选自datasciencecentral
作者:William Vorhies
机器之心编译
参与:黄小天、蒋思源
有三种技术,可以带来更快、更简单、更廉价、更聪明的人工智能。今天,高性能计算,以及后来出现的量子计算机和神经形态计算已触手可及;并且,后两者正变革着人工智能和方兴未艾的深度学习。

人工智能与深度学习的三个问题
时间:训练一个 CNN 或 RNN 通常需要数周的时间。这还不算上为了达到所需的性能表现,花在定义问题以及编程深度网络时迭代成败上的数周甚至数月的时间。
成本:数百块 GPU 连续数周的计算成本高昂。从亚马逊云计算服务中租用 800 块 GPU 一周的时间花费在 120,000 美元。这还没开始算上人力成本。完成一个 AI 项目往往需要要占用最优秀人才数月、一年甚或更多的时间。
数据:由于缺乏足够数量的标注数据而使项目无法展开的情况比比皆是。由于无法以合理的价格获取训练数据,很多好创意被迫放弃。
因此,取得较好商业表现的多是图像处理、文本和语音识别,并且那些借力谷歌、IBM、微软和其他巨头的初创企业成果更多。
通向未来人工智能的三条赛道
如果你关注这一领域就会发现,我们已经使用 CNN 和 RNN 做了一些应用,但是超越这些应用的进展才刚开始。下一波的进展来自生成对抗网络和强化学习,并获得了问答机器(比如沃森)的一些帮助。我们最近的一篇文章对此作了很好的总结(详见:人工智能的三个阶段:我们正从统计学习走向语境顺应)。
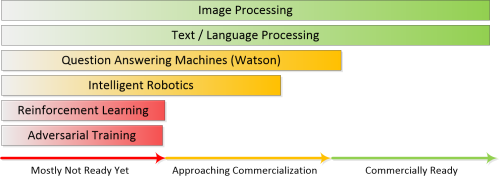
这是一个有关如何推动人工智能发展的最常见版本。这是日益复杂的深度神经网络,它与现在的 CNN 和 RNN 有着不同的架构。仅仅是让它们运行更快。
实际上未来可能相当不同。现在展现在我们面前的是基于完全不同技术的通向未来人工智能的三条赛道。它们是:
1. 高性能计算(HPC)
2. 神经形态计算(NC)
3. 量子计算(QC)
其中,高性能计算是本篇文章关注的焦点。芯片制造商以及以及谷歌等巨头正在开展竞争,争相打造深度学习专用芯片。
另外两个,神经形态计算(也被称为脉冲神经网络)和量子计算看起来似乎还需要几年。但事实是商用神经形态芯片和商用量子计算机已投入应用于机器学习之中。不管两者是冷是热,神经形态计算和量子计算都会使人工智能的未来之路变得更扑所迷离,但这是一件好事。
高性能计算(HPC)
高性能计算关注度最高。它使用我们已知的深度神经网络架构,并使其更快更容易被获取。通常这意味着两件事:更好的通用环境,比如 TensorFlow;更多地利用更大数据中心中的 GPU 和 FPGA,也许不久之后会出现更专业化的芯片。
现如今人工智能的新商业模式是「开源」。2016 年上半年,人工智能的每一个主要玩家都开源了其 AI 平台。这些竞争者在数据中心、云服务、人工智能 IP 上进行了大量投资。开源背后的策略很简单:平台用户最多者获胜。
同时,英特尔、英伟达及其他传统芯片制造商也正积极满足用户对于 GPU 的新需求,其他巨头如谷歌和微软则自己开发了全新的专属芯片,从而使其深度学习平台更快,更具吸引力。连同新近推出的 TPU,谷歌铁定了要把 TensorFlow 作为其主打的通用型解决方案。微软则在兜售非专属芯片 FPGA 的使用,并发布了 CNTK 2.0 完整版;它提供了 Java API 可直接整合 Spark,同时支持 Keras 代码。据称 CNTK 比 TensorFlow 更快更精确,且也提供 Python API。
整合 Spark 将持续成为一个重要的推动力。雅虎已实现了 TensorFlow 与 Spark 的整合。Spark 的主要商业供应商 Databricks 现在有其自己的开源工具包,以把深度学习与 Spark 相整合。这里的关键驱动力将至少解决三个障碍中的两个。这些进展将会使编程更快更简单,从而带来更可靠的结果,尤其是更快速的芯片将会使机器计算的原始时间变的更短。
问题是这些提升将会帮助我们到那一步(这和摩尔定律的局限性很像),是否可用于 GAN 和强化学习;答案很可能是,至少在今天我们知道如何使用这些深度学习架构。
神经形态计算(NC)或脉冲神经网络(SNN)
神经生态计算或脉冲神经网络是通向强人工智能的一条路径,它基于一些大脑运行的原理而设计,与深度神经网络的结构和原理有显著的不同。
神经形态计算最开始是由研究者发现大脑神经元并不是每一次都全部激活而启发。神经元将选择性信号沿着突触传播,并且数据实际上是以信号的潜在脉冲方式传播。实际上,这些信号是由一系列脉冲组成,所以研究者对信息是否编码在一系列脉冲的振幅、频率或延迟中做进一步探讨。
在现有的深度神经网络中,神经元根据相对简单的激活函数(如 Sigmod 或 ReLU 等)每一次都会全部激活。
神经形态计算相对于深度神经网络已经展示了一些巨大的提升:
因为并不会每一次都激活所有的神经元,所以大
早期案例展示了脉冲神经网络可以仅使用无监督技术(无标注)从环境中学习,而少量的样本可以令它们学习非常迅速。
神经形态计算可以从学习一个环境泛化到另一个环境,它能够记忆并且泛化,这真的是一个突破性的能力。
因为神经形态计算能效非常高,所以可以进行小型化。
所以转变这种基础架构能够解决深度学习如今面临的三个基础问题。更重要的是,如今我们能够购买和使用神经形态脉冲神经网络系统。这并不是遥远未来的一个技术。
BrainChip Holdings (Aliso Viejo, CA) 已经在拉斯维加斯最大的赌场应用了商业安防监控系统,并且它宣称还有一些其他应用也已经交付。在拉斯维加斯,该系统的功能就是通过标准摄像头的视频流自动监控 dealer 的错误。该系统完全通过观察学习游戏规则。BrainChip 表明它的 SNN 有 IP 专利保护,并借此推出了一系列赌博监控产品。
现如今有很多科技进步,但 SNN 是开发 AI 商业系统很有竞争力的选择。
量子计算
可能读者对量子计算并没有如下认识:
量子计算如今是可用的,Lockheed Martin 从 2010 开始就已经从事相关的商业运作。还有其他几家公司都在推出基于 D-Wave 量子计算机的商业应用,D-Wave 的量子计算机是第一个发展的商业市场。
今年五月,IBM 声称他们的量子计算机 IBM Q 现在已经可以投入商业中。在这是一种基于云端的订阅服务,它无疑将大大简化对这些昂贵且复杂的机器的访问。IBM 表示截止到目前,用户已经在 IBM Q 机器上进行了 30 万次实验。
谷歌和微软计划在两三年内发布他们的商业化量子机器,并整个作为独立的研究学术机构。
D-Wave 和其他一些独立的研究者已经引进了量子计算机的开源编程语言,他们希望可以对量子计算机编程更加容易。
量子计算机擅长于解决现有所有类型的优化问题,包括整套基于随机梯度下降的各类算法。量子计算机也很容易模拟受限玻尔兹曼机,它是很多深度神经网络架构中的一个,并且还可以用于深度学习结构中以像 CNN 那样解决图像分类问题。因为基础架构不一样,所以我们称其为量子神经网络(QNN)。
根据谷歌基准 2015 年的研究报告,D-Wave 量子计算机相对于传统计算机性能要优秀 108 倍,也即快 1 亿倍。谷歌工程主任 Hartmut Nevan 说:「D-Wave 在 1 秒中所做的,传统计算机需要花 1 万年计算」。
所以量子表征仍然是第三条通向强人工智能的道路,它同样克服了速度与成本问题。
三条道路
事实是神经形态计算和量子计算都是很有潜力的方向,它们都有可能令深度学习甚至是新型人工智能更快地运行。
首先是时间线。高性能计算如今正在持续发展,并在接下来几年都基于前面介绍的新型芯片而得到性能上的持续发展。然而,随后几年很大一部分实验室和数据中心都会由更先进的量子计算机和神经形态计算所替代。
像谷歌 TensorFlow 和微软 Cognitive Toolkit(CNTK)那样的深度学习平台正在发展,而其他竞争对手也在努力构建平台并获得用户。因此随着量子计算和神经形态计算的能力得到传播,这些平台都会适应它们。
神经形态脉冲神经网络(SNN)和量子计算现在仅仅在商业上出现,但它们都会赋予人工智能非凡的能力。
SNN 有希望成为强大的自学习者。通过更小的非标注训练集以及不同领域之间的知识迁移能力,极大地提升了效率。
量子计算机将彻底消除时间障碍,成本障碍最终也将降低,基于时间的解决方案从数月缩短至数分钟。重要的是当前使用的学习风格被称作增强型量子计算,因为它是基于当前的深度学习算法,并提升了其性能。然而将来会出现基于完全不同能力(为这些机器所独有)的全新类型的机器学习。
我的个人感觉是在量子计算和神经形态计算上,我们现在的处情和 2007 年很像,那一年谷歌的 Big Table(译者注:谷歌设计的分布式数据存储系统,用来处理海量数据的一种非关系型的数据库)变成了开源的 Hadoop。一开始我们确实不知道怎么对待它,但是三年之后 Hadoop 几乎主导了整个数据科学。我认为从今天开始,下一个三年也同样令人惊奇。
原文链接:http://www.datasciencecentral.com/profiles/blogs/the-three-way-race-to-the-future-of-ai-quantum-vs-neuromorphic-vs?platform=hootsuite
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]
点击阅读原文,查看机器之心官网↓↓↓










