
图源:unsplash
原文来源
:arXiv
作者:
Guillaume Lample、Myle Ott、Alexis Conneau、Ludovic Denoyer、Marc’Aurelio Ranzato
「雷克世界」编译:嗯~是阿童木呀、KABUDA、EVA
机器翻译系统在某些语言上实现了接近人类水平的性能,但是其有效性很大程度上依赖于大量双语文本(bitext)的可用性,这阻碍了它们对大多数语言对(language pair)的适应性。本研究探究了如何在每一种语言中只能使用大型单语语料库(monolingual corpora)的情况下学习翻译。我们提出了两种模型变体,一个是神经模型,另一个是基于短语的模型。二者都通过在另一个方向上应用反向模型进行的反向翻译,利用了平行数据的自动生成,还利用了在目标端进行训练的语言模型的去噪效果。这两种模型明显优于从以往研究文献中得到的方法,而且更简单,并具有更少的超参数(hyper-parameter)。在广泛使用的WMT'14英语-法语和WMT'16德语-英语基准测试中,我们的模型在没有使用单个平行语句的情况下,分别获得了27.1和23.6个BLEU点,这优于当前最先进技术11个BLEU点。
可以这样说,机器翻译(Machine Translation,MT)是在自然语言处理领域最近所取得的成功和进步的旗舰。它的实际应用以及用作序列转导算法(sequence transduction algorithms)的测试平台,已经激发了人们对这个主题的兴趣。
虽然最近的研究进展表明了使用神经方法在几种语言对上取得了接近人类水平的性能(Wu等人于2016年提出;Hassan等人于2018年提出),但是其他研究强调了一些公开的挑战(Koehn和Knowles于2017年提出;Isabelle等人于2017年提出;Sennrich于2017年提出)。其中一个主要的挑战是当前学习算法对大型平行语料库的依赖。不幸的是,绝大多数的语言对都基本没有什么平行数据:学习算法需要更好地利用单语数据,从而使MT得到更广泛的适用。
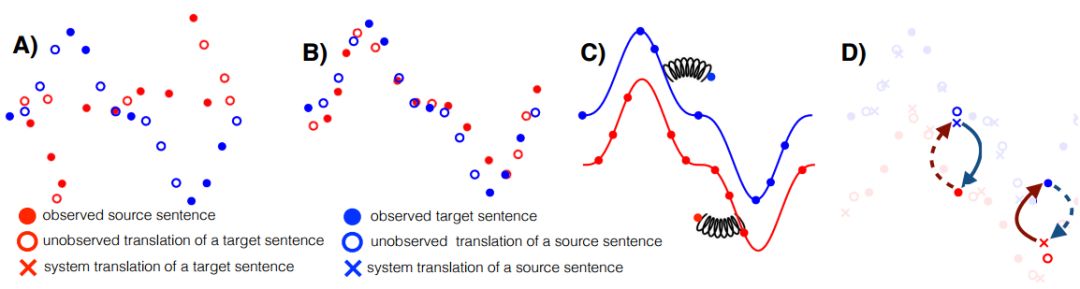
图1:简图说明了无监督MT的三个原则。A)有两种单语言数据集。标记对应于句子(详见图例)。B)第一原则:初始化。两个分布大致对齐,例如,通过用推断的双语词典进行逐词翻译。C)第二原则:语言建模。语言模型在每个域中独立学习以推断数据结构(基础连续曲线);它充当数据驱动的先验以降噪或纠正句子。D)第三原则:回译。从观察到的源语句(填充的红色圆圈)开始,我们使用当前源→目标模型翻译(虚线箭头),产生潜在的不正确翻译(空心圆附近的蓝色十字)。从这个(back)翻译开始,我们使用目标→源模型(连续箭头)以重构原始语言中的句子。重构和初始句子之间的差异提供的误差信号用以训练目标→源模型参数。在相反的方向上应用相同的过程来训练源→目标模型
大量文献研究了在有限的监督下使用单语数据来提高翻译性能。这种有限的监督通常以一组相对少量的平行语句的形式提供(Sennrich等人于2015年提出;Gulcehre等人于2015年提出;He等人于2016年提出;Gu等人于2018年提出;Wang等人于2018年提出),或者是以其他相关语言中的一组大量的平行语句(Firat等人于2016年提出;Johnson等人于2016年提出; Chen 等人于2017年提出;Zheng等人于2017年提出)或双语词典(Klementiev等人于2012年提出;Irvine和Callison-Burch于2014年、2016年提出)或可比较的语料库(Munteanu等人于2004年提出;Irvine和Callison-Burch于 2013年提出)的形式提供。
相比之下,研究人员最近已经提出了两种完全无监督的方法(Lample等人于2018年提出;Artetxe等人于2018年提出),它们在每一种语言中仅依赖于单语语料库,就像Ravi和Knight(于2011年提出)的开创性研究一样。
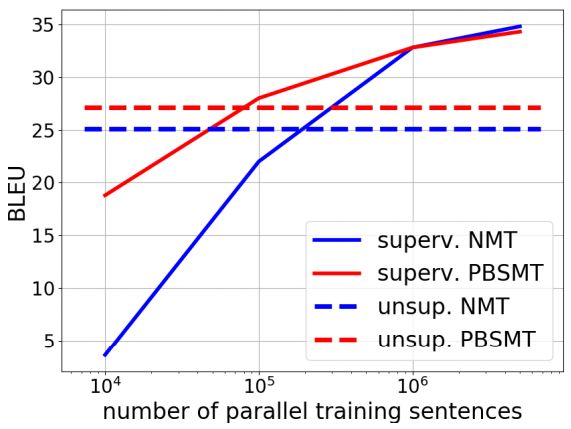
图2:因为我们改变了监督方法中的平行句子的数量,所以在WMT'14 En-Fr中对有监督和无监督方法进行比较。
虽然这两个近期研究成果之间存在着细微的技术差异,但我们发现了其成功背后的几种常见因素。首先,他们用一个推理出的双语词典对模型进行仔细的初始化。其次,他们通过训练序列到序列系统(sequence-to-sequence,Sutskever等人于2014年、Bahdanau等人于2015年提出)作为一个去噪的自编码器(Vincent等人于2008年提出),利用强大的语言模型。再次,他们通过回译(back-translation,Sennrich等人于2015年提出)自动生成句对,将无监督问题转化为监督问题。在回译中,主要思想是维护两个模型,一个用于将源翻译为目标,另一个则用于将目标翻译为源。前者模型产生数据用以训练后者,反之亦然。最后一个共同特性是,这些模型约束了编码器所产生的潜在表示在两种语言之间的共享。将这些片段组合在一起,无论输入语言是怎样的,编码器都会生成相似的表示形式。解码器既可以作为语言模型,也可以作为一个噪声输入的翻译器进行训练,学习与后向模型(从目标到源)的协同工作,以产生越来越好的翻译。这个迭代过程在完全无监督的环境中实现了显著的结果,例如,WMT'14英语—法语基准测试中获得大约15个BLEU点。
在本文中,我们提出了一个结合了上述两种神经方法的模型,在遵循上述原则的同时简化了体系架构和损失函数。由此产生的模型的性能要优于以前的方法,并且更容易进行训练和调整。然后,我们将相同的想法和方法应用于传统的基于短语的统计机器翻译(PBSMT)系统(Koehn等人于2003年提出)。众所周知,当标记的数据是稀疏的时候,PBSMT模型优于神经模型,因为它们只是计算发生的次数,而神经模型通常要拟合数以百万计的参数以学习分布式表示,当数据丰富,它可能会更好进行泛化,但当数据稀疏时,却容易出现过度拟合的现象。我们的PBSMT模型简单易懂,训练速度快,并且通常可以达到与NMT相似或更好的结果。在使用我们的NMT模型时,结果显示在广泛使用的基准上最多可获得+10 BLEU点的增益,而使用我们的PBSMT模型时可获得+12点的增益。这显著提高了无监督环境下的最先进技术水平。
无监督MT原则
仅通过单语数据学习翻译是一项不适定任务,因为将目标语句与源语句相关联的方法有很多。然而,正如我们在下文中所论述的那样,近年来,在解决这一问题方面,取得了鼓舞人心的进展。在该部分,我们不讲述近期工作的具体内容,而是把重点放在无监督MT共同遵循的原则上。
我们表示,无监督MT可以通过由图一所示的三部分要素构成:适当的初始化、语言建模、迭代回译。接下来,我们将逐个介绍每一项内容,并探讨如何在神经模型和基于短语的模型中将其实例化。
初始化
由于无监督翻译是一项不适定任务,因此我们可以通过一组自然先验来表达我们期望的解决方案,即初始化模型,从而使单词、短语甚至子词单元(Sennrich等人于2015年提出)对齐。例如,Klementiev等人在2012年使用了已有的双语词典,而Lample等人和Artetxe等人则在2018年使用了利用无监督方式推导出的词典(Conneau等人于2018年,Artetxe等人于2017年提出)。它为我们带来的启发是,这种对齐可以被用于实现初级的“逐词”翻译。尽管如果语言和语料库没有密切联系,它可能会导致翻译不佳,但它仍然可以保留一部分原始语义。
语言建模
鉴于存在大量单语数据,我们可以在源语言和目标语言上训练语言模型。这些模型提供了一种在不同语言环境下阅读句子的数据驱动的先验。它们通过对单词执行局部替换和重新排序,来提高翻译质量。
迭代回译
第三要素是回译(Sennrich等人于2015年提出),这可能是在半监督环境下利用单语数据的最有效方式。它在无监督环境下的应用,是将机器翻译系统,与一个从目标语言到源语言的回译模型相耦合。该模型的作用是为单语语料库中的每一个目标语句,生成一个源语句。尽管含有噪声源语句,但这仍可以将令人望而生畏的无监督问题,转化为监督学习任务。随着原始模型在翻译方面的表现愈发完善,我们也可以使用当前模型来改进回译模型,从而产生迭代算法(He等人于2016年提出)。
结论及未来工作
在该项研究工作中,我们综合了近期在完全无监督机器翻译方面取得成功的三项原则:
•适当的初始化(例如:推导双语词典)
•利用强大的语言模型
•利用人工生成的平行数据通过回译进行迭代训练
基于这些原则,我们提出了一个简化的神经模型和一个新的基于短语的MT模型。这些模型在多个基准数据集和语言对之间实现了最先进的翻译性能,在某些情况下,还可以通过大约+12BLEU点的提升改进了以往的最佳模型。然后,我们证明了,通过将神经模型与基于短语的模型相结合,可以实现性能的进一步提升。
今后,我们将进一步研究以无监督方式对齐的具有n-grams的短语表的初始化问题。最后,我们计划研究该如何将这些方法泛化至半监督环境,以及在其他语言对中含有大量标记数据的环境中。
原文链接:
https://arxiv.org/pdf/1804.07755.pdf
欢迎个人分享,媒体转载请后台回复「转载」获得授权,微信搜索「raicworld」关注公众号




