“在国外,学生可以通过分级阅读了解自己的阅读水平,找到适合自己的阅读内容;而在国内,学生的分级阅读多数停留在以年龄为划分的标准。”赵梓淳对鲸媒体表示,他想通过公司自研的中文分级阅读测评系统解决学生学习语文的难题。
起初,赵梓淳提交给投资人的方案是运用分级阅读提高中国学生的阅读水平,彼时产品还未开发出来,但真格基金创始人徐小平一听是“为中国学生创造福利”,便投了种子轮的融资。他笑言,他的团队成员都很特别,海归、技术大牛、高学历、曾获百万年薪……几乎成了这支团队背后技术力量的“关键词”。
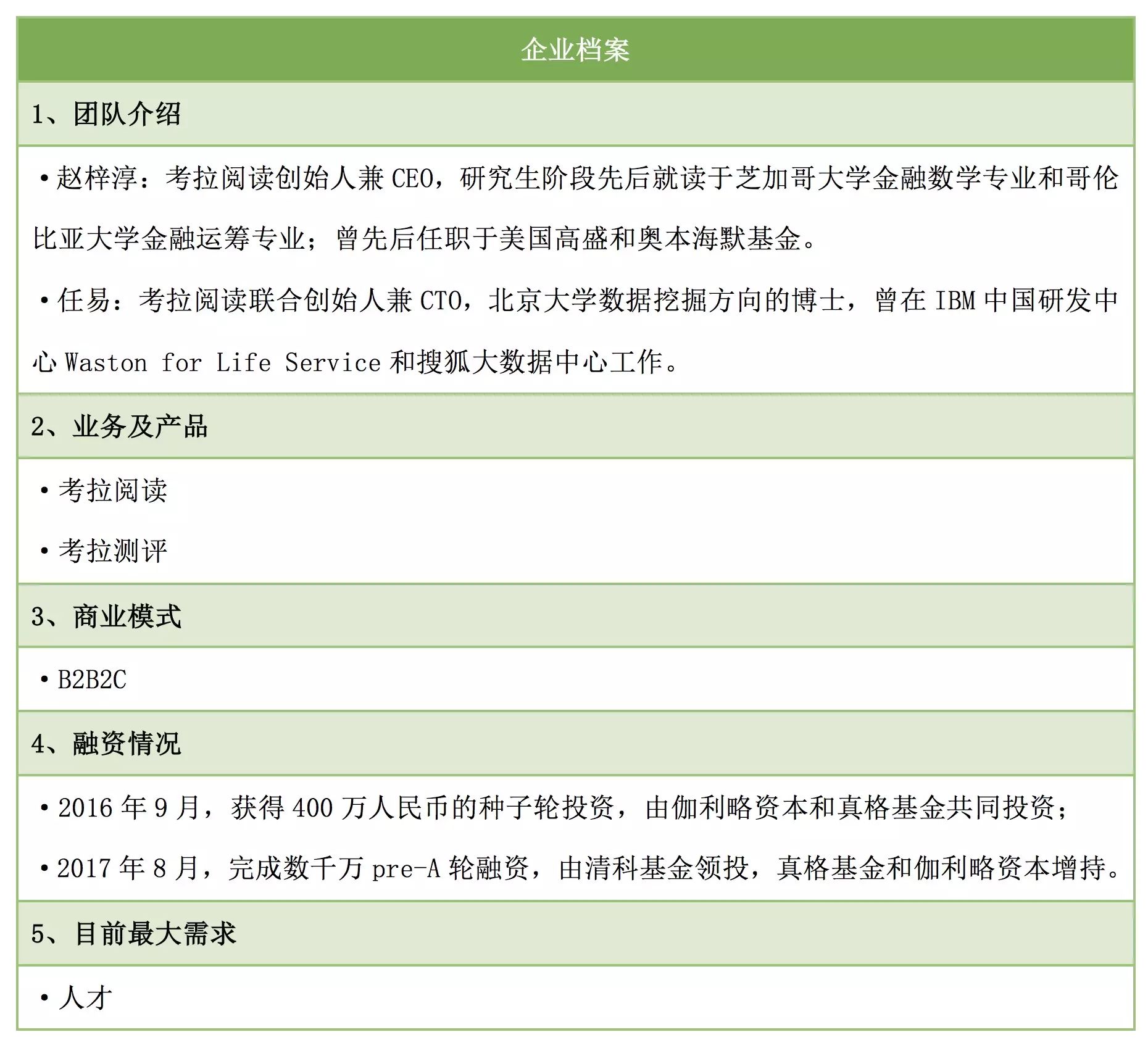
两年前,每天奔波于华尔街的赵梓淳过的是规规矩矩上班族的生活,衣食无忧,但他觉得“这不是自己所想要的生活”,于是决然辞掉在奥本海默基金的工作。2015年底赵梓淳回国创业,经过一番思考便锁定中文分级阅读的创业方向,2016年10月份创办考拉阅读。赵梓淳说,“考拉阅读想做中国版的‘Lexile’。”
相比于英文的分级阅读,中文词义复杂、文本难度无法定义等特点让中文分级阅读标准体系的制定“难于上青天”。面对处理复杂的中文分级体系,考拉阅读是如何破解的?他们又是如何建立起这个体系的?
“阅读《爱丽丝漫游记》的难易程度是450ER,而阅读《安徒生童话》则需要540ER。”赵梓淳介绍,“‘享阅(ER)中文分级标准’就像一把尺子,一方面可以利用中文分级系统测量文本的难易程度;另一方面可以通过阅读能力测评测出学生的中文阅读能力。”
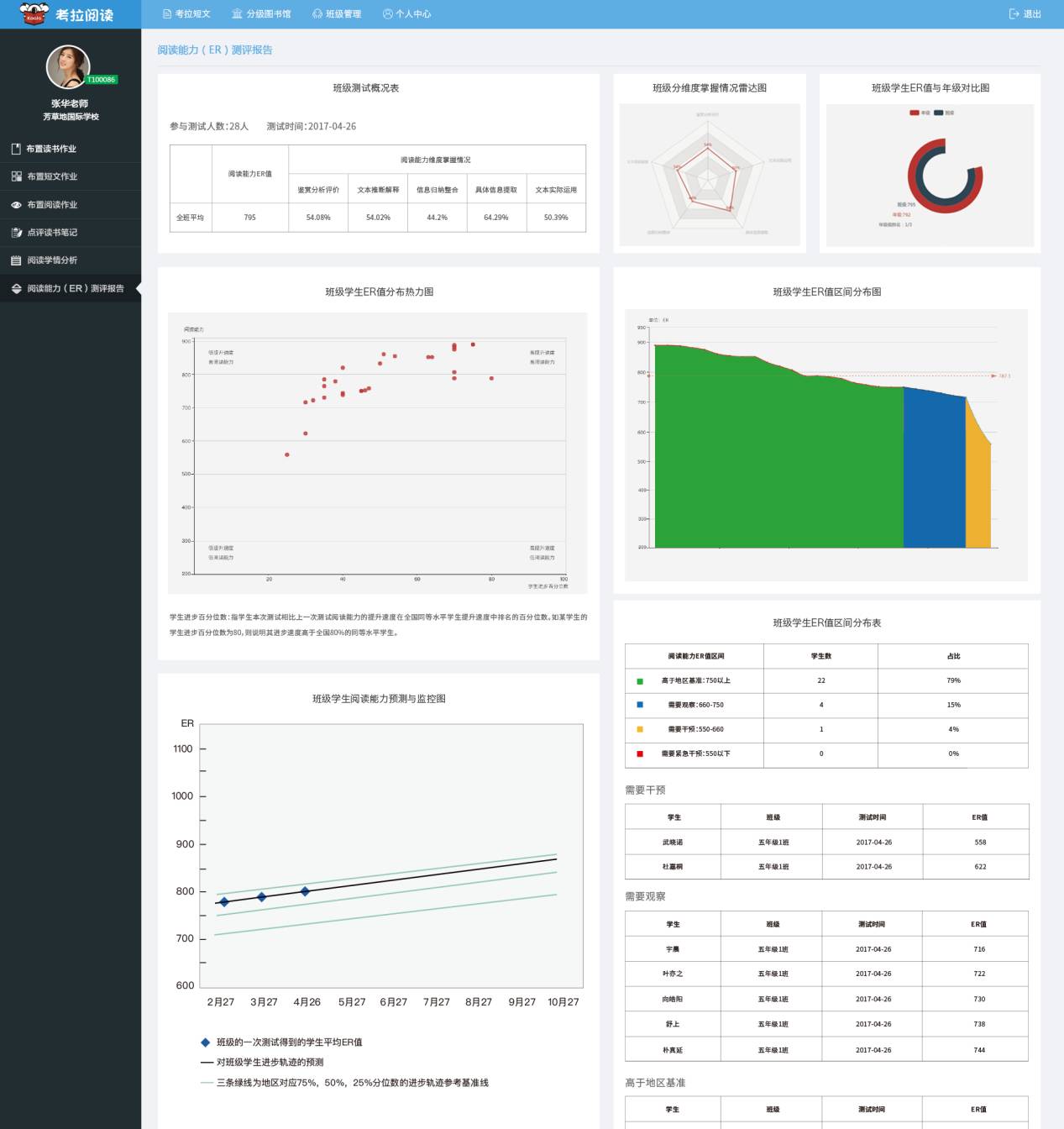
Lexile(蓝思分级)将阅读难度与读者的阅读能力以“L”为单位分成0L—1700L,而考拉阅读以“ER”为单位将文本难度和读者的阅读能力划分为200ER—1300ER之间。当孩子阅读能力为730ER,就可以选择700ER-750ER左右的读物进行阅读,这个难度既不会让孩子因无法驾驭读物而失去信心,也能对孩子现有的能力提出挑战。“当孩子完成每一篇阅读内容之后,系统就会推送一些阅读理解的小测试,孩子可以检测自己对文章的理解程度与阅读水平。”
为了获得更多学生的阅读情况,考拉阅读方面还定义了一套面向中国学生阅读能力的测量表,覆盖一线城市至四线城市,其中有一些比较有意思的数据。“当一个学生的阅读水平达到5.7分时,相当于该学生达到了中国学生五年级第七个月的平均阅读水平。”他继续补充,“如果是一个六年级的学生阅读水平达到5.7分,则说明该学生的阅读水平低于正常发展水平。”
5.7分与上文提到的ER值有何关系?赵梓淳向鲸媒体解释到,“例如学生测出来的阅读能力是780ER,但是很多家长可能很难直观的理解780ER究竟意味着什么。”他表示,“得益于我们对全国范围内学生进行的阅读能力数据采集,可以得出780ER的阅读能力相当于GE分5.7,也就是五年级第七个月的中国学生的平均阅读能力。这样对于家长和老师来说就比较直观了。”[注:GE(Grade Equivalent)分表示该学生阅读能力相当于某个特定年级学习几个月时的阅读能力,如5.5分表示相当于5年级学习5个月时的阅读能力。]
在走访了很多美国公立学校之后,赵梓淳发现美国的分级阅读体系在学校的应用有一套标准的底层逻辑,它可以测试学生的阅读能力,对阅读情况进行可视化的量化,进而匹配相应的自适应学习方案与内容分发;此外,还可以对学生的阅读情况进行干预与纠正。
而国内的分级阅读还并未在校园里形成气候,他感到十分惊讶,“分级阅读在学校的应用基本上是没有的。”分级阅读最早来源于出版社,主要以年龄为划分给学生推送相应的书单。一端是未形成气候的国内分级阅读市场,另一端是如火如荼的国外分级阅读市场。
目前,基于英文文本的分级阅读在国外已经形成成熟的体系,分级阅读已覆盖了美国90%的学校。例如以Lexile分级(蓝思分级)和GE分级为代表的英文分级阅读标准已推行40年,也催生了很多分级阅读教育产品公司,例如Newsela、Renaissance、LightSail等。
看清局面之后,赵梓淳想做一个中国版的Lexile,但国内压根就没有底层的分级标准。“因为美国的新课标规定学生进行大量的阅读,但是中国方面就是要求学生多读经典,多读传统的国学教育。而美国方面就是想让学生建立审辩式的思维,学会怎么去分析内容等。”截然不同的教学目标与要求,分级市场也变得非常微妙。他暗下决心,“分级阅读要进行中国化,才能真正在中国学校里应用起来。”
赵梓淳回忆当时创业的场景,他用“难于上青天”一词向鲸媒体描述了做分级阅读的困难。美国制定分级阅读的质量标准大概花了十年的时间,“相比而言,中文的分级阅读其实要比英语难得多。”他介绍,首先英语的基本组成是二十六个字母,中文最常用的汉字是3600个汉字,中华辞海收入汉字大概8万多个,复杂构成的稀缺性会让中文分析面临一个很大的难题,需要更海量的语料库。“如果用英文那套传统的方式去处理会很难。”
“分析过程中还会遇到处理分词的技术性难题,”他提到,“英文单词是天然的界限,一个单词接着一个单词排列,但是中文没有一个很明确的界限。”他以享阅教育为例给鲸媒体提了一个疑问,“以‘享阅’为一个词去理解,还是以‘教育’为一个词去理解?”他认为,人与人之间对分词的认同率只能达到70%。
处理分词为其次,如何进行表征文本难度解析又是一大难题。他提到,英文文本解析主要取决于两个特征:一个是句子词频,词出现频率越高,词的难度就会越低,越常见就越简单;另一个是句子长度,句子越长,相应的句法结构越复杂,其对应的理解难度会越高。
虽然这个原理看似很简单,但赵梓淳认为,“这个方式放在中文里显然就不适合了。”他认为,对于中文而言,虽然有些句子的出现频率比较低,但其实并不难理解。另外,中文的句子没有很严格的要求,不分主从句、先行词等等,相对而言句子结构比较松散。他表示,这也给中文的语义分析带来了不少的困扰。
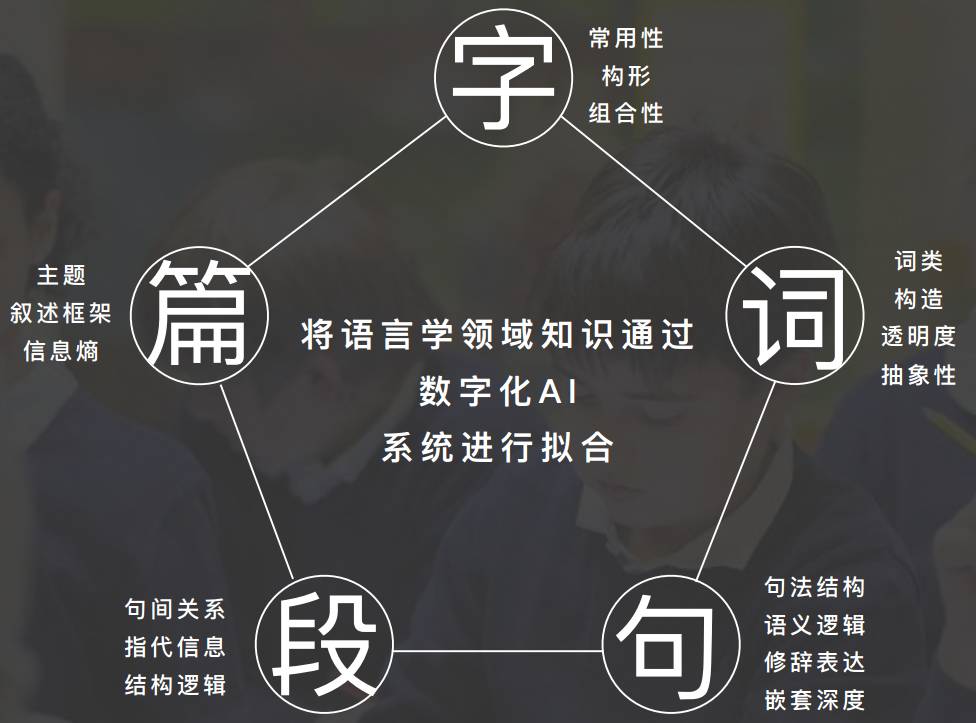
基于这些问题,考拉阅读方面要从何做起呢?考拉阅读将语料依据字、词、句、段、篇五个维度提取了近70种特征进行算法统计。在字方面,考察字的组合性、构型、常用性等等;词方面,考察词的透明性;句方面,考察句法结构、嵌套深度;篇方面,考察段间关系、主题、信息熵等。
赵梓淳以“信息熵”为例,信息熵指的是信息量的大小,“大家都认识‘量子物理’一词,但是有些人就不了解这个意思,也就是这个词的信息量相对于个人的知识结构来说特别大,需要后期的知识储备才知道这个词的意思。” 他透露,目前考拉阅读已经建立大约300万字的非平衡语料库(已经被专家评定过的内容,比如教材)和大约几亿字的平衡语料库(学生日常能接触到各种阅读内容)。
“国外最早的语料库是从1984年开始的,而考拉阅读自研的分级阅读底层系统(又称享阅中文分级系统ER Framework)花了大半年的时间。” 目前的算法团队成员中美国和中国加起来六七个人,此外,考拉还邀请了分级阅读方面、心理认知、心理学方面、语言学方面的各路专家参与分级阅读底层系统的研发。
赵梓淳笑称,“目前系统已经开始进行深度学习,形成大量标注的数据库,使其有能力学习翻译规则,通过订阅用户与特征等数据,提高识别的精度。”他补充说,“系统已经开始像AlphaGo一样开始通过应用层面的大量数据进行校验标准。”此外考拉阅读方面也会依据孩子的做题速度等标准匹配不同的阅读标准。
基于享阅中文分级系统(ER Framework),考拉阅读开发专为K12提供自适应的分级阅读解决方案,分为学生端、教师端和校长端。据赵梓淳的描述,教师可以通过教师端发布阅读任务并跟踪学生的阅读进度,同时获得班级阅读数据,“老师主要是布置阅读任务,可以对学生起到整体性的监控,看到孩子可量化的阅读能力以及可视化的数据。”而校长可以通过校长端获得校级阅读数据报告等。
而学生方面则更有意思,学生可以通过学生端获得取自于教材及考试真题的自适应语文题目,进行阅读能力自测,在可控分数内进行阅读能力的提升训练。目前考拉阅读收录及分级的书本数量达10000+,已初步建立起面向学生的阅读书籍库。
那是否意味着考拉阅读主要应用于应试场景?赵梓淳摇摇头,“应试与素质教育相结合。”素质教育方面,主要集中于看课外书,拓展孩子的课外阅读能力。“我们的产品跟国外的阅读产品类似,如果你的阅读能力处于800 ER,系统就会推送760ER-820ER的阅读内容。”
应试教育方面,考拉阅读提供的内容则是紧扣新课标的教材,阅读之后会有考题的提示。他介绍,考拉阅读还通过教研团队自产了一套语文题库,帮助学生进行阅读理解。例如,当学生读完小蝌蚪找妈妈这篇文章,系统就会推送这样的测试题,“小蝌蚪到底找了几次妈妈?”
赵梓淳向鲸媒体透露,公司目前正在与电子书阅读平台掌阅进行内容方面的战略合作。“孩子阅读完之后,系统还会有30-100道题来考察孩子是否看懂这本书。” 依据教育心理学概念,赵梓淳自信地认为,考拉阅读所推送的内容会更趋于学生的“最近发展区”,也就是始终让孩子学到的东西保持在最佳水平。
鲸媒体注意到,当读者读完《了不起的狐狸爸爸》这部书时,系统会推送一些选择题来考察孩子是否看懂这本书,例如,“在《比恩的秘密苹果酒窖》中,老鼠可以被什么动物吃掉?”“在《博吉斯的1号鸡舍》中,狐狸先生为什么要把掀开的木板再拉下来”等等。当学生提交测试答案之后会得到实际应用、整体感知、获取信息、形成解释、做出评价这五个维度的数据;如果测评过关,孩子就不用再进行测评;反之,孩子可以选择是否继续挑战,或者下次继续测试。
初创的时候,考拉阅读的第一笔融资主要是真格基金投资的。当时,赵梓淳提交给投资人的方案是运用分级阅读提高中国学生的阅读水平,但彼时产品还未开发出来,真格基金创始人徐小平一听是“为中国学生创造福利”,便投了种子轮的融资。前不久,考拉阅读的Pre-A轮融资也获得了真格基金的增持。
赵梓淳向鲸媒体透露,Pre-A轮融资完成后,主要会用于底层人工智能技术的积累、产品的更新迭代以及市场推广。对于下半年的工作计划,赵梓淳透露,将会集中在天津拓展100万的公立学校用户;与权威的出版机构达成合作;面向全国的中小学开展大量的评测工作。“大量测评数据的积累也能够提供大数据的底层能力。”
测评方面,基于享阅中文分级系统(ER Framework),考拉阅读延伸了考拉测评,主要分为WEB端和APP,以测试学生的阅读能力为主。“通过人工智能发展智能语音、自适应学习系统以及基于底层文本的ER Framework系统,为孩子匹配最适合书籍。”今年9月份,考拉阅读对全国的小学生开展测评活动,赵梓淳把这一环节概括为“千头万绪”。
考虑到公信力的问题,目前考拉阅读的产品主要面向B端,以进公立学校的形式,目前已经与200多所学校达成战略合作。同样的,在提高公信力方面,考拉阅读接下来还会与北师大联合发布全国中小学阅读能力报告。那是否会拓展一些C端的资源?赵梓淳的回答是,目前C端暂时不会考虑拓展更多的内容。“C端用户同样也可以使用考拉阅读APP,但不能使用班级功能。”
当问起考拉阅读的最大壁垒在哪里?赵梓淳总是会提到他们的技术核心团队。目前技术和教研团队各有20余人,截至目前公司总共有56人。创业迷茫之时,赵梓淳遇到合伙人,也就是CTO任易。任易是北京大学数据挖掘方向的博士,曾在IBM中国研发中心Waston for Life Service和搜狐大数据中心工作;首席科学家Jake Zhao曾在Facebook从事研究工作,师从于机器学习顶尖学者、深度学习的奠基人之一Yann LeCun教授。
赵梓淳是学量化金融出身,这门专业与数据相关,其实本质就是利用数据驱动服务,跟考拉现在用数据驱动语文学科异曲同工。他谈到,“分级阅读在国内暂未有成型的公司,而美国在这一领域的经营已形成了百亿美金的赛道,也涌现了几家估值过亿(美金)的公司。”
前不久,教育部统编义务教育三科教材,其中就包括语文教材,而国学和阅读是语文教材改编之后最重视的两部分内容,问及这对于考拉阅读的测评会产生怎样的影响?赵梓淳笃定地回答,“算是正影响。” 面对国内中文分级阅读的蓝海市场,考拉阅读是否能够用AI改变语文学科阅读?
关注鲸媒体,回复 蓝皮书 了解购买《中国中小学创客教育行业蓝皮书(2016-2017)》
▼点击阅读原文进入【鲸媒体小铺】,购买【创客教育行业全图】