基础准备
在介绍对数线性模型之前,我们推送过方差分析及混合线性模型的内容,大家可以点击下方文章名称进行回顾:
对比两种分析方法可以发现,它们被创造出来就是为了研究分类变量的相关性;区别在于混合线性模型分析的是连续型数据,而对数线性模型的研究对象是频数。用最简单的两个分类变量为例,做出交叉单元格:
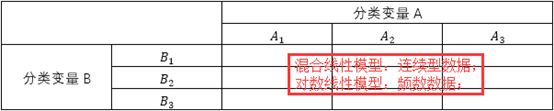
对数线性模型
看到上面的交叉单元格,以及单元格内的频数数据,你是否很快就会联想到可以使用卡方检验来分析分类变量A和分类变量B的相关关系?上面这个表只有一个行变量和一个列变量,因此使用卡方检验非常方便快捷,但是当涉及的分类变量很多,例如研究4个以上分类变量之间的相关关系时,卡方检验就不够用了,因为它不可以同时对多个分类变量之间的相关关系给出一个综合评价,也不可以在控制其它变量作用的同时对变量的效应做出估计,而对数线性模型可以解决卡方检验不能解决的这些问题,它可以一次性给出多个分类变量之间的两两相关关系。
前面提到对数线性模型与混合线性模型有相同的地方,都是围绕分类变量展开的,因此首先回顾混合线性模型,可以参考下面的表格,混合线性模型表格中的数据不是频数数据,而是连续型数据,可以理解成某项血液指标:
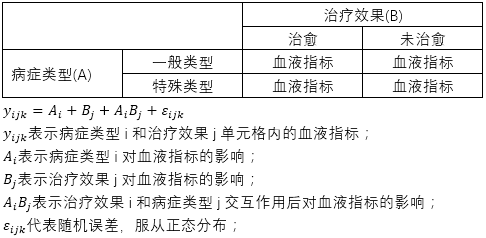
在混合线性模型中,将每个单元格内血液指标y的变异看作是病症类型(A)变量,治疗效果(B)变量、病症类型(A)和治疗效果(B)交互作用、随机误差共同影响的总和。
如果将每个单元格中的数据换成频数,例如,总共调查了180名患者,这些患者的人数(频数)分布情况如下:
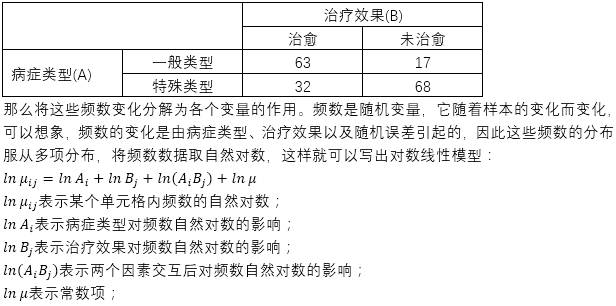
如果要研究病症类型与治疗效果是否相关,也就是研究病症类型是否影响到治疗效率,如果两者无关,可以发现一般类型和特殊类型的治疗效果人数比例是基本相同的,反映到对数线性模型中,就是研究交互作用项是否等于零。从对数线性模型可以看出,对数线性模型除了能够解决分类变量(因素)之间是否相关的问题,还能够分析分类变量对频数的独立影响,也就是分类变量对频数的主效应。
对数线性模型VS方差分析模型
前面介绍对数线性模型的分析逻辑是以方差分析模型(一般线性模型)为基础,由此可见它们的作用是类似的,都能够分析每个变量的主效应及变量之间的交互效应。对数线性模型与方差分析模型的差异为:方差分析模型的因变量是连续性变量,对数据的分布要求为正态性和方差齐性;对数线性模型主要研究多个分类变量之间的独立性和相关性,对数线性模型一般不分因变量和自变量,只分析各分类变量对交叉单元格内频数的影响,通常频数服从多项式分布。
对数线性模型VS逻辑回归模型
通过前面的介绍,大家可以发现很多对数线性模型能够分析的问题其实用逻辑回归模型也能够进行分析。对数线性模型主要研究多个分类变量之间的独立性与相关性,而逻辑回归模型的因变量也是分类变量,如果自变量也是分类变量,那么就和对数线性模型的效果相同了。
差别在于,一般对数线性模型通常将频数数据做自然对数变换(ln),而逻辑回归对频数的处理是做常用对数变换(lg);此外,对数线性模型不用区分因变量和自变量,而逻辑回归则需要明确因变量和自变量。因此对数线性模型与逻辑回归两种方法之间存在着非常密切的联系,两者的分析结果是等价的。对数线性模型的应用不如逻辑回归普遍,主要原因是如果考虑的分类变量太多,对数线性模型过于复杂。
SPSS的对数线性模块
SPSS的对数线性菜单总共提供了三个子菜单:常规、分对数和选择模型;这三个子菜单的分析过程都应用对数线性模型的基本原理,但在拟和方法和结果输出上有不同。
-
常规菜单在分析中只考虑变量之间是否相关,不考虑它们之间的因果关系,不过分析者可以在最后的结果解释中加入经验解释。
-
分对数菜单;有些情况,分析者已经明白变量之间的因果关系,此时继续用常规模型就无法利用因果信息,这样就会增添很多结果解释的工作量。这种情况适合使用分对数菜单。
-
选择模型菜单;在建立模型之前,分析者往往会收集很多变量信息,但是那些变量之间相关,那些变量不相关,那些变量应该纳入模型,那些变量应该剔除,除了根据经验进行选择以外,很难取舍。
选择模型菜单能够对变量进行筛选,帮助分析者筛选出有用的变量,这样就能使原本复杂的模型简化,排除一些变量的影响。
总结一下
以上这些内容的介绍,我们通过方差分析模型引出对数线性模型。大家可以根据这个规律理解清楚对数线性模型的分析逻辑。在SPSS中,根据数据情况的不同,应该选择合适的菜单进行分析,接下来,我们会分别制作文章,详解介绍。
温馨提示:






