选自 Intel Blog
作者:Andres Rodriguez、Niveditha Sundaram
Caffe2 作为 Caffe 重构出的深度学习框架,一经发布便引起了业内极大的关注。机器之心也对 Caffe2 进行了跟踪报道。昨日,
英伟达的一篇技术博客
让我们了解 Caffe2 结合 GPU 带来的性能提升。这篇文章对 Caffe2 在 CPU 的支持下带来的性能改进进行了介绍,希望能为大家应用该框架提供帮助。
每一天,在世界的各个角落都在产生越来越多的信息——文本、图片、视频等等。为了能让人们更好地理解这些信息,近几年,人工智能和深度学习已经参与进来,改进了部分一流的语音识别、图片/视频识别以及搜索推荐的应用。
大多数深度学习工作负载同时包含训练和推理。其中,训练通常需要几个小时或几天才能完成,而推理通常需要几毫秒或几秒,并且通常是更大流程的一个步骤。虽然推理的计算强度远低于训练,但推理经常涉及更大的数据集。因此,与推理所需的计算资源总量相比,训练所需的计算资源总量相形见绌。值得指出的是,绝大多数推理工作负载都运行在英特尔至强(Xeon)处理器上。
为了针对各种训练和推理应用进行优化,去年,英特尔在几个深度学习框架上都迅速增加了 CPU 的支持。这些优化最核心的一项是英特尔数学核心函数库(英特尔 MKL),它使用英特尔高级矢量扩展 CPU 指令集(例如英特尔 AVX-512),更好地支持深度学习应用。
说到 Caffe2,它实际上是 Facebook 开发的一个开源深度学习框架,其在开发时就充分考虑到了表达、速度和模块化。Caffe2 旨在帮助研究人员训练大型机器学习模型,并在移动设备上提供人工智能。如今,开发者可以用许多相同的工具,让它们运行大规模分布式训练场景,并为移动设备开发机器学习应用。
英特尔和 Facebook 正在进行合作,把英特尔 MKL 函数集成与 Caffe2 结合,以在 CPU 上实现最优的推理性能。表 1 显示了在 AlexNet 上采用了英特尔 MKL 函数库和 Eigen BLAS 函数库进行压缩的推理性能。在这个表中,OMP_NUM_THREADS 表示这些工作负载中使用的物理核心数量(详情见表格说明)。这些结果显示,Caffe2 在 CPU 上进行了高度优化,并提供有竞争力的性能。对于小型批处理推理工作负载,建议在每个 CPU 核心上运行一个工作负载,并并行运行多个工作负载,每个核心一个工作负载。
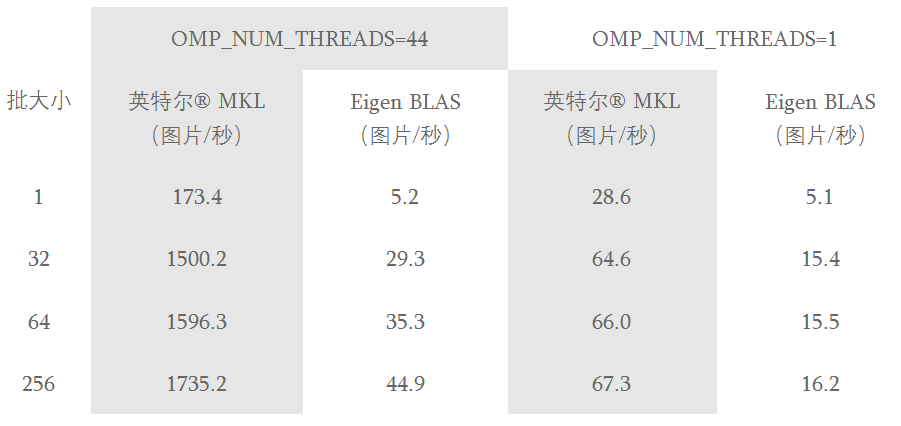
表 1:Caffe2 上采用了 AlexNet 拓扑以及英特尔 MKL 和 Eigen BLAS 的性能结果。试验采用了英特尔至强处理器 E5-2699 v4(代号 Broadwell,2.20GHz,双插槽)、每个插槽 22 个物理核心(两个插槽上总计 44 个物理核心),122GB RAM DDR4,2133 MHz,禁用超线程,Linux 3.10.0-514.2.2.el7.x86_64 CentOS 7.3.1611,英特尔 MKL 20170209 版,Eigen BLAS 3.3.2 版,基于截至 2017 年 4 月 18 日的 Caffe2。







