摘要:
本文介绍了在入侵检测、实时出价等数据集非常不平衡的领域应用的数据处理技术。
关键字:
平衡数据,数据准备,数据科学
原文:
7 Techniques to Handle Imbalanced Data
http://www.kdnuggets.com/2017/06/7-techniques-handle-imbalanced-data.html
作者:
Ye Wu & Rick Radewagen, IE Business School.
译者:
王安阳
在例如银行欺诈检测、市场实时出价、网络入侵检测等应用场景中,数据集有什么特点?
这些领域中使用的数据,通常只有不到1%是我们“感兴趣”的(例如:使用信用卡的欺诈数据、用户点击广告的数据、损坏的服务器扫描其网络的数据等)。 然而,大多数机器学习算法对于这种不平衡的数据集不能很好地工作。以下七个技巧可以帮助您训练分类器来检测异常类。

对于使用不平衡数据生成的模型,应用不当的评估指标可能是危险的。想象一下,我们的训练数据如上图所示。 如果使用精度来衡量模型的好坏,将所有测试样本分类为“0”的模型将具有很好的准确性(99.8%),但显然这种模型不会为我们提供任何有价值的信息。
在这种情况下,可以应用其他评估指标替代,例如:
-
精确率/特异性:多少个选定的实例是相关的。
-
召回率/灵敏度:选择了多少个相关实例。
-
F1分数:精确率和召回率的加权平衡。
-
MCC:观察和预测的二分类数据之间的相关系数。
-
AUC:真阳性率与伪阳性率之间的关系。
除了使用不同的评估标准外,还可以开发不同的数据集。有两种方法可以从不平衡数据集中生成出平衡的数据集:欠抽样和过抽样。
欠抽样
欠抽样通过减少多数类(数据量占大多数的类别)的样本量来平衡数据集。当数据量足够大时可以使用此方法。
通过保存稀有类(数据量占少数的类别)的所有样本,并在多数类中随机选择相等数量的样本,可以提取出新的平衡的数据集用于进一步建模。
过抽样
与欠抽样相对,过抽样适用于数据量不足的情况。它通过增加稀有类的样本量来平衡数据集。新的稀有类数据可以通过复制,自举法或SMOTE[1](合成过抽样技术)以及其他类似技术来生成。
需要注意,没有一种绝对正确的重抽样方法。如何选用这两种方法取决于应用场合和数据集特点。欠抽样和过抽样相结合也能产生很好的结果。
值得注意的是,使用过抽样方法来解决不平衡问题时应适当地应用交叉验证。
要知道过抽样是根据原有稀有类数据的分布函数,自举生成新的随机数据。 如果在过采样之后应用交叉验证,那么我们将引入过拟合于自举数据的结果。 因此在过抽样数据之前必须进行交叉验证,就像实现特征选择一样。只有反复重采样数据,可以将随机性引入到数据集中,以确保不会出现过拟合的问题。
泛化模型的最简单的方法是使用更多的数据。问题是,开箱即用的分类器,如逻辑回归或随机森林,倾向于通过丢弃稀有类来泛化。一个简单的最佳实践是建立n个模型,分别使用稀有类的所有样本和多数类的n个不同样本。假设要合并10个模型,你需要选取比如 1000个稀有类样本,10000个多数类样本。然后。只需将10000个案例分成10个块,并训练出10个不同的模型。
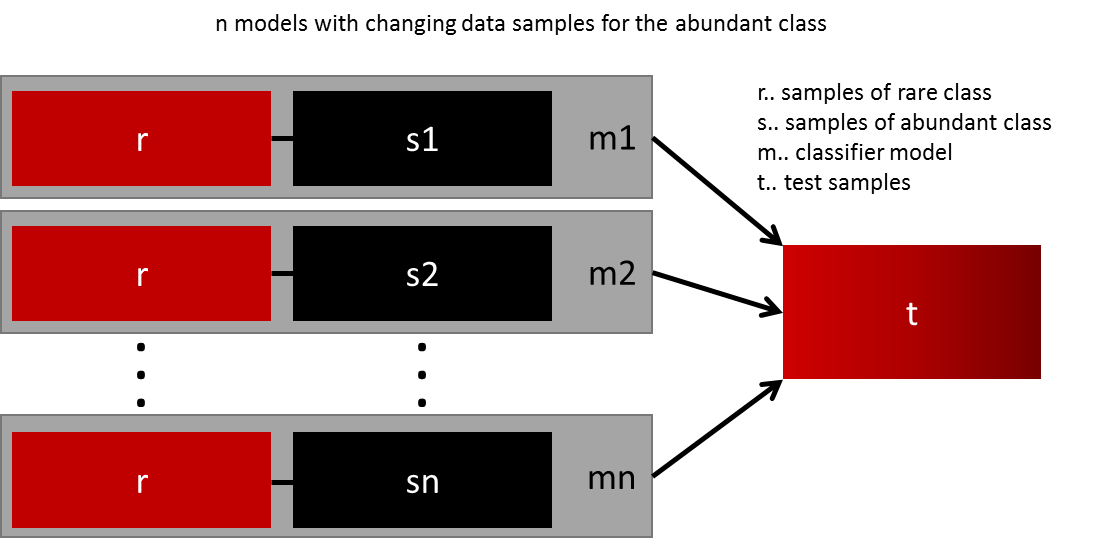
这个方法非常简单,并且可以完美地水平扩展到更大的数据量,因此你可以在不同的集群节点分开训练,然后组合优化模型,可操作性很强。
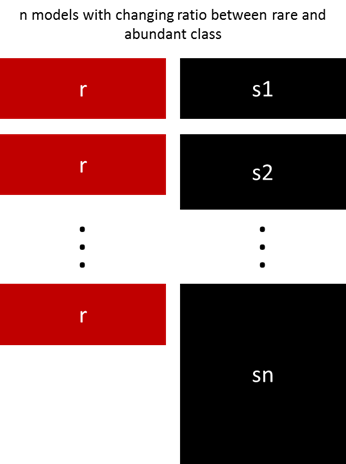
以上的方法可以通过改变稀有类和多数类的样本比例进行微调。 最好的比例在很大程度上取决于所使用的数据和模型。 另外,在不同的分组使用不同的比例,来代替以相同的比例训练所有模型非常值得尝试。 所以如果有10个训练模型,可以有一个模型比例为1:1(稀有:多数),另一个1:3,另一个2:1……,这样做是有意义的。 根据使用的模型,比例可以影响一个类获得的权重。
Sergey提出了一种优雅的方法[2]。他建议不要依赖随机抽样来覆盖训练样本的变化情形,而是对数据集的多数类进行聚类。 对于每个组,只保留集群中心。然后,仅使用稀有类和聚类中心作为训练数据集。








