我们都知道,HashMap在并发环境下使用可能出现问题,但是具体表现,以及为什么出现并发问题,
可能并不是所有人都了解,这篇文章记录一下HashMap在多线程环境下可能出现的问题以及如何避免。
在分析HashMap的并发问题前,先简单了解HashMap的put和get基本操作是如何实现的。
1.HashMap的put和get操作
大家知道HashMap内部实现是通过拉链法解决哈希冲突的,也就是通过链表的结构保存散列到同一数组位置的两个值,
put操作主要是判空,
对key的hashcode执行一次HashMap自己的哈希函数,得到bucketindex位置,还有对重复key的覆盖操作
。
对照源码分析一下具体的put操作是如何完成的:

涉及到的几个方法:

数据put完成以后,就是如何get,我们看一下get函数中的操作:

看一下链表的结点数据结构,保存了四个字段,包括key,value,key对应的hash值以及链表的下一个节点:

2.Rehash/再散列扩展内部数组长度
哈希表结构是结合了数组和链表的优点,在最好情况下,查找和插入都维持了一个较小的时间复杂度O(1),
不过结合HashMap的实现,考虑下面的情况,如果内部Entry[] tablet的容量很小,或者直接极端化为table长度为1的场景,那么全部的数据元素都会产生碰撞,
这时候的哈希表成为一条单链表,查找和添加的时间复杂度变为O(N),失去了哈希表的意义。
所以哈希表的操作中,内部数组的大小非常重要,必须保持一个平衡的数字,使得哈希碰撞不会太频繁,同时占用空间不会过大。
这就需要在哈希表使用的过程中不断的对table容量进行调整,看一下put操作中的addEntry()方法:

这里面resize的过程,就是再散列调整table大小的过程,默认是当前table容量的两倍。

关键的一步操作是transfer(newTable),这个操作会把当前Entry[] table数组的全部元素转移到新的table中,
这个transfer的过程
在并发环境下会发生错误,导致数组链表中的链表形成循环链表,在后面的get操作时e = e.next操作无限循环,Infinite Loop出现。
下面具体分析HashMap的并发问题的表现以及如何出现的。
3.HashMap在多线程put后可能导致get无限循环
HashMap在并发环境下多线程put后可能导致get死循环,具体表现为CPU使用率100%,
看一下transfer的过程:

并发下的Rehash
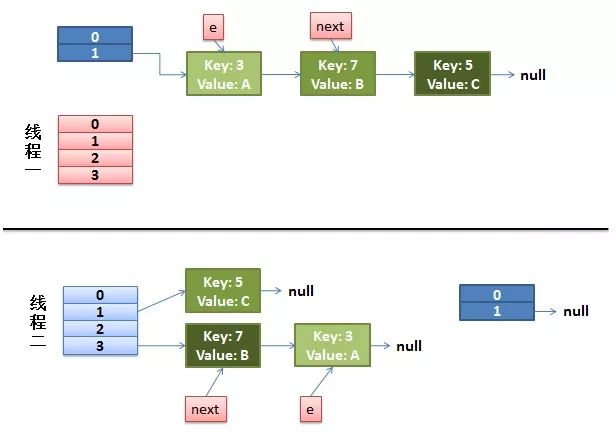
1)假设我们有两个线程。
我用红色和浅蓝色标注了一下。
我们再回头看一下我们的 transfer代码中的这个细节:
|
1
2
3
4
5
6
7
|
do
{
Entry
next = e.next;
int
i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
while
(e !=
null
);
|
而我们的线程二执行完成了。于是我们有下面的这个样子。
注意,
因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表
。我们可以看到链表的顺序被反转后。
2)线程一被调度回来执行。
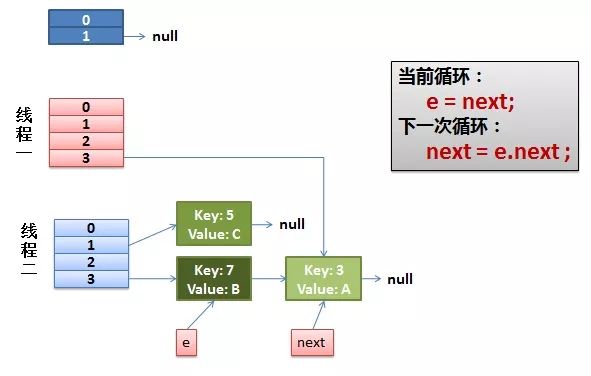
3)一切安好。
线程一接着工作。
把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移
。
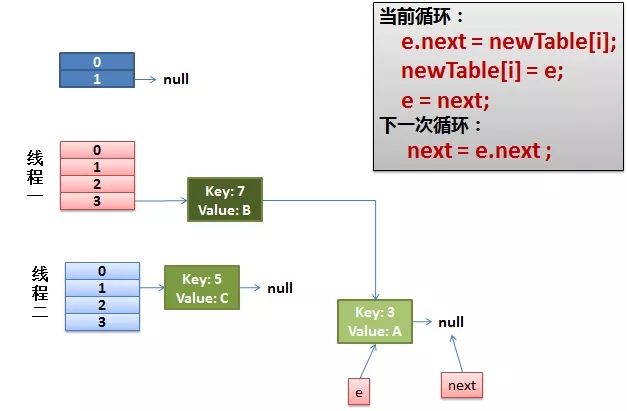
4)环形链接出现。
e.next = newTable[i] 导致 key(3).next 指向了 key(7)
注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。

于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。
针对上面的分析模拟这个例子,









