本文内容非商业用途可无需授权转载,请务必注明作者及本微信公众号、微博 @唐僧_huangliang,以便更好地与读者互动。
PCI Express® Base Specification Revision4.0 Version 1.0
下载链接
http://pan.baidu.com/s/1dFxqX9Z
(也可以点击本文底部“阅读原文”)
大家可能看到新闻了,
PCIe Express 4.0 v1.0
规范终于正式发布,此时距离我撰写支持
PCIe Gen4
的《
初探
OpenPOWER9
服务器设计:
x86
不再寂寞
》已经过去一年的时间。不知这是否意味着
POWER9
将会尽快正式发布了呢?
有意思的是,在
10
年前
PCIe 2.0
发布的时候,我写过一篇工作站的评测,提到了对于显卡
/GPU
的意义,也就是全速
x16
插槽。
6
年前,大约
Intel
发布第一代
Xeon E5
的半年之前,我也写过一篇评论,因为
LSI
已经提前推出了支持
PCIe 3.0
x8
的
6Gb/s SAS
控制器和
HBA
卡。
 这次应该是
9
月底就完成的,整个规范共
1293
页
这次应该是
9
月底就完成的,整个规范共
1293
页
今天,在
4.0
草案标准期间“偷跑”的板卡同样不少,不过
x16 lane
宽度的显卡
/GPU
似乎不是当前最紧迫的,毕竟
PCIe 3.0
的
8GT/s
每个
lane
有效带宽接近
1GB/s
全双工。而对于
SSD
和网卡就不同了。
56/100Gb
网卡、
NVMe SSD
渴望更大带宽
双端口
56Gb InfiniBand HCA
,用流行的
PCIe 3.0 x8
就存在瓶颈了;至于
100Gb
以太网等,如果不用
PCIe x16
单端口都发挥不出来,比如我在《
4
节点近
160
万
IOPS
:
SDS/
超融合测试不能只看数字
》测试平台中使用的
MellanoxConnentX-4
网卡。
至于
SSD
,目前主流的
NVMe
用的是
PCIe 3.0 x4
,实际效率能跑到
3.2GB/s
就不错了,参见《
Intel
发布
P4500
、
P4600 NVMeSSD
:规格释疑
》一文。除了少数高端企业级和发烧型号用
x8
接口之外,可以说单盘(卡)
IOPS
达到
70-80
万
x4
接口也开始出现瓶颈了。更何况未来会在存储阵列中应用的
双端口
U.2
SSD
,
x4 lane
会拆分成
2
个
x2
来使用。

这样的
M.2 SSD
转接卡,是当前提高整体带宽的一种选择
如上图,
4
个
M.2 PCIe x4
直通转接
PCIe x16
,对于有些
图形工作站等需要极高存储带宽的应用
是一种解决方案。上面的卡我在《
双
Xeon SP
只用一个风扇?
Precision7920
工作站散热设计解析
》中曾经提到过,随着
Dell
新一代工作站机型发布,同样的
Ultra-Speed Drive Duo/Quad
也可以通过
Intel RSTe vROC
选项支持
NVMe RAID0
、
1
。

如果平台(主板)升级到
PCIe 4.0
,这种
M.2
转接方案的带宽理论上也可以翻倍,当然估计一时半会
SSD
还达不到那么快。
而
PCIe 4.0
的普及进程却不是太乐观
,关于
Intel
发布不久的
Xeon Scalable
服务器
/
工作站平台我写过不少东西,这里随便列出一篇《
IntelXeon SP
服务器架构曝光:
Apache Pass
、
QuickAssist
》。据说
Intel
要等
2019
年发布的下一代
Xeon
平台才会支持
PCIe 4.0
,
POWER
由于指令集等方面原因难成主流,
AMD
又刚把
PCIe
控制器
lane
数量做上去(《
超越
Xeon
?
AMD Naples
服务器的理想与现实
》),估计短时间难以染指
4.0
。
GPU
提升
I/O
的另一个路子——
NVLink
除了
CPU
之外,
GPU
性能提升的速度似乎更快,不过
NVIDIA
自己搞出一套解决
I/O
互连的方式。
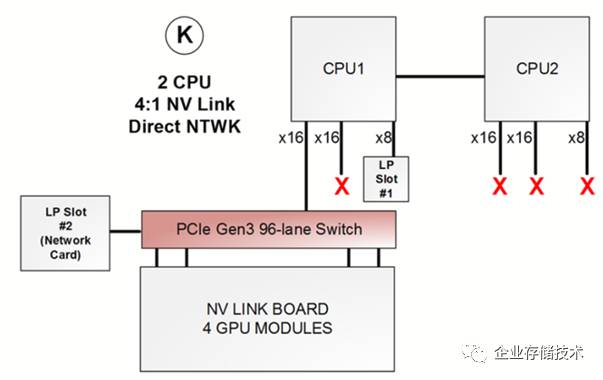
上面示意图是一款双
CPU+ 4 GPU
服务器,
1U
机箱支持
4
块
300W GPU
卡那种,我在《
九条大道通
GPU
:
HPC
服务器
PCIe
之灵活应用
》曾经介绍过它的
PCIe
直通和
Switch
有多种连接方式选择。
如今
NVIDIA
大力推广
NVLINK
,并且在一些应用中(比如
GPU
间显存频繁交换数据)性能提升明显,原有服务器机型也面临升级更新。上图所示
Dell PowerEdge C4130
就把
GPU
部分改造成一块
NVLINK
互连板,上面还是
4
个
GPU
模块,只在与
CPU
通信时才需要经过
PCIe
交换器,
GPU
间的带宽增大了
。我还没仔细研究,估计是从
PCIe
卡换成下图这种
SXM
模块吧。

1U 4
颗
GPU
、
2U 8
颗
GPU
是现在比较高的密度
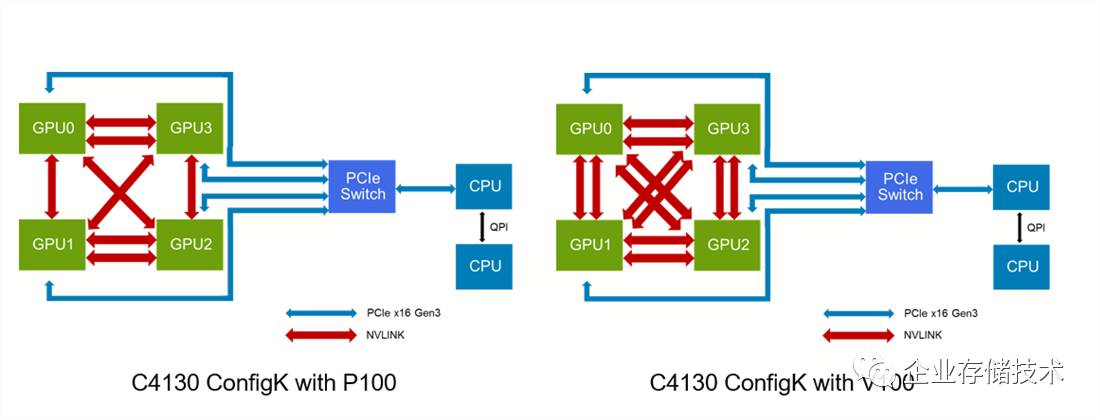
具体来说最新的
Tesla V100
支持的
NVLINK
链路比
P100
还增加了
2
条(
6 vs. 4
),只是听说这东西有些贵:)
Gen-Z
、
CAPI
等能撼动
PCIe
吗?
两个月前我还写过一点相关的:
《
Gen-Z
互连
(
上
)
:
Intel
缺席的内存中心架构
》
《
Gen-Z
互连
(
下
)
:第一步
25-100GB/s
、
PCI-SIG
的反应
》
还是更欣赏
TangJie
总说
过
的一个观点:“
这些新的
I/O
标准,如果想活下来,就必须大家联合起来
。
”
毕竟这么多年过去,
PCIe
生态太成熟了。先写到这里吧。
注
:本文只代表作者个人观点,与任何组织机构无关,如有错误和不足之处欢迎在留言中批评指正。
进一步交流
技术
,
可以
加我的
QQ/
微信:
490834312
。如果您想在这个公众号上分享自己的技术干货,也欢迎联系我:)
尊重知识,转载时请保留全文,并包括本行及如下二维码。感谢您的阅读和支持!《企业存储技术》微信公众号:
HL_Storage

长按二维码可直接识别关注
历史文章汇总
:
http://www.10tiao.com/author/index?authorId=691





