(点击上方公众号,可快速关注)
作者:张铁蕾
zhangtielei.com/posts/blog-redis-robj.html
如有好文章投稿,请点击 → 这里了解详情
本系列基于 Redis 3.2 分支
本文是《Redis内部数据结构详解》系列的第三篇,讲述在Redis实现中的一个基础数据结构:robj。
那到底什么是robj呢?它有什么用呢?
从Redis的使用者的角度来看,一个Redis节点包含多个database(非cluster模式下默认是16个,cluster模式下只能是1个),而一个database维护了从key space到object space的映射关系。这个映射关系的key是string类型,而value可以是多种数据类型,比如:string, list, hash等。我们可以看到,key的类型固定是string,而value可能的类型是多个。
而从Redis内部实现的角度来看,在前面第一篇文章中,我们已经提到过,一个database内的这个映射关系是用一个dict来维护的。dict的key固定用一种数据结构来表达就够了,这就是动态字符串sds。而value则比较复杂,为了在同一个dict内能够存储不同类型的value,这就需要一个通用的数据结构,这个通用的数据结构就是robj(全名是redisObject)。举个例子:如果value是一个list,那么它的内部存储结构是一个quicklist(quicklist的具体实现我们放在后面的文章讨论);如果value是一个string,那么它的内部存储结构一般情况下是一个sds。当然实际情况更复杂一点,比如一个string类型的value,如果它的值是一个数字,那么Redis内部还会把它转成long型来存储,从而减小内存使用。而一个robj既能表示一个sds,也能表示一个quicklist,甚至还能表示一个long型。
robj的数据结构定义
在server.h中我们找到跟robj定义相关的代码,如下(注意,本系列文章中的代码片段全部来源于Redis源码的3.2分支):
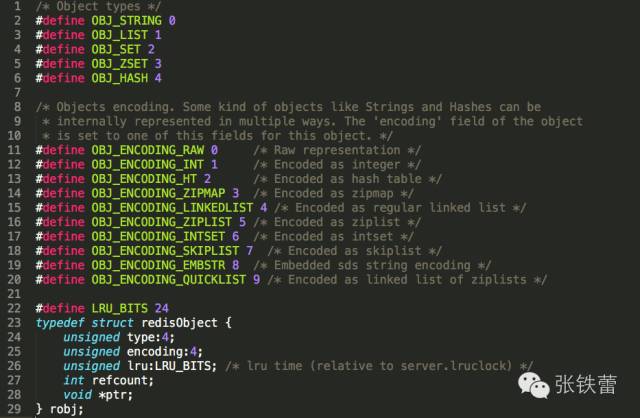
一个robj包含如下5个字段:
type: 对象的数据类型。占4个bit。可能的取值有5种:OBJ_STRING, OBJ_LIST, OBJ_SET, OBJ_ZSET, OBJ_HASH,分别对应Redis对外暴露的5种数据结构(即我们在第一篇文章中提到的第一个层面的5种数据结构)。
encoding: 对象的内部表示方式(也可以称为编码)。占4个bit。可能的取值有10种,即前面代码中的10个OBJ_ENCODING_XXX常量。
lru: 做LRU替换算法用,占24个bit。这个不是我们这里讨论的重点,暂时忽略。
refcount: 引用计数。它允许robj对象在某些情况下被共享。
ptr: 数据指针。指向真正的数据。比如,一个代表string的robj,它的ptr可能指向一个sds结构;一个代表list的robj,它的ptr可能指向一个quicklist。
这里特别需要仔细察看的是encoding字段。对于同一个type,还可能对应不同的encoding,这说明同样的一个数据类型,可能存在不同的内部表示方式。而不同的内部表示,在内存占用和查找性能上会有所不同。
比如,当type = OBJ_STRING的时候,表示这个robj存储的是一个string,这时encoding可以是下面3种中的一种:
OBJ_ENCODING_RAW: string采用原生的表示方式,即用sds来表示。
OBJ_ENCODING_INT: string采用数字的表示方式,实际上是一个long型。
OBJ_ENCODING_EMBSTR: string采用一种特殊的嵌入式的sds来表示。接下来我们会讨论到这个细节。
再举一个例子:当type = OBJ_HASH的时候,表示这个robj存储的是一个hash,这时encoding可以是下面2种中的一种:
本文剩余主要部分将针对表示string的robj对象,围绕它的3种不同的encoding来深入讨论。前面代码段中出现的所有10种encoding,在这里我们先简单解释一下,在这个系列后面的文章中,我们应该还有机会碰到它们。
OBJ_ENCODING_RAW: 最原生的表示方式。其实只有string类型才会用这个encoding值(表示成sds)。
OBJ_ENCODING_INT: 表示成数字。实际用long表示。
OBJ_ENCODING_HT: 表示成dict。
OBJ_ENCODING_ZIPMAP: 是个旧的表示方式,已不再用。在小于Redis 2.6的版本中才有。
OBJ_ENCODING_LINKEDLIST: 也是个旧的表示方式,已不再用。
OBJ_ENCODING_ZIPLIST: 表示成ziplist。
OBJ_ENCODING_INTSET: 表示成intset。用于set数据结构。
OBJ_ENCODING_SKIPLIST: 表示成skiplist。用于sorted set数据结构。
OBJ_ENCODING_EMBSTR: 表示成一种特殊的嵌入式的sds。
OBJ_ENCODING_QUICKLIST: 表示成quicklist。用于list数据结构。
我们来总结一下robj的作用:
string robj的编码过程
当我们执行Redis的set命令的时候,Redis首先将接收到的value值(string类型)表示成一个type = OBJ_STRING并且encoding = OBJ_ENCODING_RAW的robj对象,然后在存入内部存储之前先执行一个编码过程,试图将它表示成另一种更节省内存的encoding方式。这一过程的核心代码,是object.c中的tryObjectEncoding函数。

这段代码执行的操作比较复杂,我们有必要仔细看一下每一步的操作:
#define sdsEncodedObject(objptr) (objptr->encoding == OBJ_ENCODING_RAW || objptr->encoding == OBJ_ENCODING_EMBSTR)
第3步检查,检查refcount。引用计数大于1的共享对象,在多处被引用。由于编码过程结束后robj的对象指针可能会变化(我们在前一篇介绍sdscatlen函数的时候提到过类似这种接口使用模式),这样对于引用计数大于1的对象,就需要更新所有地方的引用,这不容易做到。因此,对于计数大于1的对象不做编码处理。
试图将字符串转成64位的long。64位的long所能表达的数据范围是-2^63到2^63-1,用十进制表达出来最长是20位数(包括负号)。这里判断小于等于21,似乎是写多了,实际判断小于等于20就够了(如果我算错了请一定告诉我哦)。string2l如果将字符串转成long转成功了,那么会返回1并且将转好的long存到value变量里。
在转成long成功时,又分为两种情况。
第一种情况:如果Redis的配置不要求运行LRU替换算法,且转成的long型数字的值又比较小(小于OBJ_SHARED_INTEGERS,在目前的实现中这个值是10000),那么会使用共享数字对象来表示。之所以这里的判断跟LRU有关,是因为LRU算法要求每个robj有不同的lru字段值,所以用了LRU就不能共享robj。shared.integers是一个长度为10000的数组,里面预存了10000个小的数字对象。这些小数字对象都是encoding = OBJ_ENCODING_INT的string robj对象。
第二种情况:如果前一步不能使用共享小对象来表示,那么将原来的robj编码成encoding = OBJ_ENCODING_INT,这时ptr字段直接存成这个long型的值。注意ptr字段本来是一个void *指针(即存储的是内存地址),因此在64位机器上有64位宽度,正好能存储一个64位的long型值。这样,除了robj本身之外,它就不再需要额外的内存空间来存储字符串值。
接下来是对于那些不能转成64位long的字符串进行处理。最后再做两步处理:
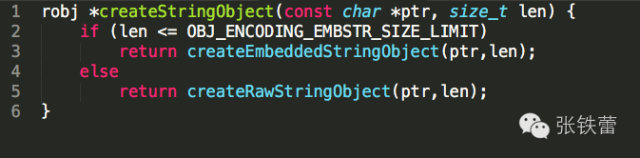
如果字符串长度足够小(小于等于OBJ_ENCODING_EMBSTR_SIZE_LIMIT,定义为44),那么调用createEmbeddedStringObject编码成encoding = OBJ_ENCODING_EMBSTR;
如果前面所有的编码尝试都没有成功(仍然是OBJ_ENCODING_RAW),且sds里空余字节过多,那么做最后一次努力,调用sds的sdsRemoveFreeSpace接口来释放空余字节。
其中调用的createEmbeddedStringObject,我们有必要看一下它的代码:

createEmbeddedStringObject对sds重新分配内存,将robj和sds放在一个连续的内存块中分配,这样对于短字符串的存储有利于减少内存碎片。这个连续的内存块包含如下几部分:
16个字节的robj结构。
3个字节的sdshdr8头。
最多44个字节的sds字符数组。
1个NULL结束符。
加起来一共不超过64字节(16+3+44+1),因此这样的一个短字符串可以完全分配在一个64字节长度的内存块中。
string robj的解码过程
当我们需要获取字符串的值,比如执行get命令的时候,我们需要执行与前面讲的编码过程相反的操作——解码。
这一解码过程的核心代码,是object.c中的getDecodedObject函数。
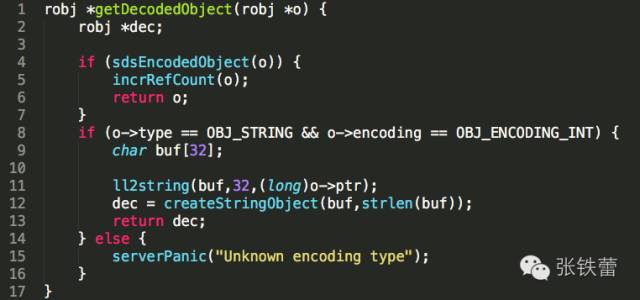
这个过程比较简单,需要我们注意的点有:
编码为OBJ_ENCODING_RAW和OBJ_ENCODING_EMBSTR的字符串robj对象,不做变化,原封不动返回。站在使用者的角度,这两种编码没有什么区别,内部都是封装的sds。
编码为数字的字符串robj对象,将long重新转为十进制字符串的形式,然后调用createStringObject转为sds的表示。注意:这里由long转成的sds字符串长度肯定不超过20,而根据createStringObject的实现,它们肯定会被编码成OBJ_ENCODING_EMBSTR的对象。createStringObject的代码如下:
再谈sds与string的关系
在上一篇文章中,我们简单地提到了sds与string的关系;在本文介绍了robj的概念之后,我们重新总结一下sds与string的关系。
确切地说,string在Redis中是用一个robj来表示的。
用来表示string的robj可能编码成3种内部表示:OBJ_ENCODING_RAW, OBJ_ENCODING_EMBSTR, OBJ_ENCODING_INT。其中前两种编码使用的是sds来存储,最后一种OBJ_ENCODING_INT编码直接把string存成了long型。
在对string进行incr, decr等操作的时候,如果它内部是OBJ_ENCODING_INT编码,那么可以直接进行加减操作;如果它内部是OBJ_ENCODING_RAW或OBJ_ENCODING_EMBSTR编码,那么Redis会先试图把sds存储的字符串转成long型,如果能转成功,再进行加减操作。
对一个内部表示成long型的string执行append, setbit, getrange这些命令,针对的仍然是string的值(即十进制表示的字符串),而不是针对内部表示的long型进行操作。比如字符串”32”,如果按照字符数组来解释,它包含两个字符,它们的ASCII码分别是0x33和0x32。当我们执行命令setbit key 7 0的时候,相当于把字符0x33变成了0x32,这样字符串的值就变成了”22”。而如果将字符串”32”按照内部的64位long型来解释,那么它是0x0000000000000020,在这个基础上执行setbit位操作,结果就完全不对了。因此,在这些命令的实现中,会把long型先转成字符串再进行相应的操作。由于篇幅原因,这三个命令的实现代码这里就不详细介绍了,有兴趣的读者可以参考Redis源码:
t_string.c中的appendCommand函数;
biops.c中的setbitCommand函数;
t_string.c中的getrangeCommand函数。
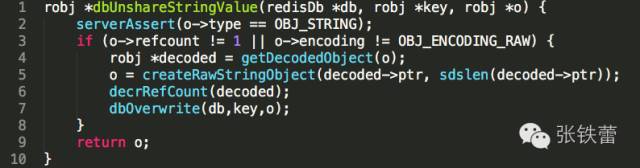
值得一提的是,append和setbit命令的实现中,都会最终调用到db.c中的dbUnshareStringValue函数,将string对象的内部编码转成OBJ_ENCODING_RAW的(只有这种编码的robj对象,其内部的sds 才能在后面自由追加新的内容),并解除可能存在的对象共享状态。这里面调用了前面提到的getDecodedObject。
robj的引用计数操作
将robj的引用计数加1和减1的操作,定义在object.c中:
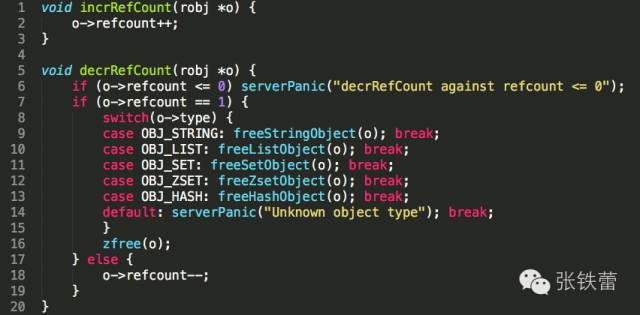
我们特别关注一下将引用计数减1的操作decrRefCount。如果只剩下最后一个引用了(refcount已经是1了),那么在decrRefCount被调用后,整个robj将被释放。
注意:Redis的del命令就依赖decrRefCount操作将value释放掉。
经过了本文的讨论,我们很容易看出,robj所表示的就是Redis对外暴露的第一层面的数据结构:string, list, hash, set, sorted set,而每一种数据结构的底层实现所对应的是哪个(或哪些)第二层面的数据结构(dict, sds, ziplist, quicklist, skiplist, 等),则通过不同的encoding来区分。可以说,robj是联结两个层面的数据结构的桥梁。
本文详细介绍了OBJ_STRING类型的字符串对象的底层实现,其编码和解码过程在Redis里非常重要,应用广泛,我们在后面的讨论中可能还会遇到。现在有了robj的概念基础,我们下一篇会讨论ziplist,以及它与hash的关系。
觉得本文有收获?请转发分享给更多人
关注「数据库开发」,提升 DB 技能











