 戳上面的蓝字关注我们哦,开启你的学术之旅!
戳上面的蓝字关注我们哦,开启你的学术之旅!

原文:《贝叶斯因子及其在 JASP 中的实现》
来源: ChinaXiv:201709.00120
作者: 胡传鹏 孔祥祯 Eric-Jan Wagenmakers Alexander Ly 彭凯平
统计推断在科学研究中起到关键作用,然而当前科研中最常用的经典统计方法——零假设检验(Null hypothesis significance test, NHST)却因为难以正确理解而被滥用或误用。有研究者提出使用贝叶斯因子(Bayes factor)作为是一种替代和(或)补充的统计方法。贝叶斯因 子是贝叶斯统计中用来进行模型比较和假设检验的重要方法,这一方法对于心理学及相关领域的大部分研究者来说仍然比较陌生。因此,本文介绍了贝叶斯因子的基本思路,并总结了贝叶斯因子与 NHST 相比的优势。在此基础上,以贝叶斯独立样本 t 检验为例,演示如何在开放的 统计软件 JASP 中实现贝叶斯因子的计算,并解释了对贝叶斯因子结果的解读。最后,对贝叶斯因子的不足及其应用价值进行了讨论。
自
20
世纪以来,统计推断在科学研究中起到越来越重要的作用,科学研究的结论也越来 越依赖于统计推断的正确应用。目前使用最为广泛的统计推断方法是零假设检验(
Null hypothesis significance test, NHST
)
(
见
Wasserstein & Lazar, 2016
。然而,与
NHST
在各个领域中广泛使用相伴的是研究者对
NHST
及
p
值的误解和盲目使用,因此可能反而会带来了 些消极的后果。例如,
p
值被用来支持不合理且无法重复的研究结果
,引起了关于
NHST
是 否适合于科学研究的争论。在这个背景之下,有研究者推荐使用贝叶斯因子替代
NHST
。
贝叶斯因子(
Bayes factor
)是贝叶斯统计(
Bayesian statistics
)中用来进行模型比较和假设 检验的方法。在假设检验中,其代表的是当前数据对零假设与备择假设支持的强度之间的比率。 正如下一节将要详述的,贝叶斯因子能够量化地反映当前数据对各个假设支持的程度,因此可能更加适用于科研中的假设检验。但是,由于贝叶斯因子的统计原理及实现相对复杂,其在各个学科的研究中并未获得广泛关注。例如,虽然早在上世纪
60
年代已有研究者试图将贝叶斯 因子引入心理学研究,却一直未能获得广泛使用。
但是,随着计算机运算能力的大大提升,贝叶斯统计在计算机等领域获得了巨大的成功。 同时,研究者们开发出用于贝叶斯统计的工具,如
WinBUGs
、
JAGS
、
Stan
等,这些软件的出现,促进贝叶斯方法在各个研究领域中的使用。在这些贝叶斯统计相关的工具中,也有用于计算贝叶斯因子的工具,如
R
语言中的
BayesFactor
。而在心理学及相关领域,不少研究者也试图引入贝叶斯统计的方法,尤其是在最近大量心理学研究无法重复的背景之。但对于不少心理学及相关领域的研究者来说,使用
R
语言或其他计算机语言进行贝叶 斯因子计算仍然有一些困难。为解决这一障碍,研究者们进一步开发了与商业统计软件
SPSS
具有类似图形界面的统计工具
JASP (https://jasp-stats.org/, JASP team 2017)
,简化了贝叶斯因子的计算。
本文旨在为向心理学及相关学科的研究者介绍贝叶斯因子及其使用。首先本文将介绍贝叶
斯因子的原理,及其相对于传统假设检验中
p
值的优势;再以独立样本
t
检验为例,介绍了如 何使用
JASP
计算贝叶斯因子,以及如何解读和报告其结果。在此基础上,讨论了贝叶斯因子 的不足及应用价值。
贝叶斯因子是贝叶斯统计在假设检验上的应用,因此要理解贝叶斯因子,首先需要理解贝叶斯统计的原理。
贝叶斯学派(
Bayesian statistics
)与频率学派(
Frequentist statistics
)是统计学中主要的两个学派,其最核心的差异在于他们对于概率(
probability
)有着不一样的定义。对于频率学派而 言,概率是通过无数次重复抽样中频率(
frequency
)的预期值。与之相反,贝叶斯学派则认为, 概率是对一件事情的相信程度,从
0
到
1
表示人们基于事先所获得的信息,在多大程度上相信 某件事情是真的。由于不同人对同一事件的相信程度可能不同,因此,贝叶斯学派的概率是具 有主观性。但贝叶斯学派的概率却不是任意的:人们通过合理的方式,不断获取并更新已知信 息,可以最终消除主观性,从而达成一致。
由于频率学派将概率定义为长期行为表现的结果,因此要理解频率学派的概率,通常需要 假想那些尚未发生的事件。例如,在
NHST
框架之下,
p
值的意义是假定
H
0
为真的情况下,出现当前结果及比当前结果更加极端结果的概率。换句话说,
p
值表达的是:如果以完全相同的条件无数次地重复当前实验,这些实验中有多少大比例会出现当前结果模式或者更极端结果 的模式。因此,
p
值的意义暗含一个假设:我们能够进行无数次相同的试验。但是实际上,研 究者往往难以理解这种对未出现的无数次相同试验的假定,而误认为
p
值是一次检验中拒绝零 假设时犯错误的概率。这种对
NHST
的误解,恰好是带有贝叶斯统计色彩,即根据当前的数据计算某个模型正确或错误的概率。
与频率学派统计不同,贝叶斯统计最大的特点之一在于:贝叶斯统计考虑了个体对不同可 能性的可信度(
credibility
),而改变其可信度的,正是人们不断获得的数据。这种思维方式 与人们在日常生活中的经验非常相似:当我们不断地获得支持某个观点的证据时,我们会更加相信该观点。
虽然贝叶斯统计对概率的理解与频率学派不同,但是其对概率的计算却严格依照概率的基 本原则:加法原则与乘法原则。贝叶斯统计中最核心的贝叶斯法则(
Bayes rule
),也是根据简 单的加法原则与乘法原则推导而来。依据概率的乘法原则,随机事件
A
与随机事件
B
同时发生的概率为:
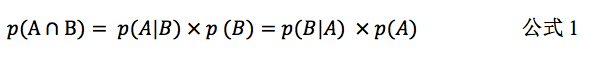
公式
1
即为联合概率的公式,即随机事件
A
与随机事件
B
同时发生的概率。其意义为:
随机事件
A
与随机事件
B
的联合概率(
p
(A∩B)
)为,在
B
发生的条件下
A
发生的概率(
p
(A|B)
) 与
B
发生的的概率(
p
(B)
)的乘积,也等于在
A
发生的条件下
B
发生的概率(
p
(B|A)
)与事件
A
发生的概率(
p
(A)
)的乘积。其中,
p
(A|B)
和
p
(B|A)
均为条件概率(
conditional probability
),二者意义不同。
对公式
1
进行变换,即可以得到如下公式:
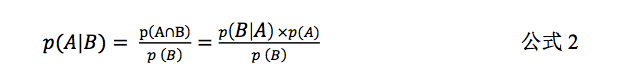
公式
2
即为贝叶斯定理公式。其代表的意义是,如果我们要计算随机事件
B
发生的条件 下
A
发生的概率(
p
(A|B)
),可以通过使用
A
与
B
同时发生的概率(
p
(A∩B)
)除以
B
发生的 概率(
p
(B)
),也就等于在
A
发生的条件下
B
发生的概率,与
A
发生概率的乘积,再除以
B
发 生的概率。公式
2
将两个条件概率联系起来,从而使得计算不同的条件概率成为可能。
在贝叶斯统计的框架之下,公式
2
可以看作是一次信息的更新。假定我们需要根据一次实
验收集到的数据(
data
)来检验某个理论模型为真的可能性。如果我们以心理学研究中常用的 零假设
H
0
为例,则可以将公式
2
改写如下:
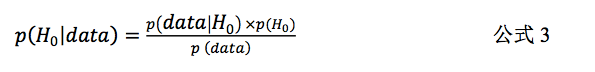
p
(
H
0
|data)
表示数据更新之后理论模型
H
0
正确的概率,即后验概率(
posterior
);
p
(
H
0
)
表示 更新数据之前认为理论模型
H
0
正确的概率,即先验概率(
prior
);而
p
(data|
H
0
)
则是在模型
H
0
之下,出现当前数据的概率,即边缘似然性(
marginal likelihood
)。由此可以看出,在贝叶斯统 计之中,一次数据收集(实验)的主要功能在于帮助我们更新理论模型的可信度。
根据公式
3
,我们可以使用数据对任意的模型为真的概率进行更新。在假设检验中,我们
可以根据观测数据同时对零假设(理论模型
H
0
)和备择假设(理论模型
H
1
)的可信度进行更新
(
分别见公式
3
和公式
4)
,得到它们更新的后验概率。
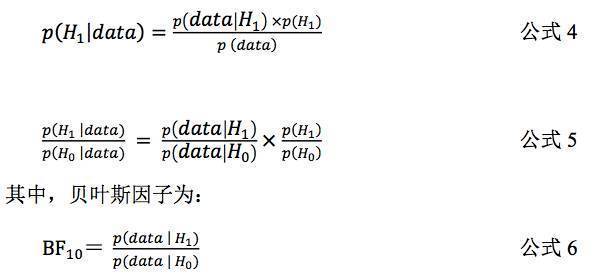
在公式
6
中,
BF
10
中下标的
1
,代表的是
H
1
,
0
代表的是
H
0
,因此,
BF
10
即代表的是
H
1
与
H
0
对比的贝叶斯因子,而
BF
01
即代表的是
H
0
与
H
1
对比的贝叶斯因子。例如,
BF
10
=
19
表示的是,在在备择假设
H
1
为真条件下出现当前数据的可能性是虚无假设
H
0
条件下出现当前 数据的可能性的
19
倍。
从贝叶斯因子的公式中可以看出,贝叶斯因子不依赖于对先验假设(
p
(
H
1
)
和
p
(
H
0
)
)。更重要的是,正是贝叶斯因子根据当前数据将先验概率更新为后验概率。
因此,
NHST
与贝叶斯因子回答了不同的问题。
NHST
试图回答“假定我们已知两个变量
的关系(如,两种条件没有差异),出现当前观测数据的模式或者更加极端模式的概率(
p
(more extreme > observed data|H0)
)有多大”的问题;而贝叶斯因子试图回答的是,在当前数据更可 能在哪个理论模型下出现。考虑到研究者往往想知道当前数据模式条件下,
H
0
或者
H
1
为真的 概率(分别为
p
(
H
0
|data)
与
p
(
H
1
|data)
),在假设检验中,贝叶斯因子具有一些
NHST
不具备的 优势,下一小节将对这些优势进行详细说明。
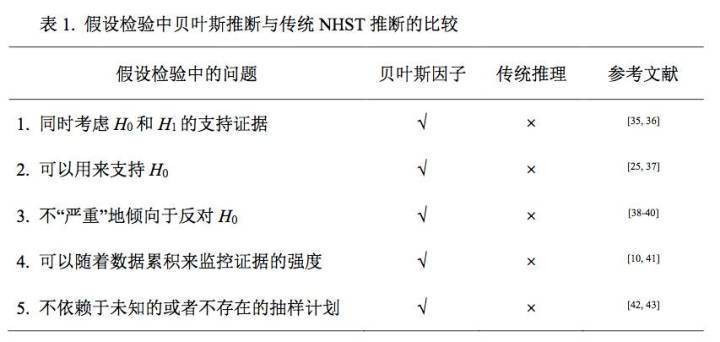
对贝叶斯因子大小的解读,在
Jeffreys (1961)
的基础上,
Wagenmakers, et al. (2017)
对贝叶斯因子的大小所代表的意义进行原则上的划分(见表
2
)。但是这个划分仅是大致参考,不能严格对应,研究者需要根据具体的研究来判断贝叶斯因子的意义。
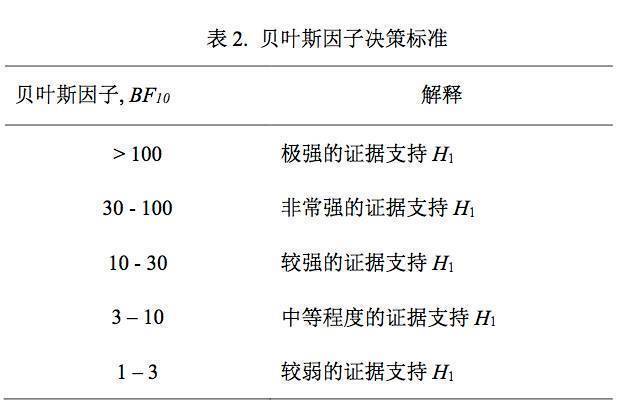
由于贝叶斯因子中先验概率具有至关重要的作用,因此如何选择备择假设的先验分布变成 了一个非常重要的问题。其中一个较为合理的做法是,根据采用该范式的先前研究(如元分析得到的效应量)来假设备择假设的先验分布。但这种做法在很多情况下并不现实:首先根据范式的不同,效应量的可能分布不同;更重要地,由于许多研究本身具有一定的探索性,并没有先前研究结果作为指导。因此,更加常用的做法是使用一个综合的、标准化的先验。
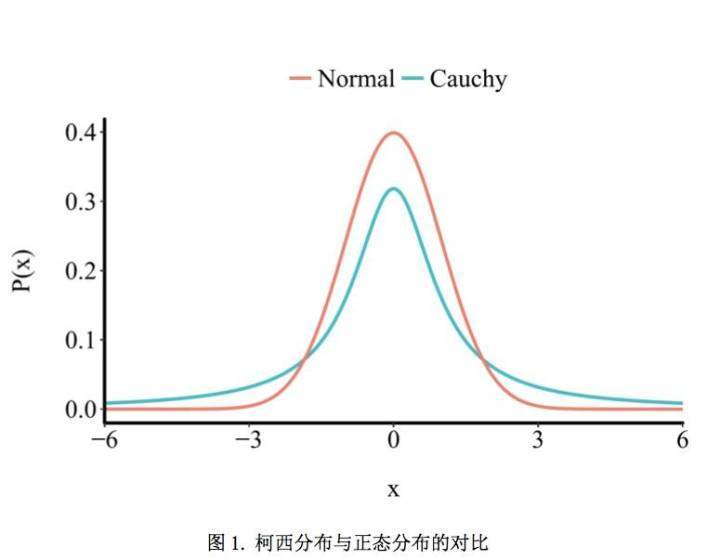
例如,在贝叶斯
t
检验中,零假设的先验比较好确定,但是对于备择假设的先验分布应该 如何选择,则比较困难。有研究者指出,使用柯西分布(
Cauchy distribution
)可能是比较合理 的选择。与标准正态分布相比,柯西分布在
0
附近概率密度相对更小一些,因此其比 标准的正态允许更多较大的效应(见图
1
);而与均匀分布(即效应量在所有值上的分布完全相 同)相比,柯西分布更偏好零假设一些。因此,对于备择假设的先验分布,可以如下表示:
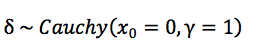
 Jeffreys (1961)
最早提出在贝叶斯因子中使用柯西分布作为先验来比较两样本的问题。最近
研究者的进一步验证表明,柯西分布可以作为先验用于计算心理学常规假设检验中的贝叶斯因 子,如
t
检验、
ANOVA
和相关分析等。这些验证性的工作,为贝叶斯因子在心理学 及相关学科研究中的应用打下了基础。
Jeffreys (1961)
最早提出在贝叶斯因子中使用柯西分布作为先验来比较两样本的问题。最近
研究者的进一步验证表明,柯西分布可以作为先验用于计算心理学常规假设检验中的贝叶斯因 子,如
t
检验、
ANOVA
和相关分析等。这些验证性的工作,为贝叶斯因子在心理学 及相关学科研究中的应用打下了基础。
如前所述,在假设检验中,贝叶斯因子除了更加符合人们的直觉之外,还具有一些
NHST
具备的优势。这些优势可以总结为五个方面(见表
1
)。以下将从这五个方面展开。
如前所述,贝叶斯因子的计算同时考虑
H
0
和
H
1
,并根据全部现有数据对
H
0
和
H
1
为真的 先验概率进行更新,在此基础之上,比较在当前数据下哪个理论模型(
H
0
和
H
1
)更合理。这种思路与
NHST
不同:在
NHST
框架之下,计算
p
值需要假定
H
0
为真,而对
H
1
不做任何假
设,因此
p
值与
H
1
无关;
NHST
的逻辑是,如果
H
0
为真,观察到当前数据出现的概率非常小,则拒绝
H
0
,接受
H
1
;这种情况下,
NHST
忽略了一种可能性:当前数据下,
H
1
为真的概率与
H
0
为真的概率相当或者更小。例如,在
Bem (2011)
中,
H
0
是被试的反应不受到未来出现 刺激的影响,
H
1
是未来出现的刺激会影响到被试当前反应,即被试能够“预知”尚未出现的刺 激。虽然采用
NHST
的逻辑
Bem (2011)
得到了
p
< 0.05
的结果,即
H
0
为真时,得到当前数据 的概率(
p
(
data
|H0)
)很低,因此作者选择拒绝
H
0
而接受
H
1
,认为被试能够预知未来出现的刺 激。然而,研究者更关心的是,根据当前数据,某个模型
/
假设(如
H
1
)为真的概率(
p
(
H
1
|
data
)
), 而非零假设
H
0
为真时得到当前数据的概率(
p
(
data
|
H
0
)
)。考虑到先验知识告诉我们
H
1
本身为 真的概率可能非常低,在当前数据模式下,
H
1
为真的可能性
p
(
H
1
|
data
)
极可能比
H
0
为真的可 能性
p
(
H
0
|
data
)
更低。
此外,
p
值等于在
H
0
为真的情况下,多次重复实验观察到与当前数据一样极端或者更加极端结果的概率
,即
p
值是假定
H
0
为真时概率分布的尾端面积的积分值。因此,对
p
值的理 解需要假定存在着比当前数据更加极端的数据模式,而人们在直觉上并不太擅长做出这种假定, 常常会带来对
p
值的误解。
因此,由于贝叶斯因子分别量化了当前数据对
H
0
和
H
1
的支持强度,对
H
0
和
H
1
同等对待, 而不是像
NHST
一样完全不考虑
H
1
。另外,贝叶斯因子不需要假定未出现的数据,也更加符合人们的直觉
同样,由于同时量化了当前数据对
H
0
和
H
1
各自的支持强度,贝叶斯因子可以用来支持
H
0
。在贝叶斯的框架下,只要
H
0
和
H
1
假设是具体的,贝叶斯因子就可以根据当前数据对他们 的后验概率进行一次更新,从而得到当前数据更支持哪个假设的结果。如果
H
0
比
H
1
更加符
合数据的模式,则贝叶斯因子能够表明当前数据支持
H
1
。但是,在传统的
NHST
框架之下,由于假设检验仅在
H
0
为真的假设下进行,仅凭借大于显著性性水平(比如
0.05
或
0.005
)的
p
值是无法为
H
0
是否为真提供证据。比如,仅依据假设检验的结果
p
= 0.20
并不能断言有证据 表明没有效应(
evidence of absence
)(除非结合样本量、效应量和统计效力
Power
做出综合判断)。
在实际的研究中,能够对
H
0
提供量化的证据具有非常重要的意义,它可以直观地让 研究者区分出有证据表明没有效应(
evidence of absence
)和没有证据表明有效应(
absence of evidence
)这两种情况。更具体来说,贝叶斯因子的结果有三种状态:(
1
)提供了支持
H
1
的 证据(即有证据表明有效应);(
2
)支持
H
0
的证据(即有证据表明没有效应);或(
3
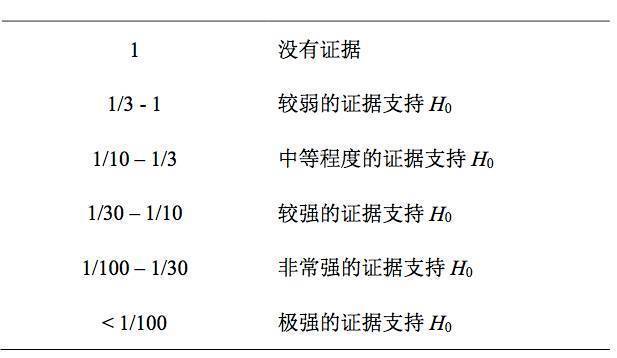
)证据对 两者都不支持(没有足够的证据表明有效应还是无效应)。例如,零假设与备择假设相比的贝 叶斯因子
BF
01
=
15
,则说明的是在这种情况下,观察到的数据出现在
H
0
为真情况下的可能 性是在
H
1
为真情况下的可能性的
15
倍,表明
当前数据更加支持没有效应的假设
H
0
。但是, 假如
BF
01
=
1.5
,则说明观察到的数据出现在
H
0
为真情况下的可能性是在
H
1
为真情况下的 可能性的
1.5
倍,则
说明当前数据对于两个假设的支持程度相当
,没有足够的证据支持
H
0
或 者
H
1
(见表
2
关于贝叶斯因子大小意义的建议)。
值得注意的是,不管是支持
H
1
,还是支持
H
0
,贝叶斯因子提供的证据是相对的,即,相 对于某个假设更支持另一个假设,但可能存在第三个模型
H
2
比
H
1
和
H
0
均更接近真实情况, 具有更高的后验概率。此外,最近有研究者在
NHST
框架之下发展出可以接受零假设的方法: 等同性检验(
Equivalence Test
)。这种方法通过设定多个
H
0
来检验效应量是否与
0
没有差异,
从而检验是否能接受
H
0
。但等同性检验仍然使用了非常主观的
p
值,无法提供对证据的测量。
贝叶斯因子同时分别量化了当前数据对
H
0
和
H










