AI科技评论了解到,近期清华信息科学与技术联合实验室,智能技术与系统国家重点实验室,生物启发计算研究中心和清华大学计算机科学技术学院联合发表的论文《使用对抗性例子提高深度神经网络性能》,探索了深度神经网络的内部架构,并提出了一种方法使人类可以监督网络的生成和网络发生错误的位置。
作者包括 Dong Yingpeng, Hang Su,Jun Zhu和Fan Bao。
论文链接:https://arxiv.org/pdf/1708.05493.pdf,AI科技评论编译。
深度神经网络(DNNs)在很多领域中都有前所未有的表现,包括语音识别,图像分类,物体检测等,但是DNNs的内部结构和学习产生的参数对学者来说一直都是黑匣子,刚开始的几个网络还能看的懂,然而越深度越不可解释。在很多情况下,由于人类对其认知的局限性,包括DNNs如何进行判断和如何行动,深度神经网络的使用范围则受到限制,特别是在一些安全性要求非常高的使用场合,比如:医院领域和自动驾驶等。研究人员需要理解训练产生的网络在判断时的理论基础,从而进一步的对网络进行理解、验证、修改和信任一个学习模型,并修正其已产生的和潜在的问题。因此,开发一种算法,来对产生的神经网络进行深入的剖析则变得非常重要了。在这个方向,很多的研究已经在进行了。学者们通过各种方法对机器产生的深度神经网络进行窥探,包括语义的,图像的。比如,学者们发现,在最大化或多梯度为基础的算法中,卷积层中的一个神经元可以看做是物体/局部的鉴别器。然而,这些尝试大多建立在一个特定的数据库之上(比如:ImageNET,Place),并且大部分的工作量都用作神经网络的基本理论解释,很少有人会将注意力放在DNNs产生错误的原因上。
提高神经网络性能的方法有很多,这篇论文重点分析面对不规则的例子(如:对抗性的例子)时DNNs的行为并通过跟踪输出的特征解释了神经网络的预测原理。特别的是,通过使用对抗性的例子,作者对比之前的研究结论,发现使用这种方法可以获得更好的神经网络的解释性能。通过使用“恶意”的对抗图片,DNNs可以生成如设计的“错误”的预测结果。将这种刻意“误导”的结果和真实的图片结果进行对比,从不同的结果上可以探寻DNNs的工作原理,既可以分析出DNNs如何进行正确的判断,又可以知道DNNs产生错误的原因,最终在一定程度上了解DNNs的机制。采用对抗性的图像而不是使用真实图像进行“错误”的预测的原因是使用真实图像产生的误差是可以容忍的,例如:Tabby Cat和Tiger Cat的错误分类结果跟对Tabby Cat和School Bus的错误分类结果相比,前者在视觉上和语义上都更能让人容忍。因此,使用完全“不同”的对抗性图片,可以更好更直观的区分和理解DNNs的错误判断来源。
AI科技评论整理后,了解到这篇论文有如下几个重点问题:
对抗性的数据库
为了更好的研究DNNs,作者建了一套对抗性的数据集。使用ILSVRC 2012 验证数据库对10张图片分别进行不同的标注,最终形成了一个500K的对抗性的验证数据库。使用集成优化攻击算法生成更多的通用对抗图片,这些图片具有很强的移植性,可以在其他模型中使用,如图1(a)。
虚拟对象/部分的探测器和不一致的视觉表现
作者对多个基本架构进行了,包括AlexNet、VGG、ResNet,并使用了真实的图片和生成的对抗性图片。人工监控了在输入不同的图片时DNNs中神经元的反应。同时对大量的视觉概念进行比对和评估。结果是很有趣的:(1)真实图像中具有高语义的神经元的表现在输入对抗性图像时表现不同;通过这个结果得出结论:DNNs中的神经元并没有真正的去检测语义对象,只把语义对象当做是复发性判别小图块进行响应。这一点与以前的研究恰恰相反。(2)深度视觉上的表现不是视觉概念的鲁棒性分布式编码,因为尽管视觉上看起来很相近,对抗性的图片与真实的图片在很大程度上不一致。如图1(a)。
使用对抗性图片可以提高DNNs的性能
对抗性的训练在之前的研究中已经被证实可对提高深度神经网络的鲁棒性带来显著的效果。在这篇论文中,作者通过引入对抗性的图片提高了DNNs的性能。除去对抗噪声,从结果上可以看出对抗图片的结果与真实图片的结果很相似。这个过程鼓励神经元学习抵抗对抗性扰动的干扰,因此,当优选对象/部件出现时,神经元总是会被激活,而当它们消失时,神经元则无效,见图1(b)。通过这个过程,人类学者可以对该神经元进行追踪,从而推测模型的理论预测原理。同时,这一过程中,人类学者还可以知道模型产生错误的时间和原因,如图1(c)。

方法
作者通过对ImageNet数据库中的图片进行实验,实验首先需要建立一组对抗性图片,然后将图片运用到生成的模型中,进而观模型的输出变化进行比对。DNNs对对抗性扰动的抵抗力非常脆弱,因此基于这个特性,有些方法已经被设计出来用作这个方面的研究,包括: L-BFGS,Fast Gradient Sign,Deep-Fool等。但是这些方法通常都是为某一个特性的模型设计的。本文的作者引入了一种新的方法,集成优化攻击算法,这种方法具有更强的通用性。如下:
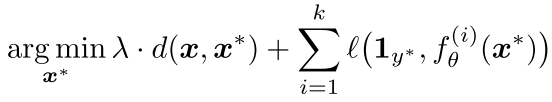
对AlexNet,VGG-16和RESNET-18模型进行攻击,通过解决上方公式中的优化问题,采用Adam优化器,5步长,并进行10-20次的迭代。由此,得到10张图片分别进行不同的标注,最终形成了一个500K的对抗性的验证数据库。使用集成优化攻击算法生成更多的通用对抗图片,这些图片具有很强的移植性,可以在其他模型中使用。
如图2,作者展现了部分图片结果。在第一行中,真实的图片中神经元拥有明确的语义解释或者人类可以理解的视觉概念,第二行对抗性图片表现出的语义解释则不能让人理解。一般情况系,神经元对对抗性图片中的不同部分更为敏感。在分析神经元的表现之后,在真实图片中具有高语义的神经元在处理对抗性图片时(红色框)被充分的激活了。然而,视觉表现上则能看出真实图片和对抗性图片的明显不同。另一方面,对抗图片中相似的部分,则表现出不活跃性,意味着在对抗性图片中,神经元无法检测出对应的物体/部分。如neuron 147 检测出了真实图片中的Bird head(鸟头),但是使用对抗攻击的算法后,在对抗性图片中,则框出很多其他的物体,这些物体(红色框)都是被错误的分类为Bird。另外,在对抗性图片中,网络也无法正确的识别出真实的Bird(鸟),这就意味着DNNs并没有对语义的物体/部分进行识别,只是将这些部分当做复发性判别小图块进行响应。

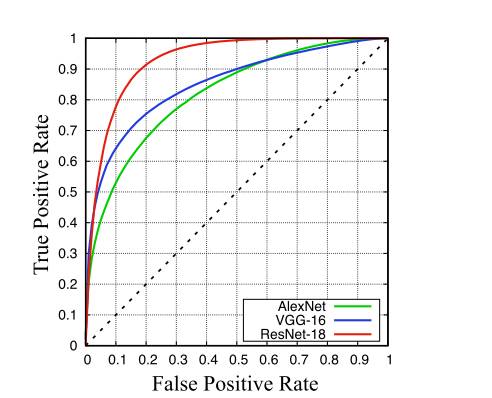
通过量化的理论分析,可以得知,在对抗性图片的结果与真实图片的结果无法对应。这意味着,DNNs的表现受对抗性扰动的影响严重,并且不是视觉概念的鲁棒性分布式编码方式。这样的话,DNNs的表现会造成在进行物体检测、视觉问答、视频处理时的不准确的判断。那么什么时候DNNs会犯错呢?
在上图实验中发生图片判断不一致的地方则提供了区分网络判断错误时间的机会。使用有条件的高斯分布模型(Gaussian distribution):p(φ(x) | y = i) =N (µ i , Σ i ),通过ILSVRC 2012训练数据库对DNNs发生错误的时间进行推测,如下图:
通过使用对抗性训练,作者实现了对DNNs性能的提高。对抗训练具有训练可读的DNNs的可能性,因为它使模型在输入空间上学习到更多的Robost概念,产生的对抗图像的表现类似于通过抑制扰动的原始图像。要做到这一点,需要引入一个一致的(做匹配用)的误差。使用这个误差可以使得当神经元从表现中的对抗性噪声恢复,优选的物体/部件出现时,神经元一直保持处在激活的状态。通过最小化一个对抗性的物体来进行DNNs的训练:
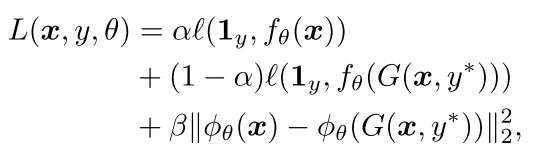
然后使用Fast Gradient Sign(FGS)方法生成对抗性图片:
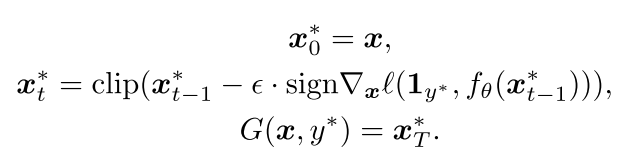
通过这些步骤,最终可以发现DNNs的可解释性得到了显著的提高,同时又保持了原有的性能(1%~4%的精度下降)。结果见图7。

通过使用对抗训练,神经元可以检测图片中的视觉概念,而不是仅仅是对小图块进行反应了。这种方式的优势在这提供了一种深度神经网络如何进行预测的方式。根据这种流程,人类研究者可以一步步的探索DNNs的工作原理,并梳理出一套在决策过程中起决定性作用的神经元。
总结
在这篇论文中,作者运用集成优化算法(ensemble-optimization algorithm)并使用对抗图片重新审视生成的深度神经网络。通过实验发现:(1)深度神经网络中的神经元并没有真正的去检测语义对象,只把语义对象当做是复发性判别补丁进行响应;(2)深度视觉上的表现不是视觉概念的鲁棒性分布式编码,因为尽管视觉上看起来很相近,对抗性的图片与真实的图片在很大程度上不一致,;这两点都与以往的发现有所不同。为了更好了让研发人员看懂DNNs的构成,作者提出了一种对抗训练方法,引入固定的误差,从而赋予神经元人类解释的概念。通过这种方法,人们可以对最终产生的结果进行回溯,从而得知深度神经网络生成的过程,获取发生错误的时间和原因。
————— 给爱学习的你的福利 —————
CCF-ADL81:从脑机接口到脑机融合
顶级学术阵容,50+学术大牛
入门类脑计算知识,了解类脑智能前沿资讯
课程链接:http://www.mooc.ai/course/114
或点击文末阅读原文

————————————————————











