
关注
鸿蒙技术社区
,回复
【鸿蒙】
送
价值
399元
的鸿蒙
开发板套件
(数量有限,先到先得)
,还可以
免费下载
鸿蒙
入门资料
!
👇
扫码
立刻关注
👇

专注开源技术,共建鸿蒙生态
几年前我曾经服务过的一家电商公司,随着业务增长我们每天的订单量很快从 30 万单增长到了 100 万单,订单总量也突破了一亿。
当时用的 MySQL 数据库。根据监控,我们的每秒最高订单量已经达到了 2000 笔(不包括秒杀,秒杀 TPS 已经上万了。秒杀我们有一套专门的解决方案,详见
《秒杀系统设计~亿级用户》
)。
不过,直到此时,订单系统还是单库单表,幸好当时数据库服务器配置不错,我们的系统才能撑住这么大的压力。
业务量还在快速增长,再不重构系统早晚出大事,我们花了一天时间快速制定了重构方案。
重构?说这么高大上,不就是分库分表吗?的确,就是分库分表。不过除了分库分表,还包括管理端的解决方案,比如运营,客服和商务需要从多维度查询订单数据,分库分表后,怎么满足大家的需求?
分库分表后,上线方案和数据不停机迁移方案都需要慎重考虑。为了保证系统稳定,还需要考虑相应的降级方案。
当数据库产生性能瓶颈:IO 瓶颈或 CPU 瓶颈。两种瓶颈最终都会导致数据库的活跃连接数增加,进而达到数据库可承受的最大活跃连接数阈值。
终会导致应用服务无连接可用,造成灾难性后果。可以先从代码,SQL,索引几方面进行优化。如果这几方面已经没有太多优化的余地,就该考虑分库分表了。
第一种:磁盘读 IO 瓶颈。
由于热点数据太多,数据库缓存完全放不下,查询时会产生大量的磁盘 IO,查询速度会比较慢,这样会导致产生大量活跃连接,最终可能会发展成无连接可用的后果。
可以采用一主多从,读写分离的方案,用多个从库分摊查询流量。或者采用分库+水平分表(把一张表的数据拆成多张表来存放,比如订单表可以按 user_id 来拆分)的方案。
第二种:磁盘写 IO 瓶颈。
由于数据库写入频繁,会产生频繁的磁盘写入 IO 操作,频繁的磁盘 IO 操作导致产生大量活跃连接,最终同样会发展成无连接可用的后果。
这时只能采用分库方案,用多个库来分摊写入压力。再加上水平分表的策略,分表后,单表存储的数据量会更小,插入数据时索引查找和更新的成本会更低,插入速度自然会更快。
SQL 问题:
如果 SQL 中包含 join,group by,order by,非索引字段条件查询等增加 CPU 运算的操作,会对 CPU 产生明显的压力。
这时可以考虑 SQL 优化,创建适当的索引,也可以把一些计算量大的SQL逻辑放到应用中处理。
单表数据量太大:
由于单张表数据量过大,比如超过一亿,查询时遍历树的层次太深或者扫描的行太多,SQL 效率会很低,也会非常消耗 CPU。这时可以根据业务场景水平分表。
①利用 MyCat,KingShard 这种代理中间件分库分表。
好处是和业务代码耦合度很低,只需做一些配置即可,接入成本低。缺点是这种代理中间件需要单独部署,所以从调用连路上又多了一层。
而且分库分表逻辑完全由代理中间件管理,对于程序员完全是黑盒,一旦代理本身出问题(比如出错或宕机),会导致无法查询和存储相关业务数据,引发灾难性的后果。
如果不熟悉代理中间件源码,排查问题会非常困难。曾经有公司使用 MyCat,线上发生故障后,被迫修改方案,三天三夜才恢复系统。CTO 也废了!
②利用 Sharding-Jdbc,TSharding 等以 Jar 包形式呈现的轻量级组件分库分表。
缺点是,会有一定的代码开发工作量,对业务有一些侵入性。好处是对程序员透明,程序员对分库分表逻辑的把控会更强,一旦发生故障,排查问题会比较容易。
稳妥起见,我们选用了第二种方案,使用更轻量级的 Sharding-Jdbc。
做系统重构前,我们首先要确定重构的目标,其次要对未来业务的发展有一个预期。这个可以找相关业务负责人了解,根据目标和业务预期来确定重构方案。
例如,我们希望经过本次重构,系统能支撑两年,两年内不再大改。业务方预期两年内日单量达到 1000 万,相当于两年后日订单量要翻 10 倍。
根据上面的数据,我们分成了 16 个数据库。按日订单量 1000 万来算,每个库平均的日订单量就是 62.5 万(1000 万/16),每秒最高订单量理论上在 1250 左右( 2000*(62.5/100) )。
这样数据库的压力基本上是可控的,而且基本不会浪费服务器资源。
每个库分了 16 张表,即便按照每天 1000 万的订单量,两年总单量是 73 亿(73 亿=1000 万*365*2),每个库的数据量平均是 4.56 亿(4.56 亿=73 亿/16),每张表的数据量平均是 2850 万(2850 万=4.56 亿/16)。
可以看到未来两到三年每张表的数据量也不算多,完全在可控范围。
分库分表主要是为了用户端下单和查询使用,按 user_id 的查询频率最高,其次是 order_id。
所以我们选择 user_id 做为 sharding column,按 user_id 做 hash,将相同用户的订单数据存储到同一个数据库的同一张表中。
这样用户在网页或者 App 上查询订单时只需要路由到一张表就可以获取用户的所有订单了,这样就保证了查询性能。
另外我们在订单 ID(order_id)里掺杂了用户 ID(user_id)信息。
简单来说,order_id 的设计思路就是,将 order_id 分为前后两部分,前面的部分是 user_id,后面的部分是具体的订单编号,两部分组合在一起就构成了 order_id。
这样我们很容易从 order_id 解析出 user_id。通过 order_id 查询订单时,先从 order_id 中解析出 user_id,然后就可以根据 user_id 路由到具体的库表了。
另外,数据库分成 16 个,每个库分 16 张表还有一个好处。16 是 2 的 N 次幂,所以 hash 值对 16 取模的结果与 hash 值和 16 按位“与运算”的结果是一样的。
我们知道位运算基于二进制,跨过各种编译和转化直接到最底层的机器语言,效率自然远高于取模运算。
有读者可能会问,查询直接查数据库,会不会有性能问题?是的。所以我们在上层加了 Redis,Redis 做了分片集群,用于存储活跃用户最近 50 条订单。
这样一来,只有少部分在 Redis 查不到订单的用户请求才会到数据库查询订单,这样就减小了数据库查询压力,而且每个分库还有两个从库,查询操作只走从库,进一步分摊了每个分库的压力。
有读者可能还会问,为什么没采用一致性 hash 方案?用户查询最近 50 条之前的订单怎么办?请继续往后看!
分库分表后,不同用户的订单数据散落在不同的库和表中,如果需要根据用户 ID 之外的其他条件查询订单。
例如,运营同学想从后台查出某天 iphone7 的订单量,就需要从所有数据库的表中查出数据然后在聚合到一起。
这样代码实现非常复杂,而且查询性能也会很差。所以我们需要一种更好的方案来解决这个问题。
我们采用了 ES(ElasticSearch)+HBase 组合的方案,将索引与数据存储隔离。
可能参与条件检索的字段都会在 ES 中建一份索引,例如商家,商品名称,订单日期等。所有订单数据全量保存到 HBase 中。
我们知道 HBase 支持海量存储,而且根据 Rowkey 查询速度超快。而 ES 的多条件检索能力非常强大。可以说,这个方案把 ES 和 HBase 的优点发挥地淋漓尽致。
看一下该方案的查询过程:
先根据输入条件去 ES 相应的索引上查询符合条件的 Rowkey 值,然后用 Rowkey 值去 HBase 查询,后面这一步查询速度极快,查询时间几乎可以忽略不计。
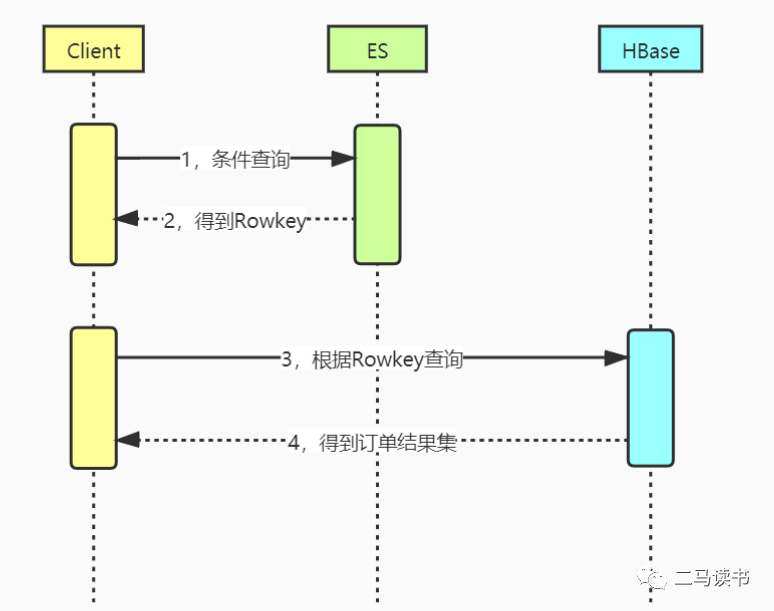
该方案,解决了管理端通过各种字段条件查询订单的业务需求,同时也解决了商家端按商家 ID 和其他条件查询订单的需求。如果用户希望查询最近 50 条订单之前的历史订单,也同样可以用这个方案。
每天产生数百万的订单数据,如果管理后台想查到最新的订单数据,就需要频繁更新 ES 索引。在海量订单数据的场景下,索引频繁更新会不会对 ES 产生太大压力?
ES 索引有一个 segment(片段)的概念。ES 把每个索引分成若干个较小的 segment 片段。
每一个 segement 都是一个完整的倒排索引,在搜索查询时会依次扫描相关索引的所有 segment。
每次 refresh(刷新索引) 的时候,都会生成一个新的 segement,因此 segment 实际上记录了索引的一组变化值。由于每次索引刷新只涉及个别 segement 片段,更新索引的成本就很低了。
所以,即便默认的索引刷新(refresh)间隔只有 1 秒钟,ES 也能从容应对。
不过,由于每个 segement 的存储和扫描都需要占用一定的内存和 CPU 等资源,因此 ES 后台进程需要不断的进行 segement 合并来减少 segement 的数量,从而提升扫描效率以及降低资源消耗。
MySQL 中的订单数据需要实时同步到 Hbase 和 ES 中,那么同步方案是什么?





