作者:S.西尔维希耶
编辑:
姜Zn
今天,千年水乡乌镇将迎来一场举世瞩目的围棋峰会。在为期一周的峰会中,“世界第一围棋AI”
AlphaGo
将与中国围棋职业九段棋手
柯洁
对弈三场。并与其他知名中国棋手一起进行团队赛和配对赛。
就在刚刚,柯洁与AlphaGo结束了三番棋
的第一局,AlphaGo执白 1/4子胜。
这也是中国围棋中最微小的胜负。

迄今为止的公开赛事中,AlphaGo VS. 人类围棋选手,战绩已达
70胜
1负
。本文首发微博
@天了噜小组长
,抱着Logo的那只蠢猫据说是小组长本人。
在赛后新闻发布会上,柯洁表示:“
(阿尔法狗)实在下得太出色了,我输的也没什么脾气,真的是很厉害。”
AlphaGo是谁?为什么这场对决会如此受人关注?这篇文章会为你梳理事情的全貌。
AlphaGo是由英国Google DeepMind公司开发的围棋人工智能程序。
它可能是有史以来最强大的围棋棋手。
 图片来源:deepmind.com
图片来源:deepmind.com
DeepMind公司于2010年由杰米斯·哈萨比斯(Demis Hassabis)博士、沙恩·莱吉(Shane Legg)博士和穆斯塔法·苏雷曼(Mustafa Suleyman)共同创立。其中,哈萨比斯和莱吉相识于伦敦大学学院盖茨比计算神经科学组。
与其说是一间创业公司,DeepMind看起来更像是一家
致力于新技术的实验室
。他们的项目包括创造一个能够以和人类一样的方式“学习”如何玩游戏并达到高水平的人工智能。在只用原始像素和游戏得分作为输入数据的情况下,他们的程序学会了包括《乓》(Pong)和《打砖块》(Breakout)在内的多种游戏的玩法,并达到了超人的水平。
2014年,DeepMind被谷歌以4亿美元收购
。同年,AlphaGo项目诞生,开始一步步向围棋游戏的巅峰发起挑战。
 “在‘深蓝’战胜卡斯帕罗夫之后,围棋就成了游戏AI最后的圣杯。”哈萨比斯说。图片来源:blog.google
“在‘深蓝’战胜卡斯帕罗夫之后,围棋就成了游戏AI最后的圣杯。”哈萨比斯说。图片来源:blog.google
在今日对战之前,所有公开赛事中,AlphaGo与人类围棋选手较量的战绩是——
69胜1负
。
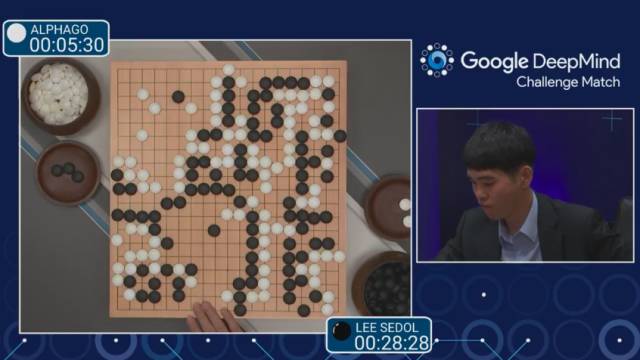
第一场对战的最后时分。之后,
李世乭投子认输。
曾经,柯洁用“震撼”来形容AlphaGo带给围棋界的感受,但同时也表示人类还会变得更强。如今,在乌镇的围棋峰会上,柯洁将在5天内与AlphaGo交锋三局。现在,第一局已经结束,AlphaGo以1/4子的优势险胜柯洁。
之后两局,胜负将会如何呢?
考虑到人工智能在网络快棋中的先天优势,
目前人们仍未能断言AlphaGo在允许人类思考更长时间的
慢棋
中表现同样良好。
不过,谈及乌镇围棋峰会上柯洁对阵AlphaGo的可能结果,
人类棋手表现得非常悲观
。
中国“棋圣”聂卫平表示,他认为柯洁会被0:3击溃。古力九段认为,如果柯洁发挥出100%的状态,
那么他也许有5%的胜率
。而曾经狂傲地认为“阿尔法狗战胜不了我”的柯洁,也谦虚地表示:“这次能代表人类出战是我的荣幸,我将尽全力去争胜,一决胜负,抱有必胜的信念和必死的决心,不轻易言败。”
 古力(左一)、樊麾(左三)、聂卫平(右二)、柯洁(右一)与谷歌CEO桑德尔·皮蔡(左二)一起探讨AlphaGo的棋艺。图片来源:deepmind.com
古力(左一)、樊麾(左三)、聂卫平(右二)、柯洁(右一)与谷歌CEO桑德尔·皮蔡(左二)一起探讨AlphaGo的棋艺。图片来源:deepmind.com
哈萨比斯则在博客中期待柯洁能将AlphaGo的表现逼到极限,乃至超越极限。同时,由陈耀烨九段、周睿羊九段、芈昱廷九段、时越九段和唐韦星九段组成的团队也会与AlphaGo进行一场较量。哈萨比斯希望他们能够测试AlphaGo的创造力和适应能力到底在什么水平。
在一局围棋中,平均每一步的下法大约有200种可能。棋盘上可能出现的局面总数到了远大于宇宙中原子总数的地步。因此,通过暴力穷举手段预测所有的可能情况并从中筛选中最优势走法的思路,并不适用于围棋AI。
 围棋棋盘上出现的可能局面数远大于宇宙中的原子数量。图片来源:Deepmind
围棋棋盘上出现的可能局面数远大于宇宙中的原子数量。图片来源:Deepmind
AlphaGo选择了别的下棋方式。支撑AlphaGo提高棋力、打败人类选手的“秘诀” 有三个:
深度神经网络、监督/强化学习、蒙特卡罗树搜索
。
深度神经网络是包含超过一个认知层的计算机神经网络。
对于人工智能而言,世界是被用数字的方式呈现的。
人们将人工智能设计出不同的“层”,来解决不同层级的认知任务。这种具备许多“层”的神经网络,被称为深度神经网络。AlphaGo包含两种深度神经网络:价值网络和策略网络。
价值网络
使得AlphaGo能够明晰局势的判断,左右全局“战略”,抛弃不合适的路线;
策略网络
使得AlphaGo能够优化每一步落子,左右局部“战术”,减少失误。两者结合在一起,使得AlphaGo不需要过于庞大的计算也能够走出精妙的棋局,就像人类一样。

AlphaGo与柯洁对弈中,Google团队依然由黄士杰博士代替AlphaGo落子。来自微博@Google黑板报
监督学习和强化学习是机器学习方式的不同种类
。监督学习
是指机器通过人类输入的信息进行学习,而
加强学习
是指机器自身收集环境中的相关信息作出判断,并综合成自己的“经验”。在初始阶段,AlphaGo收集研究者输入的大量棋局数据,学习人类棋手的下法,形成自己独特的判断方式。之后,在不计其数的自己与自己模拟对弈,以及每一次与人类棋手对弈中,AlphaGo都能并根据结果来总结并生成新的范式,实现自我提高。
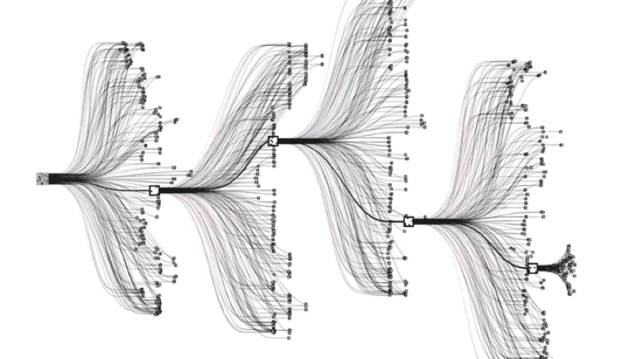
最后,蒙特卡洛树是一种搜索算法。AI在利用它进行决策判断时,会从根结点开始不断选择分支子结点,
通过不断的决策使得游戏局势向AI预测的最优点移动,直到模拟游戏胜利。
AI每一次的选择都会同时产生多个可能性,它会进行仿真运算,推断出可能的结果再做出决定。
 AlphaGo中的蒙特卡罗树搜索流程。图片来源:Nature
AlphaGo中的蒙特卡罗树搜索流程。图片来源:Nature
依赖于上述三大“武器”,AlphaGo成为了目前人类制造出来的最为优秀的围棋AI。连败人类棋手的胜绩就是明证。但除了它之外,世界各国也开发过不同的游戏AI,向围棋这一智力上的“绝对领域”发起挑战。
法国研发的
Crazy Stone
(狂石)
,日本研发的
Zen(天顶)
都曾是这一领域的翘楚。它们都曾经给人类造成过威胁,但从未像AlphaGo一样将最顶级的人类棋手打的一败涂地。在AlphaGo一举走红之后,人工智能界对围棋AI的研发热情空前高涨。
Zen的改良版
DeepZenGO
在2017年3月参加了日本举办的“世界最强棋手决定战”,先后负于中国棋手芈昱廷九段和韩国棋手朴廷桓九段后,战胜日本棋手井山裕太九段,取得第三名的成绩。
由中国腾讯公司研发的围棋AI
“
绝艺”(Fine Art)
于2016年3月后完成,同年8月23日首次战胜职业棋手。11月2日,绝艺战胜世界冠军江维杰九段。11月19日,绝艺与柯洁九段交手,取得了一胜一负的成绩。如今,绝艺对世界冠军和全国冠军的胜率,已经能够维持在90%以上了。
在多年的呕心沥血后,AlphaGo和一系列崛起的围棋AI一起成为了围棋界新的高峰。毋庸置疑,它们的下棋方式会改变人们目前对围棋下法的观念。许多曾经的定势将会被打破,新的格局即将开始。也许在若干年后的围棋教科书上,流传多年颠扑不破的真理将会被改写。可是,
花了那么多人力物力,研究者们想做的,就只是这样一个能够下赢人类的AI吗?
当然不是。

1997年纽约,与IBM深蓝电脑终
局对
弈开始时的加里·卡斯帕罗
夫。那是国际象棋AI第一次打败顶尖的人类。9年后,人类最后一次打败顶尖的国际象棋AI,国际象棋界从此接受了“人胜不过AI”的境遇。
Credit Stan Honda/Agence France-Presse — Getty Images
AlphaGo是一个标志。它的诞生,
意味着人们对人工智能的探索已经到达了一个新的阶段。
造就AlphaGo的学习模式,将被推广到各种领域,譬如面孔识别,语音识别等等。造就AlphaGo的核心技术,也许还能在其他领域同样的帮助我们。
尽管不如AlphaGo那么有名,但DeepMind研制的AI已经在为谷歌公司服务了。他们出品的人工智能帮助谷歌
减少了
40%
在机房冷却系统上的花费
。他们还希望能够与英国国家电网合作,利用人工智能将英国的能耗减少10%。
AlphaGo和它的同伴们能走多远?这件事,可能还要时间给我们答案。不管你愿不愿意承认,
人工智能的时代已经慢慢到来了
。
在国际象棋、在围棋、在你所知道的任何一个领域,都会慢慢涌现出能过代替人类的人工智能。
 柯洁在比赛前夜谈及人工智能。图片来源:新浪微博
柯洁在比赛前夜谈及人工智能。图片来源:新浪微博










