本人生物信息菜鸟一枚,第一次自己提取TCGA编码蛋白和lncRNA表达谱。
数据准备及介绍
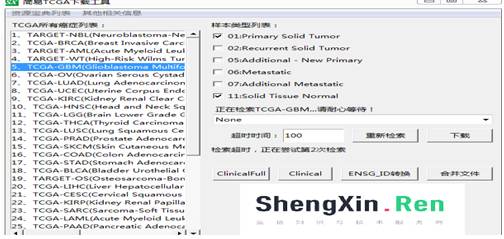
利用简易
TCGA
下载工具,下载胶质瘤数据(表达谱数据)
双击所要选择的癌症(默认选择原发癌和癌旁正常组织)
单击重新检索按钮下载资源列表,并根据下载资源列表选择下载数据类型
点击下载,选择路径,开始下载任务
通过合并文件按钮将单个文件合并生成矩阵
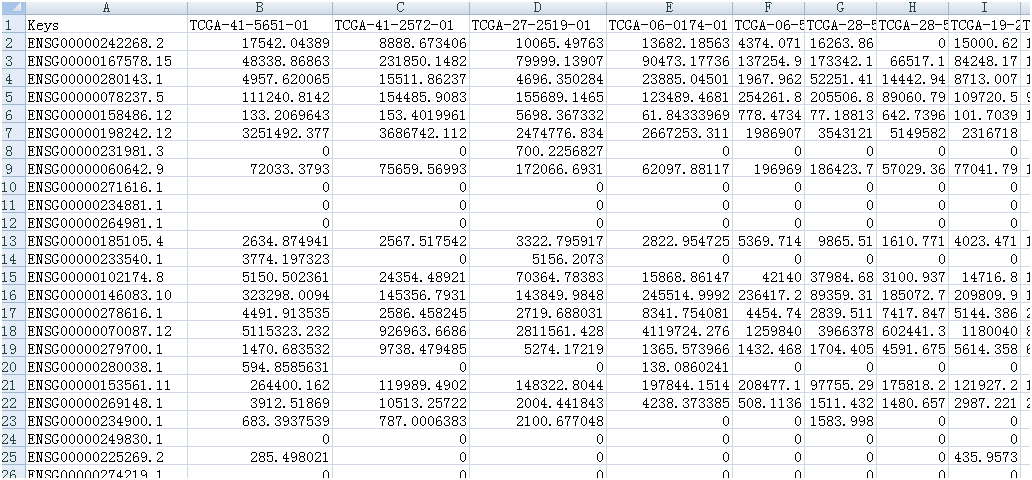
数据每一列代表一个ENSG_ID,每一列代表一个样本
在
ensembol
数据库下载数据
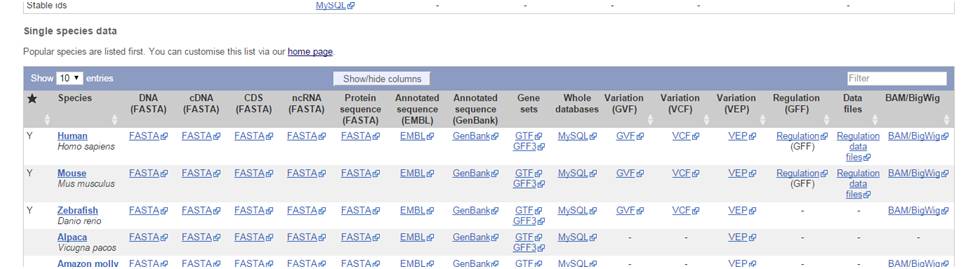
选择
人体蛋白质序列
,数据大体内容如下
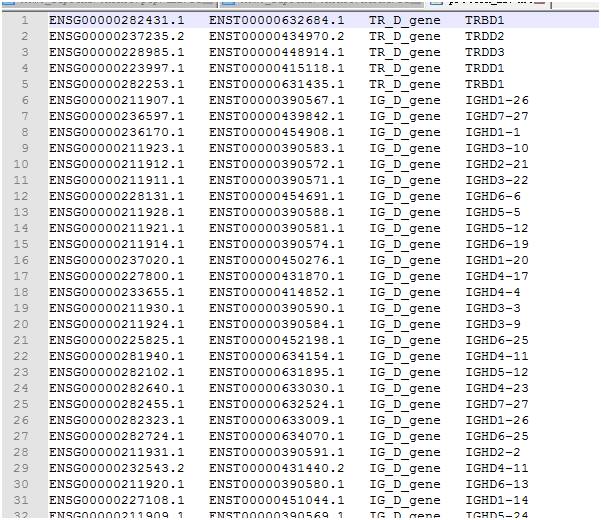
> ENSP00000487941.1 pep chromosome:GRCh38:7:142786213:142786224:1基因:ENSG00000282431.1转录本:ENST00000632684.1 gene_biotype:TR_D_gene transcript_biotype:TR_D_gene gene_symbol:TRBD1描述:T细胞受体β多样性1 [来源:HGNC符号; ACC:HGNC:12158]
GTGG
数据包含
ENSP_ID
,染色体位置,
ENSG_ID,ENST_ID,gene_symbol,gene_biotype,
空格分隔
从中提取
ENSG_ID,ENST_ID,gene_symbol,gene_biotype
制成表格,用于以后比提取。
数据处理与结果
获取蛋白质基因列表
进口
重
def
findlabel(line,opt,beg):
STR1 =行[line.find(优化):LEN(线)]
如果
str1.find(
''
)> -
1
:
str1 = str1 [beg:str1.find(
''
)]
否则
:
STR1 = STR1 [求:LEN(STR1)]
return
str1.strip()
def
searchprotein():
file1 =
'D:/Homo_sapiens.GRCh38.pep.all.fa'
f = open(file1,
'r'
)
线= f.readlines()
f.close()
list1的= []
用于
线
在
线路:
line = line.rstrip(
'\ n'
).strip()
如果
line.find(
'>'
)==
0
:
enst = findlabel(行,
'ENST'
,
0
)
ensg = findlabel(线,
'基因:'
,
5
)
type1 = findlabel(line,
'gene_biotype:'
,
13
)
gene_symbol = findlabel(line,
'gene_symbol:'
,
12)
list1.append((ensg,ENST,TYPE1,gene_symbol))
fw = open(
'D:/protein_ID.txt'
,
'w'
)
#
写文件
为
升
在
列表1:
fw.write(
'\
t'.join(
l)+
'\ n'
)
fw.close()
如果
__name__ ==
'__main__'
:
searchprotein()
形成文件
获取蛋白质表达谱:
def
getprotein():
file1 =
'D:/protein_ID.txt'
f = open(file1,
'r'
)
#
读取文件
线= f.readlines()
蛋白1 = []
用于
线
在
线路:
行= line.rstrip()。带()
pro = line.split(
'\ t'
)[
0
]
如果
亲们
没有在
蛋白1:
在最末尾添加
lnc中的
protein1.append(pro)
#
返回
蛋白质1
def
getproteinExpre():
蛋白1 = getprotein()
file1 =
'D:/Merge_matrix.txt'
f = open(file1,
'r'
)
线= f.readlines()
f.close()
fw = open(
'D:/proteinexp.txt'
,
'w'
)
用于
线
在
线路:








