文字是政治中不可分割的一部分。官员和公民用语言来表达意见、提出建议,并为自己的行为辩护。法律和法规也主要是用文字编纂。互联网革命提供了大量与政治有关的数据——例如,政府部门机构的工作记录、谷歌图书、推特和脸书等社交媒体网站的数据。
研究界通过使用过剩(surfeit)的数据,用R、Python和其他编程语言开发了可访问的开源文本分析库。如此多未开发的研究机会和可访问的工具和培训的结合,使此成为所有领域的专家研究文本的绝佳时机。
法律学者可以系统地研究议会演讲和法律法规的修订;国际关系学者可以将最终签订的条约或协定与在早期阶段提出的数百个建议进行比较;而政治理论家可以通过搜索几个世纪以来已出版的作品来探索政治思想。
计算文本分析将极大地改变政治科学研究范式。
“文本即数据”的方法以两种方式扩大了政治学家的研究机会。首先,它们利用计算的力量,使大规模的数据收集任务成为可能。其次,它们为定量分析大规模文本提供了越来越多的选择。一个典型的“文本即数据”项目需要经过四个阶段:
文本获取(obtained),定量数据转换(converted),分析(analyzed)和验证(valided)。
项目的第一阶段通常需要下载数字化(digitalized)的内容。一些来源使研究人员很容易得到他们所需要的东西,而从其他来源提取相关信息可能是困难和耗时的。应用程序接口(APIs)使用户能够使用一行代码从底层结构化数据库中“请求”选定的内容。但如果APIs不可用,下一个最优选择是获得类似格式的文档。比如包括
隐藏格式化语言的
数千份国会法案文本,这有助于系统地提取更具体的内容。
最具挑战性的文本提取(extraction)是从不同的来源提取相关的内容。一种解决方式是为不同网站编写多个脚本(scripts),例如开放国家项目(https://openstates.org);另一种选择是在源代码上收集更简单的指标,如关键字的计数。
在第二阶段,每个文档的内容必须转换为定量数据——通常是创建一个术语-文档或术语-频率矩阵,其中每一行是一个文档,每一列是至少一个文档中找到的特性。在这个阶段,研究人员需要选择适当的分析单位。例如,美国总统国情咨文(SOU)涵盖了许多不同的主题,而一个研究国情咨文政策主题的项目可能会通过将每篇文章分成更具体的段落或句子而得到改进。
下一步是分辨每个文档中的哪些特征词需要进行量化,并删除标点符号、常见单词(终止词)、非常罕见的单词(稀疏术语)和单词后缀(词干)等。
在第三阶段,学界围绕着机器学习(machine learning)和统计理论(statistics)展开了方法论辩论。事实上,对二者的区别有助于突出方法使用上的差异。政治学家们习惯于使用统计学方法来检验理论。他们为数据选择最佳的模型(普通最小二乘、Logistic回归等),并关注输入的元素(寻因);而在机器学习研究中,重点则通常是输出(探果)。例如,在关于美国总统民调变化的研究中,统计学方法倾向于解释总统支持率的可能影响因素,而机器学习方法则更关注对大选结果预测的准确性。
第四阶段的验证是每个计算文本分析项目的关键组成部分。对于某些方法来说,验证是很简单的。通过比较算法的预测与预先存在的“黄金标准”(gold standard),例如专家的观点建议,可以验证有监督(supervised)的机器学习结果。对于没有“黄金标准”的其他方法,验证通常是多方面的。例如,对于无监督的机器学习方法来说,学者们通过深入研究具体的例子来表明主题是有意义的(make sense)。
本节的目的是为政治学家提供研究机会的概览,包括
分类(classification)、分级(scaling)、文本重用(text reuse)和语义(semantic)。
分类是“文本即数据”项目的一个重要研究方向。无监督的机器学习方法——包括K均值聚类(K-means)、主成分分析(PCA)、潜在狄利克雷分配(LDA)——比较了基于同时出现的特征的文档的相似性。尽管这些方法的名称不同,但无监督方法需要用户的大量输入,用户必须提前指定主题的数量并解释它们的含义。因此,无监督方法通常用于发现特征,而监督学习方法主要用作(基于现有特征进行分类从而)节省重复劳动。
此外,情绪分析是分类研究的另一个重要领域,即对文本进行定序分类(例如,从消极到积极)。
在政治科学中,自动文本分析的一些最早的应用集中在使用公开演讲和宣言(manifesto)将欧洲政党定位在连续(continuous)且分级的意识形态空间中。随后的研究通过采用新的方法和视角来扩展这一领域,例如“众包(crowdsourceing)”、
利益集团和欧盟监管机构的声明、推特数据和转推者信息等
。
文本重用是关于发现类似语言使用的实例。文本重用算法的显著特点在于,它们在判断文档相似性时明确地重视单词排序。政治学家最近利用他们来追踪立法中政策建议的起源,研究利益集团对州立法机构的影响,并研究政党信息的传递策略。政治学家尚未利用的其他可能性包括研究政治模因(
memes,指在同一种文化中人与人之间传播的思想、行为和风格)在新旧媒体中的传播和传染效应。不同的算法也支持不同类型的分析。全局对齐方法(Globa alignment approach
)衡量文档的总体相似性(细数多少提议变化),而局部对齐方法(local)识别和评分文档中共享的单词序列(具体某项建议变动)。
社会网络分析通常使用文本来调查行为者之间的关系。自然语言处理(NLP)使得人们不仅仅是建立联系,而是调查关系的状态——从“谁?”到“谁对谁做了什么?”。例如,政治事件数据分析利用媒体报道,系统地监测国际行为者之间的相互作用。事件数据分析不是简单地计算报告中提到两个参与者的次数,而是计算合并的次数语法和语义,来判断一种关系是在改善还是在恶化。早期的事件数据研究依赖于专家来开发特征字典,而最近研究试图通过利用计算机科学家和语言学家开发的广泛的自然语言处理资源来显著扩大研究范围。
在最后一节中,本文将从对该领域的概述转向更详细地深入研究一个当代的挑战。无监督机器学习方法(主题模型)在政治学中非常流行,部分原因是它们对文档进行分类但不需要广泛的文本标记(labeling)。常见的做法是,在比较几个不同模型的结果后,报告和验证单个主题模型,这些模型因研究者指定的主题数量而不同。这种选择通常是基于研究者对哪个模型的集群最能反映项目的实质性目标的主观判断。
但是,“黄金标准”的缺失使得这些方法的验证更具挑战性。
第二个挑战是模型的不稳定性
。有学者(见图1)对相同的结构主题模型进行了50次估计,发现25个主题中只有2个在所有估计中持续存在。这可能是因为不同的估计可以在不同的局部极大值(local maxima)上收敛。在第二个实验中,同样发现,只操作(manipulate)一个结构性主题模型的一个特征也会导致非常不同的结果(见图1)。许多机器学习包默认删除很少使用的单词,以减少处理时间和避免过拟合。在图1中,只改变这个特征会导致在对同一模型的不同估计中所产生的主题方面的重要差异。

图1 特征改变对主题模型稳定性的影响(摘自原文)
稳健性
可以根据方法、参数、特征和数据分区进行评估。虽然没有一项研究可以考虑所有因素,但使用“文本即数据”方法的政治学家应该明确地说明他们的结果的稳健性。这些中心发现是否经得起建模选择的合理变化?对于主题模型,一种选择是远离当前为单个模型报告结果的惯例。
本节的剩余部分将讨论主题的稳健性(robustness)如何为对国会演讲的研究提供信息。首先,对美国第113届国会(2013-2014年)期间435名美国众议院议员发表的近1万次“一分钟”的现场演讲文本进行统计(包括语音单词转换、非关键词删除与术语-文档矩阵构造)。其次,估计一系列潜在的狄利克雷分配(LDA)模型,其中主题的数量(k)在5个主题增量变化范围在10到90之间,故而17个模型将产生850个主题。
为了确定哪些主题是稳健的,通过
频谱聚类算法和余弦相似度(cosine)进行集群分类。太多的聚类划分可能会使分析复杂化,而不会提高模型对数据的整体拟合。图2显示了当语音集群(c)的数量从5到100之间变化时,模型拟合度如何变化(50个集群时达到最大值)。
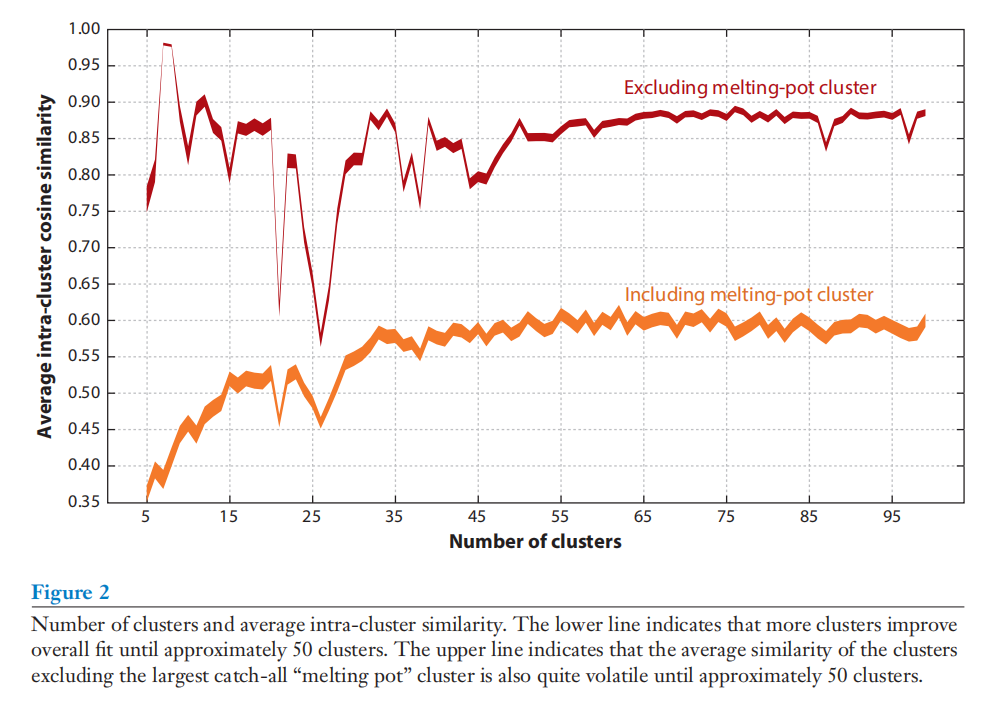
图2 集群数量与集群内平均余弦相似度变化(摘自原文)
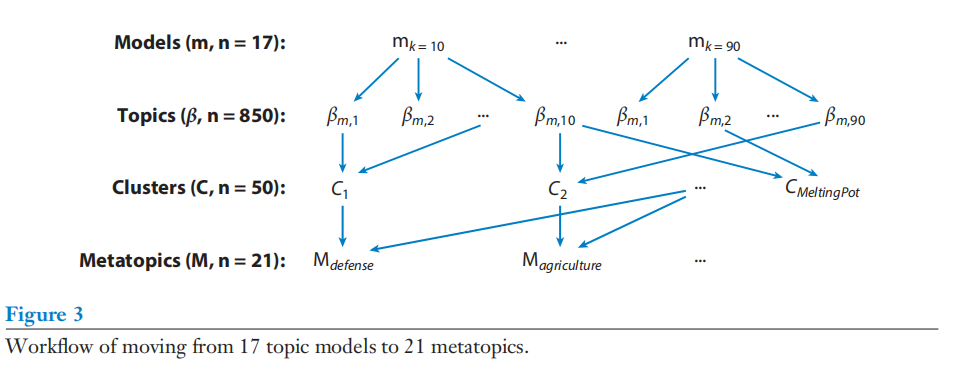
在将17个模型中的850个主题聚为50个集群后(见图3)后,一些集群分组形成了所谓的“元主题(metatopic)”。










