
先看现象
涉及诸如float或者double这两种浮点型数据的处理时,偶尔总会有一些
怪怪的现象
,不知道大家注意过没,举几个常见的栗子:
典型现象(一):条件判断超预期
System.out.println( 1f == 0.9999999f ); // 打印:false
System.out.println( 1f == 0.99999999f ); // 打印:true 纳尼?
典型现象(二):数据转换超预期
float f = 1.1f;
double d = (double) f;
System.out.println(f); // 打印:1.1
System.out.println(d); // 打印:1.100000023841858 纳尼?
典型现象(三):基本运算超预期
System.out.println( 0.2 + 0.7 );
// 打印:0.8999999999999999 纳尼?
典型现象(四):数据自增超预期
float f1 = 8455263f;
for (int i = 0; i 10; i++) {
System.out.println(f1);
f1++;
}
// 打印:8455263.0
// 打印:8455264.0
// 打印:8455265.0
// 打印:8455266.0
// 打印:8455267.0
// 打印:8455268.0
// 打印:8455269.0
// 打印:8455270.0
// 打印:8455271.0
// 打印:8455272.0
float f2 = 84552631f;
for (int i = 0; i 10; i++) {
System.out.println(f2);
f2++;
}
// 打印:8.4552632E7 纳尼?不是 +1了吗?
// 打印:8.4552632E7 纳尼?不是 +1了吗?
// 打印:8.4552632E7 纳尼?不是 +1了吗?
// 打印:8.4552632E7 纳尼?不是 +1了吗?
// 打印:8.4552632E7 纳尼?不是 +1了吗?
// 打印:8.4552632E7 纳尼?不是 +1了吗?
// 打印:8.4552632E7 纳尼?不是 +1了吗?
// 打印:8.4552632E7 纳尼?不是 +1了吗?
// 打印:8.4552632E7 纳尼?不是 +1了吗?
// 打印:8.4552632E7 纳尼?不是 +1了吗?
看到没,这些简单场景下的使用情况都很难满足我们的需求,所以说用浮点数(包括
double
和
float
)处理问题有非常多
隐晦的坑
在等着咱们!
怪不得技术总监发狠话:谁要是敢在处理诸如
商品金额、订单交易、以及货币计算
时用浮点型数据(
double/float
),直接让我们走人!

原因出在哪里?
我们就以第一个典型现象为例来分析一下:
System.out.println( 1f == 0.99999999f );
直接用代码去比较1和0.99999999,居然打印出
true
!

这说明了什么?这说明了计算机压根区分不出来这两个数。这是为什么呢?
我们不妨来简单思考一下:
我们知道输入的这两个浮点数只是我们人类肉眼所看到的具体数值,是我们通常所理解的十进制数,但是计算机底层在计算时可不是按照十进制来计算的,学过基本计组原理的都知道,计算机底层最终都是基于像010100100100110011011这种0、1二进制来完成的。
所以为了搞懂实际情况,我们应该将这两个十进制浮点数转化到二进制空间来看一看。
十进制浮点数转二进制
直接给出结果(把它转换到IEEE 754 Single precision 32-bit,也就float类型对应的精度)
1.0(十进制)
↓
00111111 10000000 00000000 00000000(二进制)
↓
0x3F800000(十六进制)
0.99999999(十进制)
↓
00111111 10000000 00000000 00000000(二进制)
↓
0x3F800000(十六进制)
果不其然,
这两个十进制浮点数的底层二进制表示是一毛一样的,怪不得==的判断结果返回true!
但是
1f == 0.9999999f
返回的结果是符合预期的,打印
false
,我们也把它们转换到二进制模式下看看情况:
1.0(十进制)
↓
00111111 10000000 00000000 00000000(二进制)
↓
0x3F800000(十六进制)
0.9999999(十进制)
↓
00111111 01111111 11111111 11111110(二进制)
↓
0x3F7FFFFE(十六进制)
哦,很明显,它俩的二进制数字表示确实不一样,这是理所应当的结果。
那么为什么0.99999999的底层二进制表示竟然是:00111111 10000000 00000000 00000000呢?
这不明明是浮点数1.0的二进制表示吗?
这就要谈一下浮点数的精度问题了。
浮点数的精度问题!
学过 《计算机组成原理》 这门课的小伙伴应该都知道,浮点数在计算机中的存储方式遵循IEEE 754 浮点数计数标准,可以用科学计数法表示为:
只要给出:
符号(S)、阶码部分(E)、尾数部分(M)
这三个维度的信息,一个浮点数的表示就完全确定下来了,所以float和double这两种浮点数在内存中的存储结构如下所示:
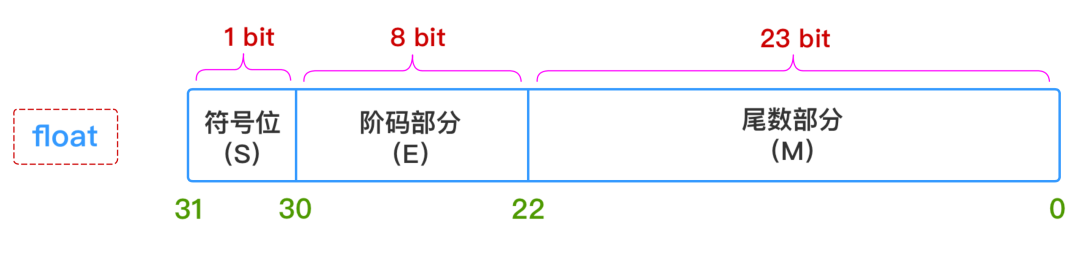
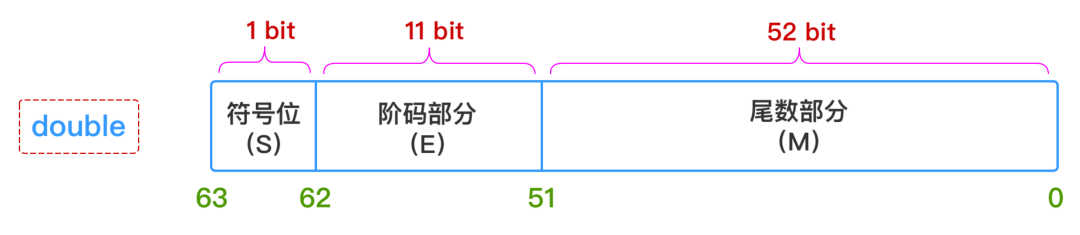
1、符号部分(S)
0-正 1-负
2、阶码部分(E)(指数部分):
-
对于
float
型浮点数,指数部
分8
位,考虑可正可负,因此可以表示的指数范围为
-127 ~ 128
-
对于
double
型浮点数,指数部分
11
位,考虑可正可负,因此可以表示的指数范围为
-1023 ~ 1024
3、尾数部分(M):
浮点数的精度是由尾数的位数来决定的:
-
对于
float
型浮点数,尾数部分
23
位,换算成十进制就是
2^23=8388608
,所以十进制精度只有
6 ~ 7
位;
-
对于
double
型浮点数,尾数部分
52
位,换算成十进制就是
2^52 = 4503599627370496
,所以十进制精度只有
15 ~ 16
位
所以对于上面的数值
0.99999999f
,很明显已经超过了
float
型浮点数据的精度范围,出问题也是在所难免的。
精度问题如何解决?
所以如果涉及
商品金额、交易值、货币计算
等这种对精度要求很高的场景该怎么办呢?










