreamOperator flightStream = source
.filter(new FilterFlightProcessor())
.map(new TransformXmlToJsonProcessor())
.map(new TransformJsonStringToJsonObjectProcessor())
.map(new