(点击
上方公众号
,可快速关注)
来源:占小狼,
www.jianshu.com/p/94989b278114
如有好文章投稿,请点击 → 这里了解详情
收集算法
垃圾收集算法主要有:标记-清除、复制和标记-整理。
1、标记-清除算法
对待回收的对象进行标记。
算法缺点:效率问题,标记和清除过程效率都很低;空间问题,收集之后会产生大量的内存碎片,不利于大对象的分配。
2、复制算法
复制算法将可用内存划分成大小相等的两块A和B,每次只使用其中一块,当A的内存用完了,就把存活的对象复制到B,并清空A的内存,不仅提高了标记的效率,因为只需要标记存活的对象,同时也避免了内存碎片的问题,代价是可用内存缩小为原来的一半。
3、标记-整理算法
在老年代中,对象存活率较高,复制算法的效率很低。在标记-整理算法中,标记出所有存活的对象,并移动到一端,然后直接清理边界以外的内存。
对象标记过程
在可达性分析过程中,为了准确找出与GC Roots相关联的对象,必须要求整个执行引擎看起来像是被冻结在某个时间点上,即暂停所有运行中的线程,不可以出现对象的引用关系还在不断变化的情况。
如何快速枚举GC Roots?
GC Roots主要在全局性的引用(常量或类静态属性)与执行上下文(本地变量表中的引用)中,很多应用仅仅方法区就上百兆,如果进行遍历查找,效率会非常低下。
在HotSpot中,使用一组称为OopMap的数据结构进行实现。类加载完成时,HotSpot把对象内什么偏移量上是什么类型的数据计算出来存储到OopMap中,通过JIT编译出来的本地代码,也会记录下栈和寄存器中哪些位置是引用。GC发生时,通过扫描OopMap的数据就可以快速标识出存活的对象。
如何安全的GC?
线程运行时,只有在到达安全点(Safe Point)才能停顿下来进行GC。
基于OopMap数据结构,HotSpot可以快速完成GC Roots的遍历,不过HotSpot并不会为每条指令都生成对应的OopMap,只会在Safe Point处记录这些信息。
所以Safe Point的选择很重要,如果太少可能导致GC等待的时间太长,如果太频繁可能导致运行时的性能问题。大部分指令的执行时间都非常短暂,通常会选择一些执行时间较长的指令作为Safe Point,如方法调用、循环跳转和异常跳转等。
关于Safe Point更多的信息,可以看看这篇文章《 JVM的Stop The World,安全点,黑暗的地底世界 》(http://calvin1978.blogcn.com/articles/safepoint.html)。
发生GC时,如何让所有线程跑到最近的Safe Point再暂停?
当发生GC时,不直接对线程进行中断操作,而是简单的设置一个中断标志,每个线程运行到Safe Point的时候,主动去轮询这个中断标志,如果中断标志为真,则将自己进行中断挂起。
这里忽略了一个问题,当发生GC时,运行中的线程可以跑到Safe Point后进行挂起,而那些处于Sleep或Blocked状态的线程在此时无法响应JVM的中断请求,无法到Safe Point处进行挂起,针对这种情况,可以使用安全区域(Safe Region)进行解决。
Safe Region是指在一段代码片段中,对象的引用关系不会发生变化,在这个区域中的任何位置开始GC都是安全的。
1、当线程运行到Safe Region的代码时,首先标识已经进入了Safe Region,如果这段时间内发生GC,JVM会忽略标识为Safe Region状态的线程;
2、当线程即将离开Safe Region时,会检查JVM是否已经完成GC,如果完成了,则继续运行,否则线程必须等待直到收到可以安全离开Safe Region的信号为止;
垃圾收集器
Java虚拟机规范并没有规定垃圾收集器应该如何实现,用户可以根据系统特点对各个区域所使用的收集器进行组合使用。
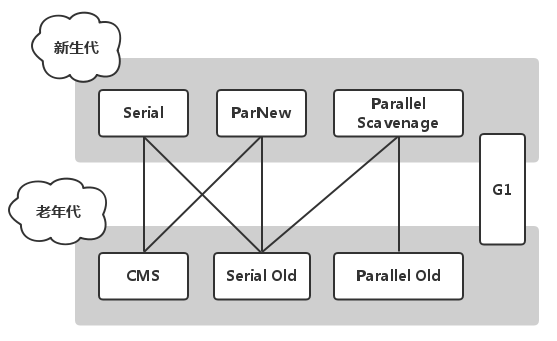
上图展示了7种不同分代的收集器,如果两两之间存在连线,说明可以组合使用。
1、Serial收集器(串行GC)
Serial 是一个采用单个线程并基于复制算法工作在新生代的收集器,进行垃圾收集时,必须暂停其他所有的工作线程。对于单CPU环境来说,Serial由于没有线程交互的开销,可以很高效的进行垃圾收集动作,是Client模式下新生代默认的收集器。










