点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达 作者:Purvanshi Mehta,编译ronghuaiyang
作者:Purvanshi Mehta,编译ronghuaiyang
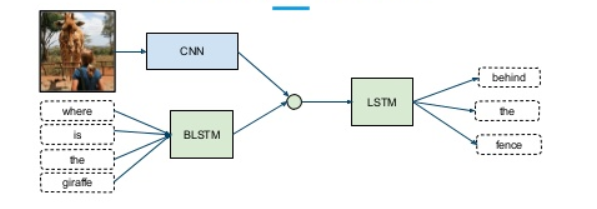
多模态数据
我们对世界的体验是多模态的 —— 我们看到物体,听到声音,感觉到质地,闻到气味,尝到味道。模态是指某件事发生或经历的方式,当一个研究问题包含多个模态时,它就具有多模态的特征。为了让人工智能在理解我们周围的世界方面取得进展,它需要能够同时解释这些多模态的信号。
例如,图像通常与标签和文本解释相关联,文本包含图像,以更清楚地表达文章的中心思想。不同的模态具有非常不同的统计特性。
多模态深度学习
虽然结合不同的模态或信息类型来提高效果从直观上看是一项很有吸引力的任务,但在实践中,如何结合不同的噪声水平和模态之间的冲突是一个挑战。此外,模型对预测结果有不同的定量影响。在实践中最常见的方法是将不同输入的高级嵌入连接起来,然后应用softmax。
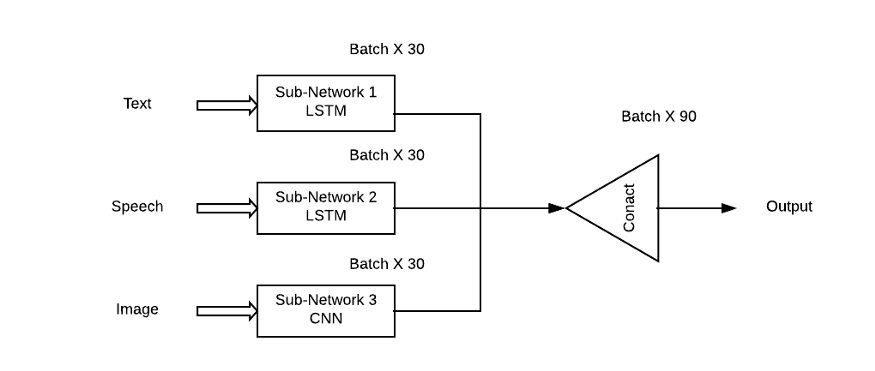
多模态深度学习的例子,其中使用不同类型的神经网络提取特征
这种方法的问题是,它将给予所有子网络/模式同等的重要性,这在现实情况中是非常不可能的。
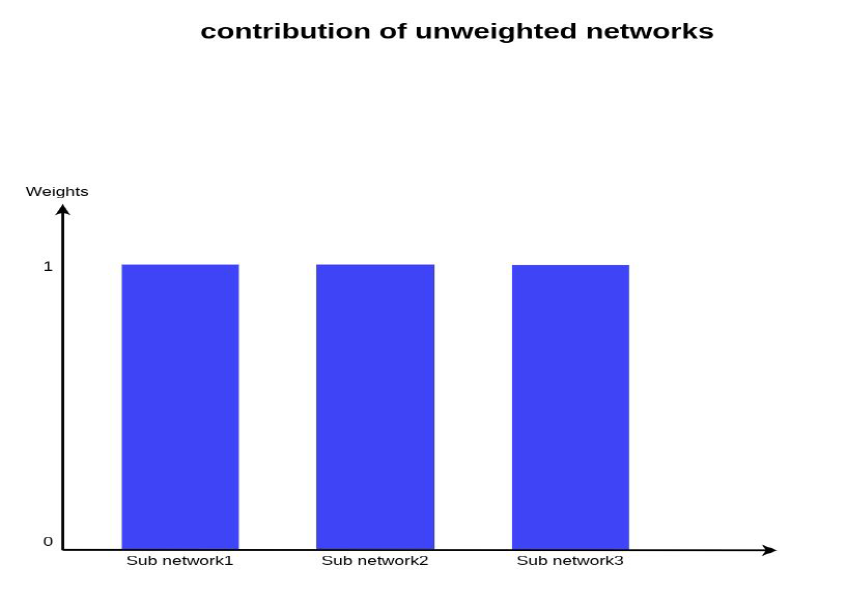
所有的模态对预测都有相同的贡献
对网络进行加权组合
我们采用子网络的加权组合,以便每个输入模态可以对输出预测有一个学习贡献(Theta)。
我们的优化问题变成-