
这将是PaddlePaddle系列教程的开篇,属于非官方教程。既然是非官方,自然会从一个使用者的角度出发,来教大家怎么用,会有哪些坑,以及如何上手并用到实际项目中去。
我之前写过一些关于tensorflow的教程,在我的简书上可以找到,非常简单基础的一个教程,但是备受好评,因为国内实在是很难找到一个系列的关于这些深度学习框架的教程。因此在这里,我来给PaddlePaddle也写一个类似的教程,不复杂,三行代码入门。
三行代码PaddlePaddle从入门到精通
PaddlePaddle是百度大力推出的一个框架,不得不说相比于tensorflow,PaddlePaddle会简单很多,接下来我会细说。同时百度在人工智能方面的功底还是非常深厚,我曾经在腾讯实习,类似于AT这样的公司,甚至没有一个非常成型的框架存在。
既然是三行代码精通PaddlePaddle,那么得安装一下PaddlePaddle。就目前来说,最好的办法是build from source。步骤如下 (
注意,这里是CPU版本,GPU版本的源码编译过程后续补充,我们先用CPU来熟悉API
):

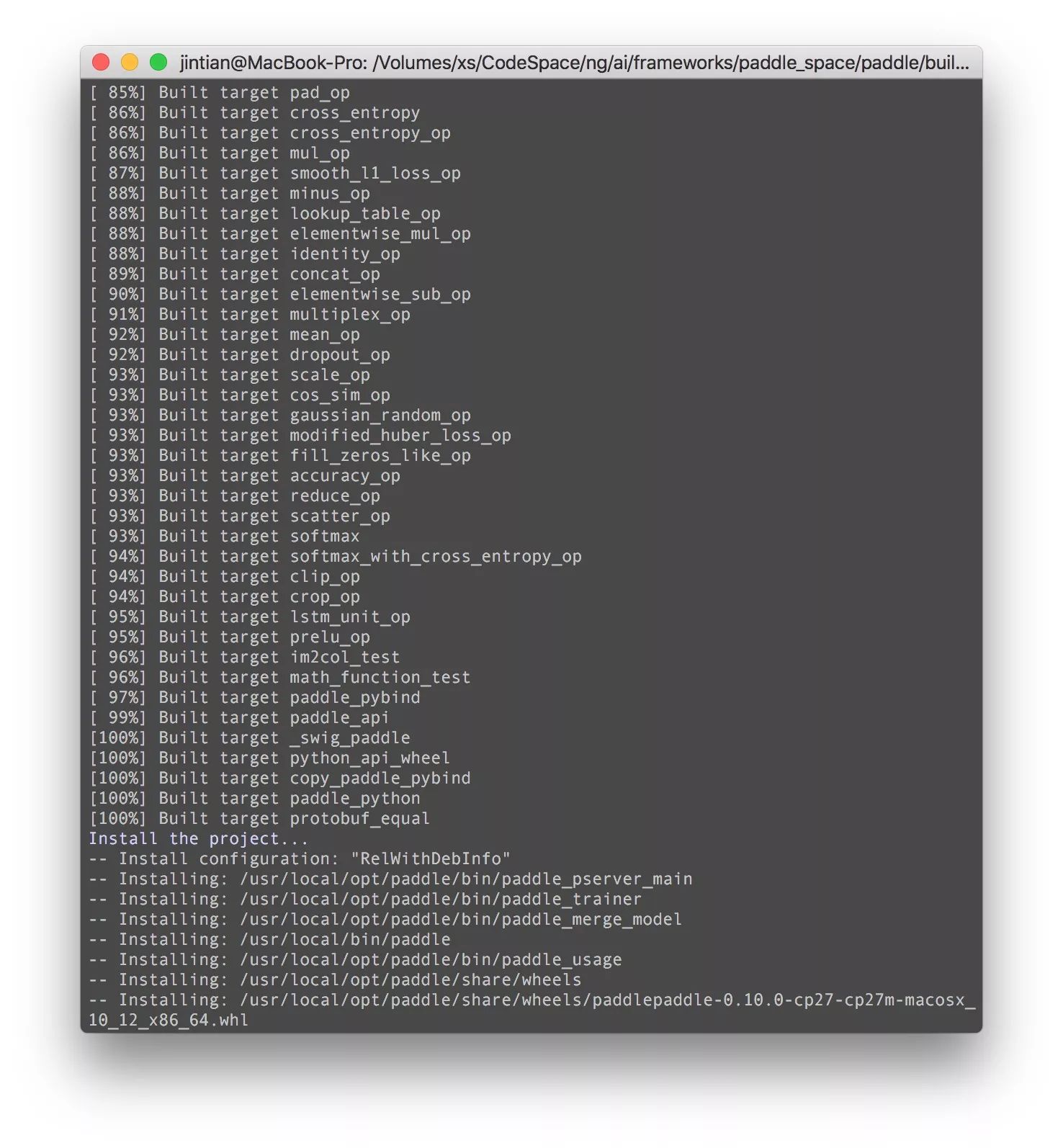
好了,看上去应该算是安装完了。接下来我们用三行代码来测试一下?
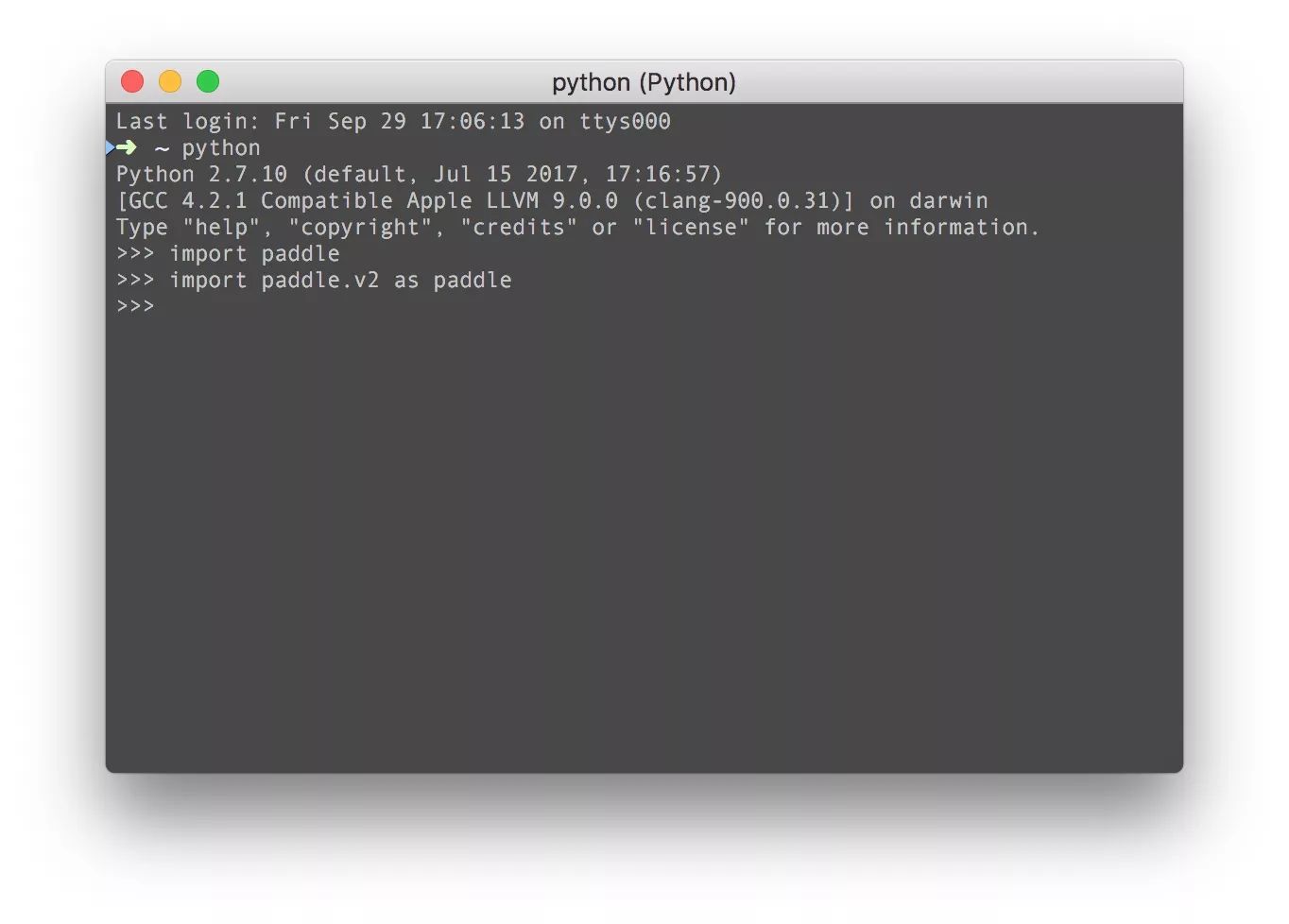
PaddlePaddle在python API上0.10有较大的变化,所以直接import一下v2版本的API。如果可以说明PaddlePaddle安装没有问题。这里赞一下百度的技术功底和用户体验,这尼玛要是caffe或者caffe2编译出错概率100%不说,python安装了也不能import,PaddlePaddle一步到位,非常牛逼。
闲话不多说,直接三行代码来熟悉一下PaddlePaddle的API。
三行代码来了
接下来要做的事情是,用PaddlePaddle搭建一个3层MLP网络,跑一个二维的numpy随机数据,来了解一下PaddlePaddle从数据喂入到训练的整个pipeline吧。
首先我们这个教程先给大家展示一个图片分类器,用到的数据集是Stanford Dogs 数据集, 下载链接, 大概800M, 同时下载一下annotations, 大概21M。下载好了我们用一个paddle_test的文件夹来做这个教程吧。

把所有的images 和 annotations扔到data里面去,解压一下:

顺便说一下,这里的annotations是为后面用paddlepaddle做分割做准备,本次分类任务,只需要一个images.tar就可以了,所有图片被放在了该类别的文件夹下面,以后处理其他分类任务时,只需要把不同类别放在文件夹就OK了,甚至不用改代码,非常方便,这比MXNet要有道理很多,多数情况下我们根本不需要海量图片训练,也没有必要搞个什么imrecord的数据格式,MXNet导入图片真心蛋疼,没有Pytorch方便,但是Pytorch得运行速度堪忧。
OK,将images.tar解压,会得到120个文件夹,也就是120个类别,每个类别里面都是一种狗狗图片。比如这张是一只 Beagle:

我们现在要来处理一下这些蠢狗。
开始写三行代码
好了,开始写三行代码了.
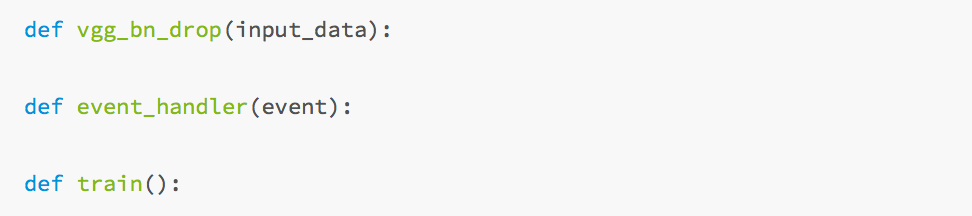
实际上PaddlePaddle的使用也就是三行代码的事情,首先是网络构建,这里我们构建一个VGG网络,其次是event的处理函数,这个机制是PaddlePaddle独有的,PaddlePaddle把所有的训练过程都包装成了一个trainer,然后调用这个event_handler来处理比如打印loss信息这样的事情。OK,我们一步一步来,先来看一下train的过程把:

PaddlePaddle的网络训练流程分为几个步骤:










