来源:economictimes;minimaxir.com
作者:Max Woolf
编译:文强
【新智元导读】英特尔与英伟达在数据中心市场激烈竞争:截止 4 月 30 日,英伟达的收入同比增长了 48%,达到 19.4 亿美元;但数据表明,英特尔不仅没有失去数据中心市场,地位反而更加稳固。另一方面,在个人训练深度学习模型时,也会在云端 CPU 和 GPU 间做出选择。前苹果工程师 Max Woolf 做了测评——由于谷歌云平台的收费规则,在有些情况下,使用 CPU 比 GPU 在经济上更划算。

英特尔和英伟达正在新的市场——蒸蒸日上的数据中心上展开竞争,而其中核心的部分自然是人工智能(AI)。截止 4 月 30 日,英伟达的收入同比增长了 48%,达到 19.4 亿美元。其中,在 GPU 需求的刺激下,数据中心业务收入大幅增长,本财年第一季获得 4.09 亿元收入,同比增长 186%。
英伟达数据中心收入同比增长 186%,但英特尔占 CPU 处理器市场出货量 95.7%
谷歌、亚马逊、微软、Facebook、IBM 和阿里巴巴等大公司都在其数据中心使用英伟达的 Tesla GPU 为其机器学习应用加速,以分析从云端收集的数据,并从中获得洞察。“我们见证了 PC 时代,随后是移动时代,现在是 AI 时代,”英伟达副总裁 Vishal Dhupar 说:“以前只被视为游戏技术,现在 GPU 开始进入数据中心,推动围绕机器学习和人工智能(AI)的各项举措。”
IDC 企业计算研究副总裁 Rajnish Arora 说:“GPU 的出现有助于重新定义许多高性能应用程序的系统设计概念,无论是在商业还是非商业领域。”
这是否意味着英特尔即将失去数据中心空间的市场份额?
不太可能。

“我们不认为英特尔正在失去服务器 CPU 市场的份额……这些数据清楚地表明,英特尔已经巩固了其在服务器市场的占有率和市场份额。”Arora说。现在,英特尔 CPU 在全球数据中心都有使用,占到了 2016 年发货量的 95.7%,几近垄断程度。
英特尔也在 AI 上投入了大量资金,收购初创公司来将 AI 和高性能计算(HPC)能力融入即将推出的芯片中。2015 年,英特尔以 167 亿美元的金额收购了 Altera,后者专门制造可针对 AI 和机器学习进行优化的可编程器件。其后,英特尔收购了深度学习初创公司 Nervana Systems,以加强 AI 的具体解决方案。英特尔将在今年晚些时候开始销售名为“Knights Mill”的新芯片,面向日渐庞大的机器学习市场。英特尔还在开发名为“Knights Crest”的芯片,专门用于加速深度神经网络。
英特尔实验室研究员 Pradeep Dubey 表示:“竞争一直存在……我们正在优化我们的机器学习和深度学习应用芯片,因为这对我们来说是一个巨大的机会,今年将有 4 个新的处理器发布。这些产品将在数据中心市场上与英伟达 GPU 进行竞争。”
在谷歌云训练深度学习模型,价格上 CPU 比 GPU 更划算
数据中心的大战下,个人使用云端 CPU 和 GPU 的情况前苹果软件工程师 Max Woolf 一直在使用 Keras 和 TensorFlow 做些个人的深度学习项目。他日前发表博文,得出了一个意外的结果:
由于谷歌云平台的收费规定,做深度学习项目有时候用 CPU 比 GPU 更划算。
Max 在他的文章里写道,使用亚马逊 EC2 和 Google Compute Engine 等云服务训练深度学习模型都不是免费的,因此关注成本效益十分重要。他在更便宜的 CPU 上做深度学习后发现,训练速度只降低了一点点。于是,Max 对云端 CPU 和 GPU 两种虚拟机的定价机制做了深入分析,看看 CPU 是否更适合他的需求。
Google Compute Engine(GCE)上,GPU 虚拟机的价格是 0.745 美元/小时起步。几个月前,谷歌宣布了在英特尔 Skylake CPU 架构上的 CPU 虚拟机,最高可达 64 核。这些虚拟机能以权限很低的方式提供,在 GCE 上最多持续 24 小时(可以随时终止,但极少发生)。由于 GCE 按时间分享计算资源,虚拟机权限较低,就可以被物理机器上其他虚拟机给挤掉,之后拿不到计算资源。但也正因如此,这些虚拟机的价格仅是普通虚拟机的 20% 左右。
算起来,这些低权限 Skylake CPU 虚拟机的价格是 0.509 美元/小时,相当于普通 GPU 虚拟机的 2/3。
如果用这些 CPU 虚拟机训练模型,速度与 GPU 可比(稍微差一点也行),那么用 CPU 在经济上就比用 GPU 更加划算。当然,这个假设成立的前提是 GCE 以 100% 的效率工作;而要是 GCE 没有达到 100%(这是很可能的情况),省的钱就更多了。而且,同样配置的 32 核 CPU 虚拟机,价格是 0.254 美元/小时,16 核的是 0.127 美元/小时,以此类推。
Max 提出了问题:现在还没有用大量 CPU 做深度学习库的基准,因为大家都直奔 GPU 而去;但是,有没有可能用 CPU 的经济效益比 GPU 更高呢?
下面我们就来看一下 Max 测评的结果。
1. 安装配置
Max Woolf 此前已经写过基准测试的脚本(参见 https://github.com/minimaxir/deep-learning-cpu-gpu-benchmark)和其他所需的代码。
此外,按照说明从 pip 安装 TensorFlow 后,训练模型时会出现下面的警告:

因此,Max 从源码编写了 TensorFlow,做了其他修改,发现警告没有了,并且训练时间也有所提升。这种情况用 cmp 表示。
最后,Max 在 GCE 平台测试了以下 3 种使用情况:
Tesla K80 GPU 虚拟机
64 核 Skylake CPU 虚拟机,用 pip 安装 TensorFlow(还测试了 8/16/32 核)
64 核 Skylake CPU 虚拟机,用 cmp 编写的 TensorFlow(以及 8/16/32 核的情况)
2. 结果
1)分类任务:使用 MNIST 数据集的手写数字,用多层感知机(MLP)架构,其中是密集的完全连接层。结果当然是训练时间更少的更好。水平虚线下方的所有配置均优于 GPU;虚线以上的所有配置都比 GPU 更差。
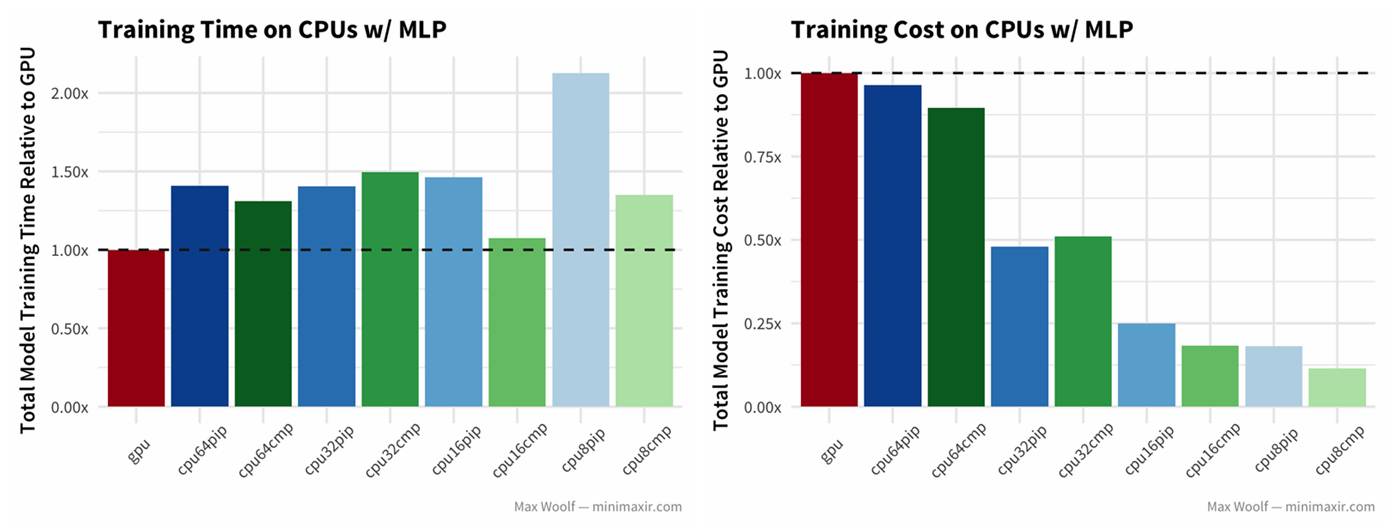
使用多层感知机(MLP)架构做手写数字分类的结果。左图是训练时间,右图是训练成本(下同)。在每张图片中,最左边的直方图是 GPU(红色),后面依次是 64 vCPU、32 vCPU、16 vCPU 和 8 vCPU(在 CPU 中,靠左边的是 pip,右边是 cmp 编译的)。来源:Max Woolf
在这里,GPU 训练速度是所有平台配置中最快的——这并不奇怪。但是,也有其他值得注意的趋势:32 vCPU(左起第 4、5 直方图)和 64 vCPU(左起第 2、3 直方图)之间性能相似,编译的 TensorFlow 库训练速度确实有重大改进,但只有 8 核和 16 核 CPU 如此(pip 和 cmp 之间有明显差异)。也许,在多核 CPU 之间协商信息的开销抵消了多核 CPU 的性能优势,也许是这些开销与编译的 TensorFlow 的 CPU 指令不同。
由于不同 vCPU 的训练速度差异很小,因此减少数量肯定更加划算。对于每个模型架构和配置,Max 计算了相对于 GPU 虚拟机训练成本的归一化训练成本。GCE 虚拟机成本是按比例分摊的(不像 Amazon EC2),可以简单地将实验运行的总秒数乘以虚拟机的成本(每秒)。理想情况下,这个值越低越好。结果发现,对于这个分类问题,减少 CPU 数量来说成本效益更高,CPU 数量越少越好。
2)再来看一下相同数据集,使用卷积神经网络(CNN)对数字进行分类的情况:
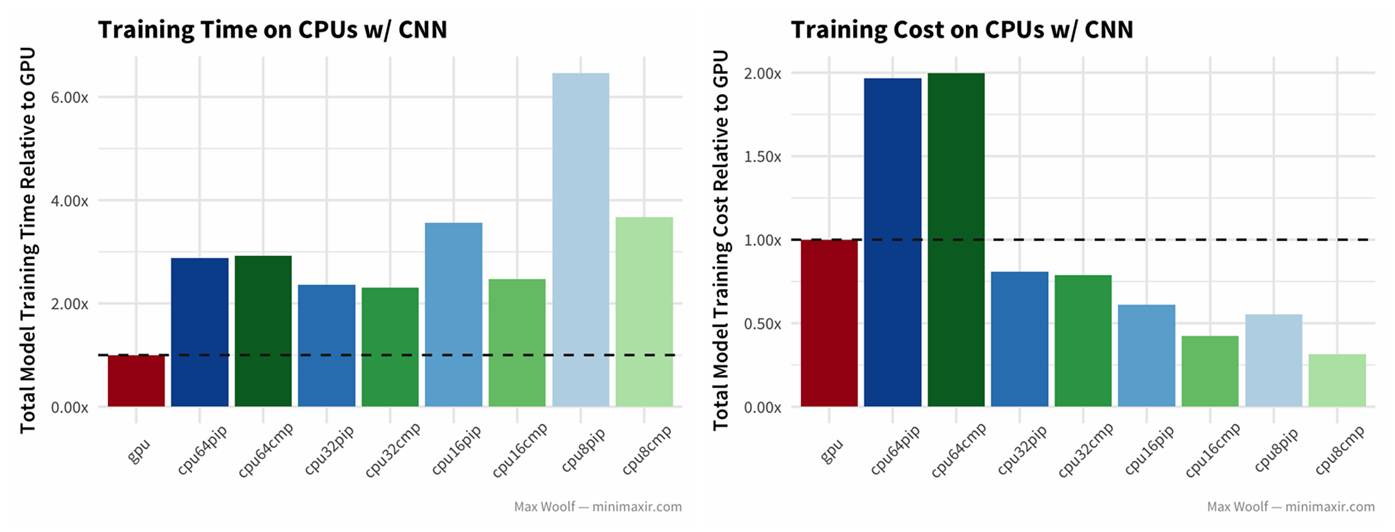
不出意料,GPU 比其他任何 CPU 都快大约两倍,但成本结构仍然相同。64 vCPU 在成本效益上表现糟糕,32 vCPU 的训练速度甚至还比 64 vCPU 快一些。
3)再来看看使用 CIFAR-10 图像数据集,用类似 VGG-16 的架构(深度 CNN + MLP)图像分类的结果。
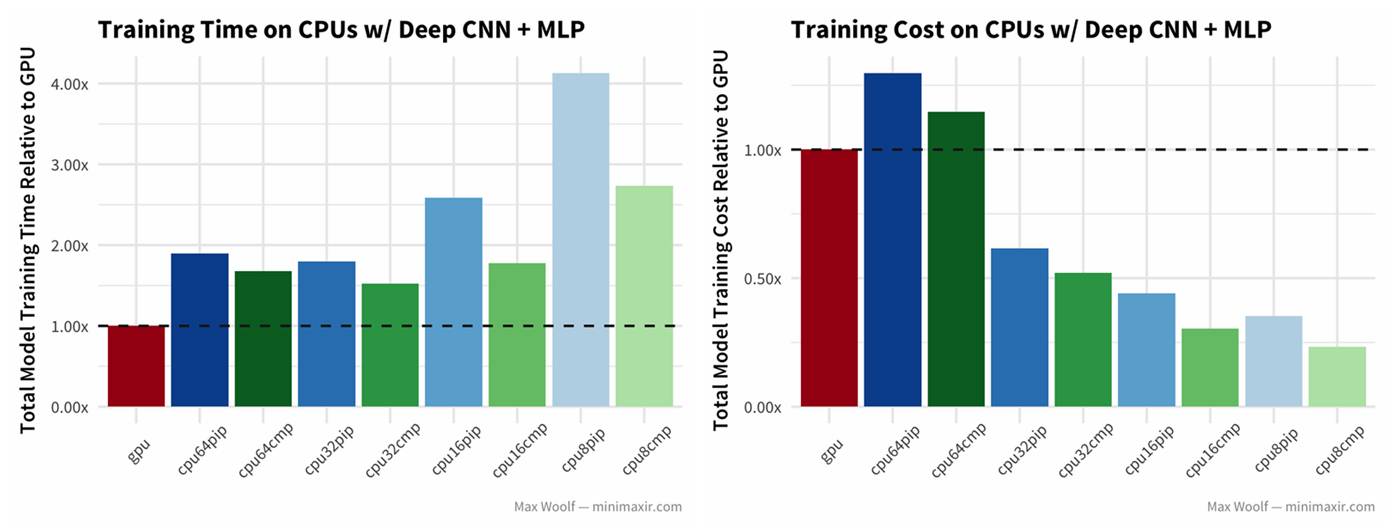
结果与普通的 CNN 类似,其中 cmp 的效果都比 pip 的好。
不过,结果在下面这种情况时出现了不同——
4)用双向长短时记忆(LSTM)架构处理 IMBb 电影评价
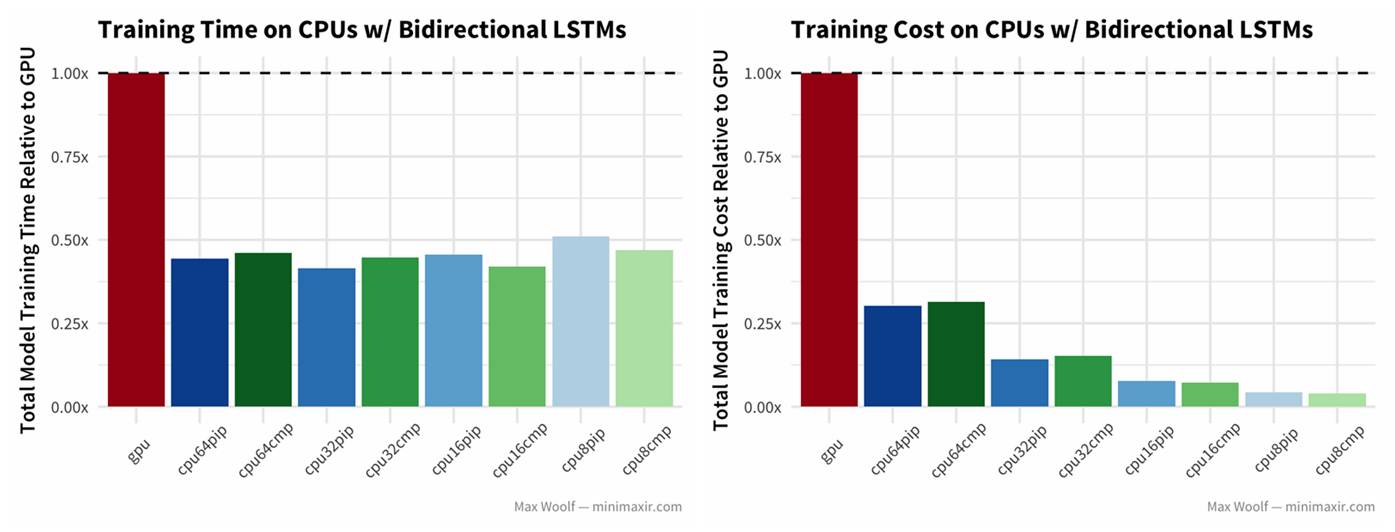
注意这里,GPU 的训练时间是 CPU 的两倍多?!
是的,你没有看错。
5)最后,用 LSTM 做文本生成:
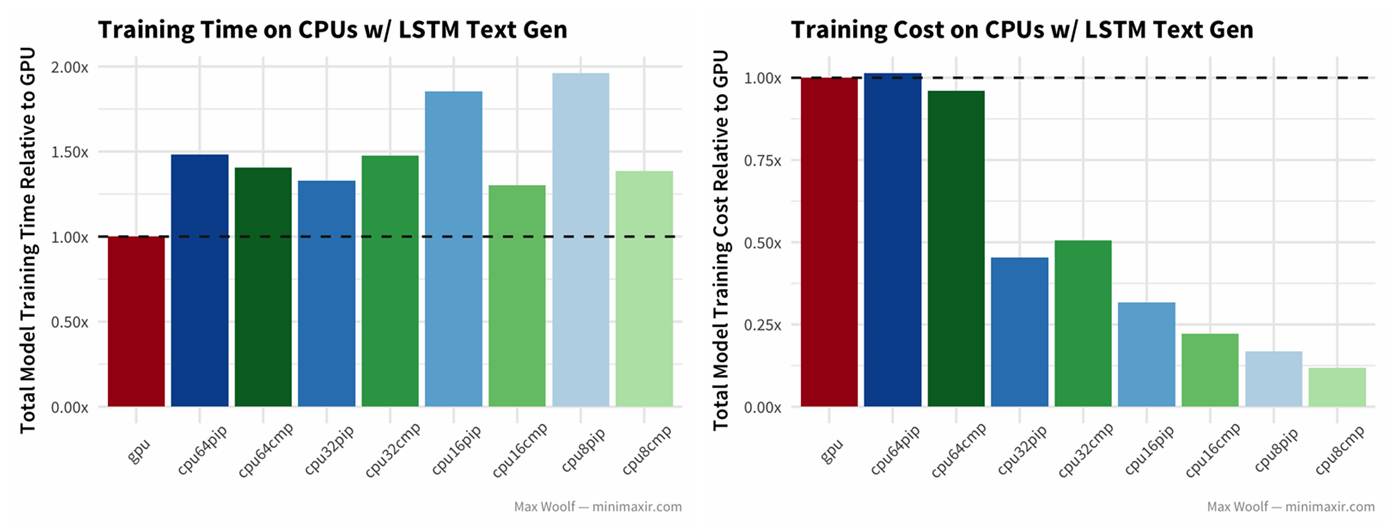
虽然结果还是 GPU 的训练时间更短,但除了 64 vCPU,其他 CPU 的训练成本更低。
3. 结论
有了上面的测试,Max 得出结论认为,使用 64 vCPU 不利于深度学习,因为当前的软件/硬件架构无法充分利用所有这些。通常情况下,64 vCPU 与 32 vCPU 性能相差不多(甚至更差)。在平衡训练速度和成本方面,用 16 核 CPU + 编译的 TensorFlow 似乎是最佳选择。编译的 TensorFlow 库有 30%-40% 的速度提升,这是个惊喜。可惜谷歌官方不提供具有这些 CPU 加速功能的 TensorFlow 预编译版本。
当然, Max 指出,这里之所以有成本优势,只能在谷歌云特殊的机制下,那就是权限低的虚拟机用较低的价格提供。Max 认为,在个人使用的情况下,使用谷歌云 CPU 训练深度学习模型是值得考虑的。如果不考虑这一点,云端 CPU 的这种优势是不会存在的。
编译来源
http://economictimes.indiatimes.com/tech/software/intel-nvidia-battle-it-out-in-data-centre-market/articleshow/59519131.cms
http://minimaxir.com/2017/07/cpu-or-gpu/

点击阅读原文查看新智元招聘信息






