选自 Analytics Vidhya
作者:
ANKIT GUPTA
机器之心编译
参与:机器之心编辑部
目前机器学习是最抢手的技能之一。如果你是一名数据科学家,那就需要对机器学习很擅长,而不只是三脚猫的功夫。作为 DataFest 2017 的一部分,Analytics Vidhya 组织了不同的技能测试,从而数据科学家可以就这些关键技能进行自我评估。测试包括机器学习、深度学习、时序问题以及概率。这篇文章将给出机器学习测试问题的解答。你可以通过链接获得其他测试问题及解答。
-
深度学习:https://www.analyticsvidhya.com/blog/2017/04/40-questions-test-data-scientist-deep-learning/
-
时序问题:https://www.analyticsvidhya.com/blog/2017/04/40-questions-on-time-series-solution-skillpower-time-series-datafest-2017/
-
概率:https://www.analyticsvidhya.com/blog/2017/04/40-questions-on-probability-for-all-aspiring-data-scientists/
在本文的机器学习测试中,超过 1350 人注册参与其中。该测试可以检验你对机器学习概念知识的掌握,并为你步入业界做准备。如果错过了实时测试,没有关系,你可以回顾本文以自我提升。机器之心对这些试题及解答进行了编译介绍。你能答对多少题呢?不妨与我们分享。
整体分数分布
下面给出了测试得分的分布,希望能帮助你了解一下自己的水平。成绩单也可以看这里:https://datahack.analyticsvidhya.com/contest/skillpower-machine-learning/lb
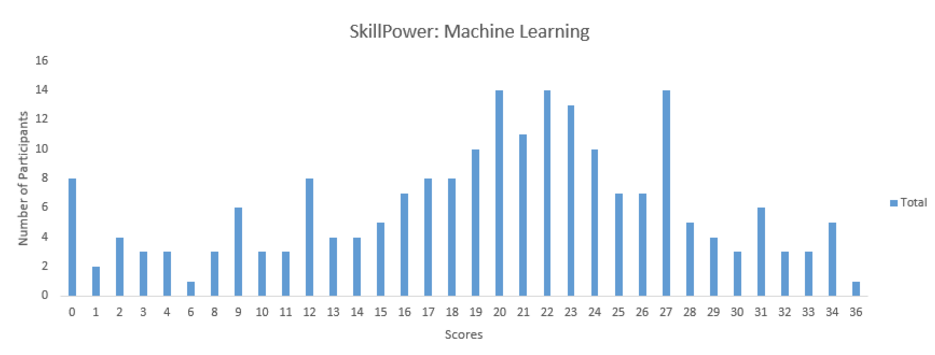
目前已有 210 人参与了这些试题的测试,最高分为 36。平均得分为 19.36,中位数为 21,最常出现的得分(Mode Score)为 27。
测试题与解答
假定特征 F1 可以取特定值:A、B、C、D、E 和 F,其代表着学生在大学所获得的评分。现在请答题:
1. 在下面说法中哪一项是正确的?
A. 特征 F1 是名义变量(nominal variable)的一个实例。
B. 特征 F1 是有序变量(ordinal variable)的一个实例。
C. 该特征并不属于以上的分类。
D. 以上说法都正确。
答案为(B):有序变量是一种在类别上有某些顺序的变量。例如,等级 A 就要比等级 B 所代表的成绩好一些。
2. 下面哪个选项中哪一项属于确定性算法?
A.PCA
B.K-Means
C. 以上都不是
答案为(A):确定性算法表明在不同运行中,算法输出并不会改变。如果我们再一次运行算法,PCA 会得出相同的结果,而 k-means 不会。
3. 两个变量的 Pearson 相关性系数为零,但这两个变量的值同样可以相关。
A. 正确
B. 错误
答案为(A):Y=X2,请注意他们不仅仅相关联,同时一个还是另一个的函数。尽管如此,他们的相关性系数还是为 0,因为这两个变量的关联是正交的,而相关性系数就是检测这种关联。详情查看:https://en.wikipedia.org/wiki/Anscombe's_quartet
4. 下面哪一项对梯度下降(GD)和随机梯度下降(SGD)的描述是正确的?
-
在 GD 和 SGD 中,每一次迭代中都是更新一组参数以最小化损失函数。
-
在 SGD 中,每一次迭代都需要遍历训练集中的所有样本以更新一次参数。
-
在 GD 中,每一次迭代需要使用整个训练集或子训练集的数据更新一个参数。
A. 只有 1
B. 只有 2
C. 只有 3
D.1 和 2
E.2 和 3
F. 都正确
答案为(A):在随机梯度下降中,每一次迭代选择的批量是由数据集中的随机样本所组成,但在梯度下降,每一次迭代需要使用整个训练数据集。
5. 下面哪个/些超参数的增加可能会造成随机森林数据过拟合?
-
树的数量
-
树的深度
-
学习速率
A. 只有 1
B. 只有 2
C. 只有 3
D.1 和 2
E.2 和 3
F. 都正确
答案为(B):通常情况下,我们增加树的深度有可能会造成模型过拟合。学习速率在随机森林中并不是超参数。增加树的数量可能会造成欠拟合。
6. 假如你在「Analytics Vidhya」工作,并且想开发一个能预测文章评论次数的机器学习算法。你的分析的特征是基于如作者姓名、作者在 Analytics Vidhya 写过的总文章数量等等。那么在这样一个算法中,你会选择哪一个评价度量标准?
-
均方误差
-
精确度
-
F1 分数
A. 只有 1
B. 只有 2
C. 只有 3
D. 1 和 3
E. 2 和 3
F. 1 和 2
答案为(A):你可以把文章评论数看作连续型的目标变量,因此该问题可以划分到回归问题。因此均方误差就可以作为损失函数的度量标准。
7. 给定以下三个图表(从上往下依次为1,2,3). 哪一个选项对以这三个图表的描述是正确的?
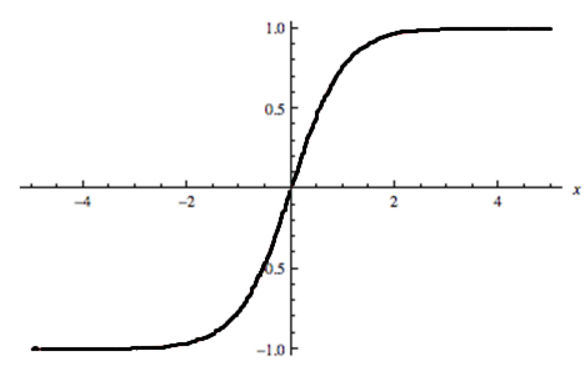
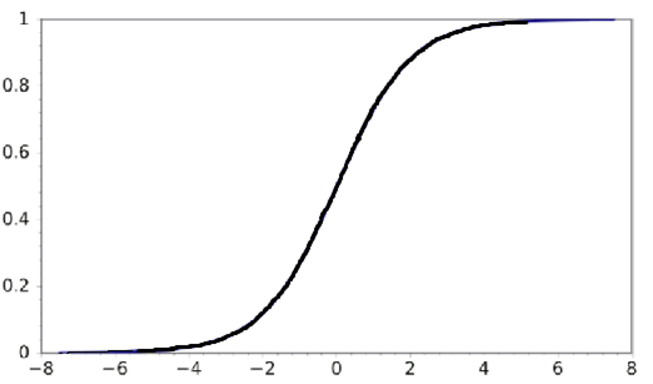
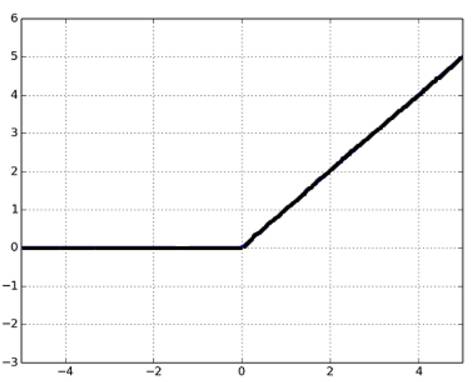
A. 1 是 tanh,2 是 ReLU,3 是 SIGMOID 激活函数
B. 1 是 SIGMOID,2 是 ReLU,3 是 tanh 激活函数
C. 1 是 ReLU,2 是 tanh,3 是 SIGMOID 激活函数
D. 1 是 tanh,2 是 SIGMOID,3 是 ReLU 激活函数
答案为(D):因为 SIGMOID 函数的取值范围是 [0,1],tanh 函数的取值范围是 [-1,1],RELU 函数的取值范围是 [0,infinity]。
8. 以下是目标变量在训练集上的 8 个实际值 [0,0,0,1,1,1,1,1],目标变量的熵是所少?
A. -(5/8 log(5/8) + 3/8 log(3/8))
B. 5/8 log(5/8) + 3/8 log(3/8)
C. 3/8 log(5/8) + 5/8 log(3/8)
D. 5/8 log(3/8) – 3/8 log(5/8)
答案为(A):信息熵的公式为:
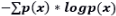
9. 假定你正在处理类属特征,并且没有查看分类变量在测试集中的分布。现在你想将 one hot encoding(OHE)应用到类属特征中。那么在训练集中将 OHE 应用到分类变量可能要面临的困难是什么?
A. 分类变量所有的类别没有全部出现在测试集中
B. 类别的频率分布在训练集和测试集是不同的
C. 训练集和测试集通常会有一样的分布
D. A 和 B 都正确
E. 以上都不正确
答案为(D):A、B 项都正确,如果类别在测试集中出现,但没有在训练集中出现,OHE 将会不能进行编码类别,这将是应用 OHE 的主要困难。选项 B 同样也是正确的,在应用 OHE 时,如果训练集和测试集的频率分布不相同,我们需要多加小心。
10.Skip gram 模型是在 Word2vec 算法中为词嵌入而设计的最优模型。以下哪一项描绘了 Skip gram 模型?
A. A
B. B
C. A 和 B
D. 以上都不是
答案为(B):这两个模型都是在 Word2vec 算法中所使用的。模型 A 代表着 CBOW,模型 B 代表着 Skip gram。
11. 假定你在神经网络中的隐藏层中使用激活函数 X。在特定神经元给定任意输入,你会得到输出「-0.0001」。X 可能是以下哪一个激活函数?
A. ReLU
B. tanh
C. SIGMOID
D. 以上都不是
答案为(B):该激活函数可能是 tanh,因为该函数的取值范围是 (-1,1)。
12. 对数损失度量函数可以取负值。
A. 对
B. 错
答案为(B):对数损失函数不可能取负值。
13. 下面哪个/些对「类型 1(Type-1)」和「类型 2(Type-2)」错误的描述是正确的?
-
类型 1 通常称之为假正类,类型 2 通常称之为假负类。
-
类型 2 通常称之为假正类,类型 1 通常称之为假负类。
-
类型 1 错误通常在其是正确的情况下拒绝假设而出现。
A. 只有 1
B. 只有 2
C. 只有 3
D. 1 和 2
E. 1 和 3
F. 3 和 2
答案为(E):在统计学假设测试中,I 类错误即错误地拒绝了正确的假设(即假正类错误),II 类错误通常指错误地接受了错误的假设(即假负类错误)。
14. 下面在 NLP 项目中哪些是文本预处理的重要步骤?
-
词干提取(Stemming)
-
移去停止词(Stop word removal)
-
目标标准化(Object Standardization)
A. 1 和 2
B. 1 和 3
C. 2 和 3
D. 1、2 和 3
答案为(D):词干提取是剥离后缀(「ing」,「ly」,「es」,「s」等)的基于规则的过程。停止词是与语境不相关的词(is/am/are)。目标标准化也是一种文本预处理的优良方法。
15. 假定你想将高维数据映射到低维数据中,那么最出名的降维算法是 PAC 和 t-SNE。现在你将这两个算法分别应用到数据「X」上,并得到数据集「X_projected_PCA」,「X_projected_tSNE」。下面哪一项对「X_projected_PCA」和「X_projected_tSNE」的描述是正确的?
A. X_projected_PCA 在最近邻空间能得到解释
B. X_projected_tSNE 在最近邻空间能得到解释
C. 两个都在最近邻空间能得到解释
D. 两个都不能在最近邻空间得到解释
答案为(B):t-SNE 算法考虑最近邻点而减少数据维度。所以在使用 t-SNE 之后,所降的维可以在最近邻空间得到解释。但 PCA 不能。
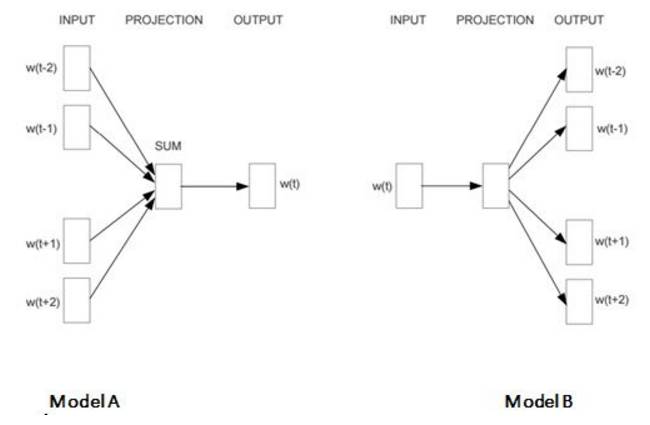
16-17 题的背景:给定下面两个特征的三个散点图(从左到右依次为图 1、2、3)。
16. 在上面的图像中,哪一个是多元共线(multi-collinear)特征?
A. 图 1 中的特征
B. 图 2 中的特征
C. 图 3 中的特征
D. 图 1、2 中的特征
E. 图 2、3 中的特征
F. 图 1、3 中的特征
答案为(D):在图 1 中,特征之间有高度正相关,图 2 中特征有高度负相关。所以这两个图的特征是多元共线特征。
17. 在先前问题中,假定你已经鉴别了多元共线特征。那么下一步你可能的操作是什么?
-
移除两个共线变量
-
不移除两个变量,而是移除一个
-
移除相关变量可能会导致信息损失。为了保留这些变量,我们可以使用带罚项的回归模型(如 ridge 或 lasso regression)。
A. 只有 1
B. 只有 2
C. 只有 3
D. 1 或 3
E. 1 或 2
答案为(E):因为移除两个变量会损失一切信息,所以我们只能移除一个特征,或者也可以使用正则化算法(如 L1 和 L2)。
18. 给线性回归模型添加一个不重要的特征可能会造成:
-
增加 R-square
-
减少 R-square
A. 只有 1 是对的
B. 只有 2 是对的
C. 1 或 2 是对的
D. 都不对
答案为(A):在给特征空间添加了一个特征后,不论特征是重要还是不重要,R-square 通常会增加。
19. 假设给定三个变量 X,Y,Z。(X, Y)、(Y, Z) 和 (X, Z) 的 Pearson 相关性系数分别为 C1、C2 和 C3。现在 X 的所有值加 2(即 X+2),Y 的全部值减 2(即 Y-2),Z 保持不变。那么运算之后的 (X, Y)、(Y, Z) 和 (X, Z) 相关性系数分别为 D1、D2 和 D3。现在试问 D1、D2、D3 和 C1、C2、C3 之间的关系是什么?
A. D1= C1, D2 < C2, D3 > C3
B. D1 = C1, D2 > C2, D3 > C3
C. D1 = C1, D2 > C2, D3 < C3
D. D1 = C1, D2 < C2, D3 < C3
E. D1 = C1, D2 = C2, D3 = C3
F. 无法确定





