一套稳健的代码体系,必须能够包容所有可能出现的错误情况并做出针对性处理,要想达到这个目标,务必要对异常捕获与容错处理有深入的了解和认识。
秉着初学者入门探索的心态,接下来的两篇我会陆续跟大家分享R语言与Python中所涉及到的主要异常捕获与容错处理机制。今天先分享异常及其捕获手段,下一篇会综合实战应用讲解如何在循环中绕过异常或者跳出循环。
R语言中的异常函数主要涉及两个:
tryCatch函数拥有类似Python中的try/expect那样相对完整的容错处理机制。一个完整的tryCatch容错函数,一般具有以下结构:
result tryCatch({
expr
}, warning = function(w) {
warning-handler-code
}, error = function(e) {
error-handler-code
}, finally = {
cleanup-code
})
right:http://raindu.com/
no: http://raindu.edu/
以上是我的个人博客地址,其中第一个网址是正确的,第二个是错误的(不存在的)。我们将这两个网址封装在一个向量里。
library("RCurl")
url "http://raindu.com/",
"http://raindu.edu/"
)
接下来使用getURL来进行网页请求。
getURL(url[1])

当你请求了正确的网址时,总是可以从输出中得到想要的内容。
getURL(url[2])
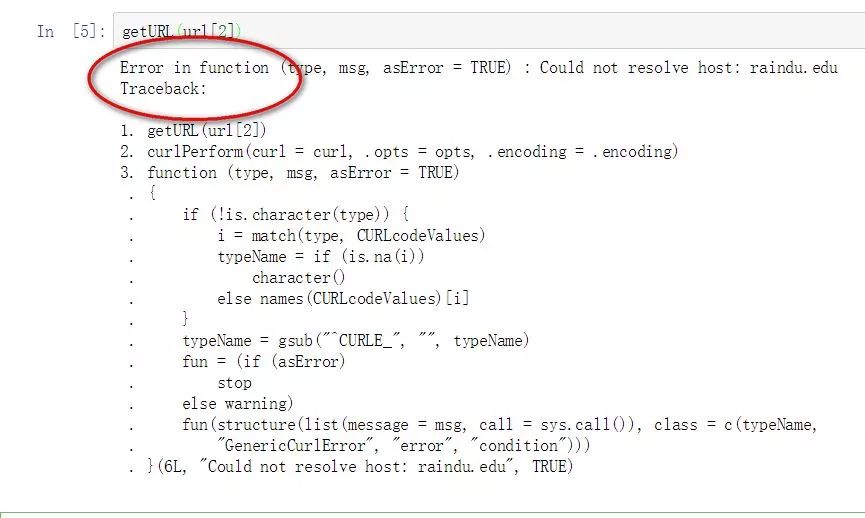
倘若不幸请求了不存在的网址(或者域名),编辑器直接抛出错误并中断程序(如果你没有针对异常进行处理的话)。
如果我们想要包装一下此异常,指定一个规则,如果网址存在则返回1,否则返回0,那么这两个条件要求我们必须明确的判断两次请求的状态。可以尝试着使用tryCatch函数来进行封装并捕获可能出现的异常。
resulttryCatch({
getURL(url[1])
}, error = function(e) {
print(e)
}, finally = {
print("程序运行完了!!!")
})

因为url[1]是正确的网址,所以以上代码运行之后,getURL(url[1])的得到的网页请求结果被保存在了result对象中,没有异常出现,所以也就没有打印异常信息,finally是无论出错与否都会执行的语句,所以finally语句也执行了。
再次打印result可以看到请求的网页内容。
那么换做url[2]的情况如何呢?
resulttryCatch({
getURL(url[2])
}, error = function(e) {
print(e)
}, finally = {
print("程序运行完了!!!")
})
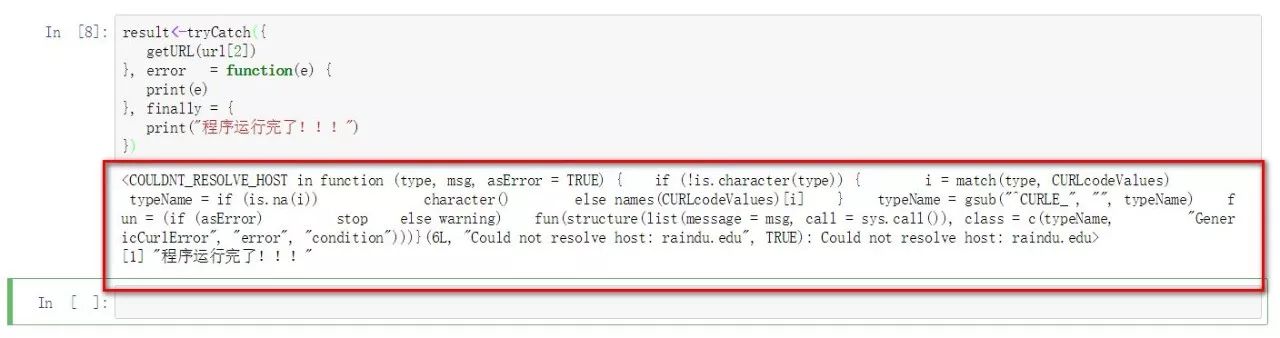
以上异常信息是我们截获到的,而非系统抛出的,从结果我们可以很清晰的看到tryCatch的异常处理逻辑:即倘若首段代码无异常,则正常运行并返回网页内容,如果出错,则首段代码放弃执行,进入异常模块(error)执行模块内语句,执行完毕之后则继续执行finally语句。
那么通常将两次任务结合结合起来,正确执行返回1,否则返回0。
for (i in url){
tryCatch({
result1)
}, error = function(e) {
print(0)
}, finally = {
print("程序运行完了!!!")
})
}
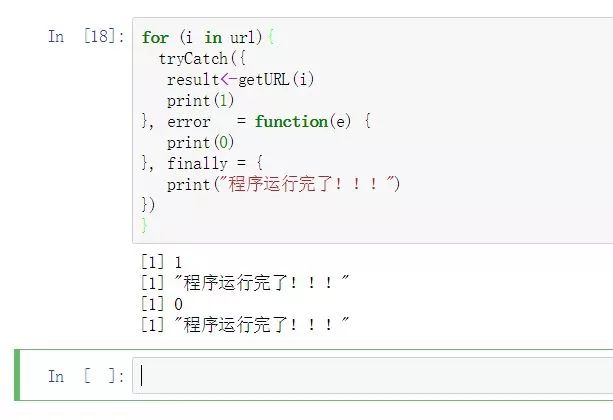
因为url中仅有两个网址,所以循环仅仅执行了两次,第一次返回1,说明请求成功了,tryCatch中的第一个模块语句所有语句都被执行了,第二次语句出现了错误,则函数直接切换到error模块,执行print(0),无论成功与否,两次程序都执行了finally中的print(“程序运行完了!!!”)语句。以上便是tryCatch中的异常铺货逻辑,只要你在程序中设置了正确的异常捕获机制,那么异常变回按照你所自定义的任务进行执行,否则异常会通过编辑器的错误信息弹出,并强制中断程序。
try函数的逻辑更为简单粗暴,它只是一个错误与否的判定器(理解粗浅不要见笑),我们需要根据try的结果中是否包含错误来进行逻辑判断,进而执行后续操作,相当于我们要人为构建error模块中的任务执行措施。
for (i in url){
Error try(getURL(i))
if(!'try-error' %in% class(Error)){
print("请求成功,请求状态为:1")
} else {
print("请求失败,请求状态为:0")
}
}
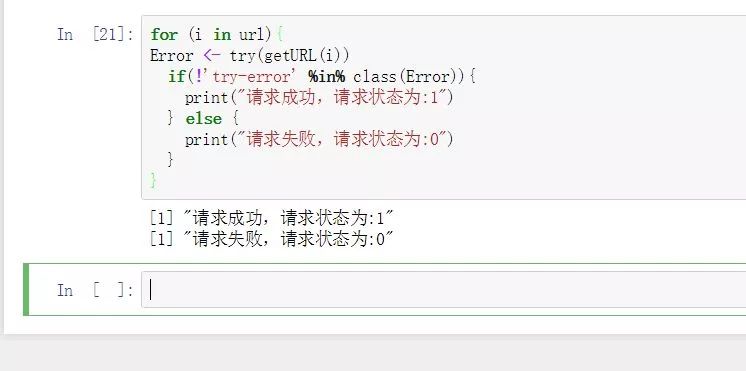
让我们再来对比一下tryCatch与try两种异常捕获机制的差别,tryCatch的tryCatch/warning/error/finally机制是无需定义的封装一体化的容错处理机制,而try的异常捕获机制则是我们通过if判断try语句的结果中是否包含错误类型,通过if/else来进行判断病处理的,所以很明显,tryCatch机制更加健壮,可以告知我们更多错误信息,设置更多后续处理时间,并且无需自定义关键词。而try则相对羸弱一些,我们需要自己造轮子。
所以说如果你不想具体纠缠于错误类型和内部机制,使用try会更简洁一些,但是需要自己做if判断是遇到错误跳出还是绕过(至于如何在循环中跳出错误或者绕过错误,敬请收看下文),而tryCatch则具有更加完善的捕获与处理机制,更加智能一些。
Python
Python的中错误处理仅以try/except/else/finally为例进行简单梳理(至于更为高阶的异常捕获与容错处理,可以参见官方文档)。
Python中的异常捕获机制的完整流程如上所列。try的含义与R语言中的tryCatch第一个子模块一样,是等待排错的代码段。
except则与R中的error模块异曲同工。倘若try模块语句出错,则错误代码块停止执行,直接切入except模块执行异常处理。
else倘若try模块无异常,则程序执行完try模块之后就会直接跳到else模块执行该模块语句,否则执行执行expect模块。
finally模块则与R语言中的finally语句一样,无论是否出错,最后都会执行(只要勇于文件读写)。
这样对标起来,其实Python中的try系统也是很好理解的。
R Python
tryCatch try
error except
finally finally
省略Python中的else模块(感觉这个模块用的很少),可以看到R语言与Python中的异常捕获逻辑是想通的。
但是Python的try模块中,对于except模块的错误类型非常讲究,一个try系统可以容纳多个子异常(except语句),异常语句中可以不指定异常类型(捕获所有异常),也可以指定异常类型(原则是多条子异常,子类在前,父类在后)。
http://www.cnblogs.com/rubylouvre/archive/2011/06/22/2086644.html
这篇文章对异常的树结构进行了很好地梳理,可以参考。本着简单实用的原则,本篇文章不对异常的细节做过多探讨。
from urllib.request import Request,urlopen
from urllib import error
url=["http://raindu.com/","http://raindu.edu/"]
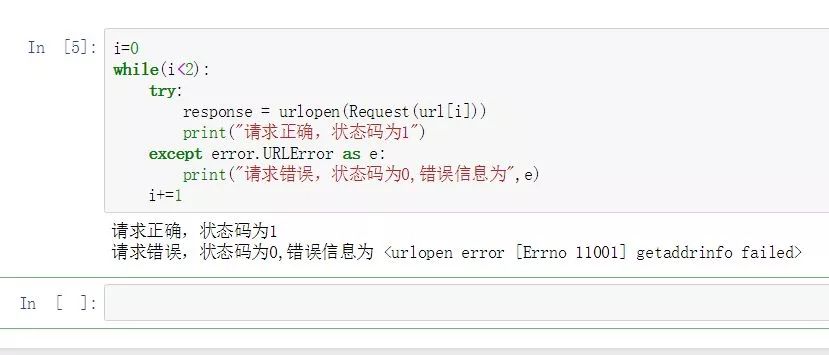
i=0
while(i<2):
try:
response = urlopen(Request(url[i]))
print("请求正确,状态码为1")
except error.URLError as e:
print("请求错误,状态码为0,错误信息为",e)
i+=1
当然也可以用for循环来写,毕竟for和while是可以相互替代的操作。
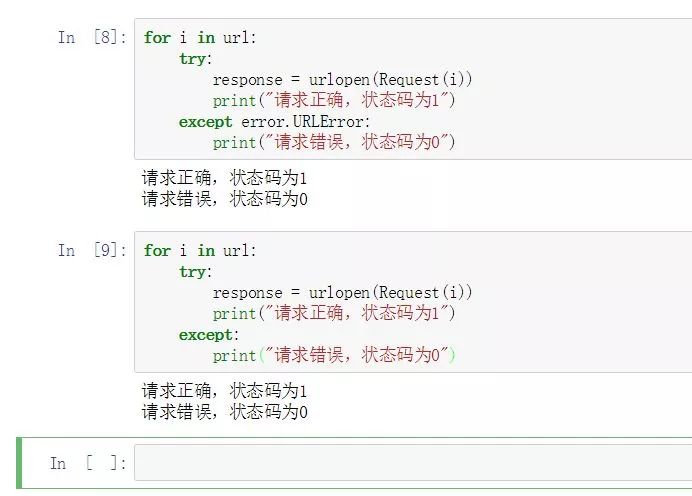
for i in url:
try:
response = urlopen(Request(i))
print("请求正确,状态码为1")
except error.URLError as e:
print("请求错误,状态码为0,错误信息为",e)

事实上,except模块的错误信息并不是必须的,你甚至可以省略掉错误信息,这样仍然可以自定义出错状态下应该执行的操作,只是无法获知详细的错误信息而已。
for i in url:
try:
response = urlopen(Request(i))
print("请求正确,状态码为1")
except error.URLError:
print("请求错误,状态码为0")
for i in url:
try:
response = urlopen(Request(i))
print("请求正确,状态码为1")
except:
print("请求错误,状态码为0")
以上便是Python中的异常捕获机制,想要了解详细的except模块使用技巧,以及诸多错误类型的内含和差异,还需要进一步参考官文档。
https://docs.python.org/3/tutorial/errors.html
至于是实际应用场合,如何在循环中绕过错误记录,跳出指定错误,下篇文章会使用真实案例进行情景介绍,敬请期待!
在线课程请点击文末原文链接:
往期案例数据请移步本人GitHub:
https://github.com/ljtyduyu/DataWarehouse/tree/master/File

左手用R右手Python系列(I): 字符串格式化输出
左手用R右手Python系列(II): 数据合并与追加
左手用R右手Python系列(III): 数据塑型与长宽转换
左手用R右手Python系列(IV): 因子变量与分类重编码
左手用R右手Python系列(V): 数据切片与索引
左手用R右手Python系列(VI): 变量计算与数据聚合
左手用R右手Python系列(VII): 排序
左手用R右手Python系列(VIII):数据去重与缺失值处理
左手用R右手Python系列(IX):字符串合并与拆分
左手用R右手Python系列(X): 统计描述与列联分析
左手用R右手Python系列(XI): 相关性分析
左手用R右手Python系列(XII): 空间数据可视化与数据地图
左手用R右手Python系列(XIII): 字符串处理与正则表达式
左手用R右手Python系列(XIV): 日期与时间处理
左手用R右手Python系列(XV): 模拟登陆教务系统
左手用R右手Python系列(XVI):XPath表达式与网页解析
左手用R右手Python系列(XVII): CSS表达式与网页解析
左手用R右手Python系列(XVIII): CSS网页解析实战
左手用R右手Python系列(XIX): 趣直播课程抓取实战
左手用R右手Python系列(XX): 任务进度管理
如需转载请联系EasyCharts团队!
微信后台回复“转载”即可!
【书籍推荐】《Excel 数据之美--科学图表与商业图表的绘制》
【手册获取】国内首款-数据可视化参考手册:专业绘图必备
【必备插件】 EasyCharts -- Excel图表插件
【网易云课堂】 Excel 商业图表修炼秘笈之基础篇










