出品丨AI 科技大本营(ID:rgznai100)
不知道还有多少人记得那场发布会。
去年初春,Sam Altman 一如既往发了条谜语人风格的推特:“Her”,让人想起电影《Her》里那个和男主情深伉俪的 AI 女声;然后时任 OpenAI CTO 的另一位美女 Mira Murati 当晚发布了 GPT-4o,视频语音交互丝滑无比,说学逗唱样样精通,还完美复刻了电影里斯嘉丽·约翰逊的声音,给人感觉 AGI 好像第二天就要实现了。

结局就是,斯嘉丽本人因为非法训练声音把 OpenAI 告了;高级语音模式跳票大半年之后正式版本让人大失所望,很多人猜测是算力限制所以不如发布会的版本那么好用;最后 Mira Murati 也离开了 OpenAI。
但发布会里的内容仍旧让人魂牵梦绕:
当天那个惊艳世界的演示,那个丝滑的视频语音交互体验,那个“她”,我们什么时候才能在现实体验到呢?

1 月 15 日,面壁智能最新发布的端侧模型
MiniCPM-o 2.6
一经开源,立刻在海外技术社区引发热议:
“她”来了!
只不过,这次是在端上,不用联网,仅
8B 参数
;
虽然都是“她”,但 OpenAI 发布的是“Her”,国内的面壁发布的是“
SHE
”
(See, Here, Express / 看、听、说)
。
推特(X)上,说英文的、说中文的、说日语的、还有看不懂是什么语言的,全在讨论这款「能在 iPad 上运行」的端侧 AI 模型:
让人惊艳的是,这个仅有 8B 参数的“
小钢炮
”,第一次
把 GPT-4o 级别的音视频全模态能力带到了终端设备上
。
一个装在你设备里、不需要联网就能用的 AI,可以实时地看、听、说,而且还能像人类一样自然地进行互动。
MiniCPM-o 2.6 开源地址
GitHub:
https://github.com/OpenBMB/MiniCPM-o
Huggingface:
https://huggingface.co/openbmb/MiniCPM-o-2_6
在技术层面,MiniCPM-o 2.6 最大的突破在于真正实现了“
看得清、听得懂、说得好
”的全模态交互。而事实上,像“
识别背景音
”这样看起来简单的能力,反而是去年三月震惊世界的 GPT-4o 无法实现的,尤其是后来上线的正式版高级语音模式,更是失去了初见时的惊艳。
“Her”都做不到的事情,国产的“SHE”却可以?
怀揣一肚子问题,CSDN AI 科技大本营向清华大学博士后、MiniCPM-o 技术负责人
姚远
询问了具体实现细节。
在“看”方面,姚远解释说这是一个
真正的视频大模型
,而不是简单的“照片大模型”。“
视频最大的挑战在于信息的冗余性,以及如何在这种冗余中找到精准信息。
”姚远说,“
你可以用很高的帧率采样,但模型很难负担这么大的信息量。如果减少看的帧数,又可能错过重要信息。这是视频处理中最本质的挑战。
”
这是什么意思?首先,传统的「音视频通话」模型,大多数可以直观理解为「照片大模型」:仅在用户提问后才开始对视频进行一帧或极少数几帧画面的抽取,无法捕捉用户提问之前的画面,缺乏对前文情境的感知。
而
真正的视频大模型,则能够感知用户提问之前的画面和声音
,并持续对实时视频和音频流进行建模,这种方式更贴近人眼的自然视觉交互。
为了解决这个问题,MiniCPM-o 2.6 采用了高效的视觉压缩方案。姚远解释:“
比如说处理一张 180 万像素的图片,我们现在只用 640 个 token 就可以编码表达,这在业界是非常高效的压缩比。
”
这种高效的视觉处理能力在实际测试中得到了充分验证。在实时流式视频理解能力的权威榜单 StreamingBench 上,MiniCPM-o 2.6 性能惊艳,比肩 GPT-4o、Claude-3.5-Sonnet。
注:GPT-4o API 无法同时输入语音和视频,目前定量评测输入文本和视频
自发布以来,小钢炮多模态系列一直保持着最强端侧视觉通用模型的纪录。光荣再续,MiniCPM-o 2.6 视觉理解能力也达到端侧全模态模型最佳水平。
接下来,在“
听
”方面,
MiniCPM-o 2.6
引人注目的特性是它能
识别各种非人声的背景音
。比如说,
当你和它对话时,它甚至能一边用四川话教你煮火锅,一边分辨出背景里的翻书声、倒水声:
那么,另一个问题就出来了:
GPT-4o 暂不支持的
背景音识别,听起来好像挺酷的,但它到底有什么用呢?
比如,模型能听到倒水声或者敲门声,这听起来好像很高级,但实际生活中真的需要这种能力吗?
姚远回答道:
“
在真实场景中,我们更需要理解完整的声音环境。比如说当模型辅助盲人上街时,能听到后面的车按喇叭,这些真实世界的声音都非常重要。
”
说实话,我提问之前确实没想到会得到这么精彩的回答:
背景音识别能力是构建更完整、更真实的世界模型的关键一环。
总而言之,这能够帮助模型更全面地理解真实世界,从而提供更自然、更人性化的交互体验。
除了姚远提到的
背景音识别这一独特优势外,MiniCPM-o 2.6 在各项语音基准测试中也展现出全面的领先优势。


而这些能力的背后,是一套精心设计的端到端交互架构。更具挑战性的是如何让这些能力实现流畅交互。
“
长时间运行时,即使 token 占用很少,持续累积的信息量还是会越来越多,尤其是同时混入音频流的情况下会更复杂。
”姚远介绍道,MiniCPM-o 2.6
团队开发了高效的
时分复用
机制。
简单来说,就是把同时输入的视频流和音频流按时间顺序拆分成一个个小的周期性片段,在同一个时间片段内,先处理几帧图像,再处理几毫秒的音频波形,再把它们组合起来。
这样就避免了信息在处理过程中的相互干扰。
下面这个视频就是在记忆卡牌游戏中,
MiniCPM-o 2.6
不仅能记住卡片的具体图案,还能理解卡片的相对位置关系,展现出接近人类的空间记忆能力
:
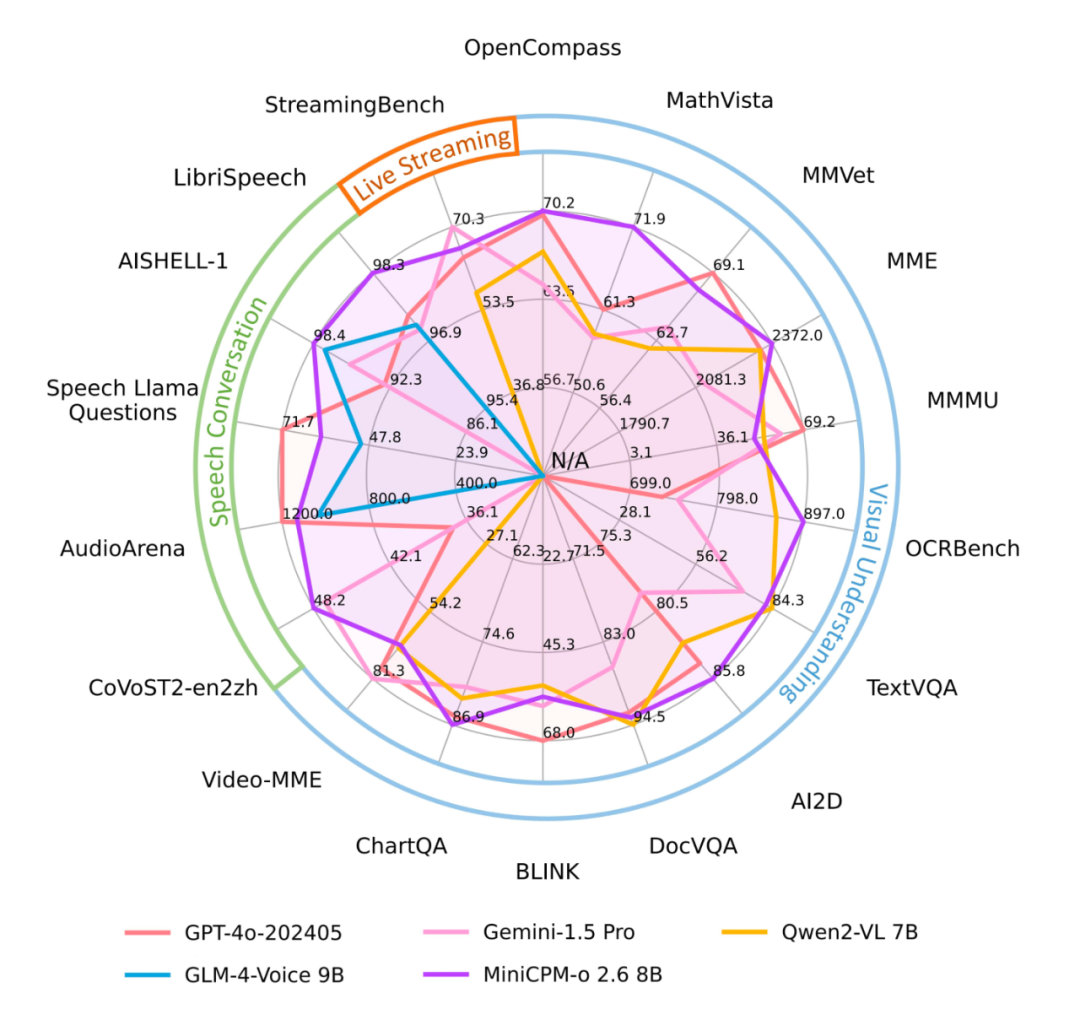
最后就是把以上成果组成了一张图:
在评估全模态模型音视频能力的多个榜单上,MiniCPM-o 2.6 能力全面且优秀。
面对如此出色的技术突破,一个自然的问题是:
端侧 AI 的未来究竟在哪里?
是一直这样进化下去,「以端胜云」;
亦或是专攻垂直赛道,走出不一样的路线?
去年 9 月,
当端侧旗舰模型 MiniCPM 3.0 发布时
,面壁智能 CEO 李大海在接受 CSDN AI 科技大本营采访时提到端侧 AI 有
两大应用方向
:
一是升级现有应用场景,二是创造全新的应用场景。
几个月过去,前者已经成为全球 AI 公司的共识,从苹果的 Apple Intelligence 到谷歌的 Gemini Nano,各大厂商都在追端侧,同时都在努力把现有应用变得更智能。
但是,全新应用场景的探索似乎还在原地踏步。
正好面壁智能前段时间参展“科技春晚” CES 2025,我们不禁向李大海提问:
端侧 AI 的创新图景是否有了新的突破?
他的第一反应则是自己的真实感受:“
每天都走了2万多步,最大的感受当然是腿疼——但确实很兴奋,因为这次我看到更重要的还是产品侧的创新。不是技术在推动产品,而是很多产品经理在很用心地揣摩用户需求,去感受他们真正想要什么。
”

这种供给侧和需求侧的结合,让李大海看到了新的可能。“
我们在组织能力上,在工作方向上需要把供给侧跟需求侧这两侧要能够很好地结合在一起。这也是我为什么特意安排产品经理到现场学习和观摩。
”
他认为,AI 技术发展到今天,包括面壁的端侧模型在内的技
术供给已经具备了很好的条件,但更好的智能设备产品不会自然产生,还需要对用户需求的深入洞察。
2024 年,端侧 AI 硬件成为科技创业大风口,AIPC、AIPhone、AI 眼镜等 AI+ 硬件迅速爆发,即是这一趋势的最佳验证。比方说我们曾整理无数篇
扎克伯格
和
杨立昆
的采访,从去年后半年开始,他们
基本上










