原文来源
:arXiv
作者:Mohammad HarisBaig,VladlenKoltuni,Lorenzo Torresani
「雷克世界」编译:嗯~阿童木呀、多啦A亮
 最近,我们研究了有损图像压缩的深度架构设计,进而在多级渐进编码器(multi-stage progressive encoders)上下文中提出了两种架构方法,并凭经验证明了它们在压缩性能上的重要性。具体来说,研究结果表明:(a)对多级渐进体系架构中的残差预测原始图像数据便于学习并导致在近似原始内容时性能得以改进;(b)在执行压缩之前学习修复(从相邻图像像素)能够减少必须存储的信息,从而实现高质量的近似。如果将这些设计选择合并到一个基准渐进编码器中,那么与原始残差编码器相比,文件大小平均减少了60%以上,而质量不相上下。
最近,我们研究了有损图像压缩的深度架构设计,进而在多级渐进编码器(multi-stage progressive encoders)上下文中提出了两种架构方法,并凭经验证明了它们在压缩性能上的重要性。具体来说,研究结果表明:(a)对多级渐进体系架构中的残差预测原始图像数据便于学习并导致在近似原始内容时性能得以改进;(b)在执行压缩之前学习修复(从相邻图像像素)能够减少必须存储的信息,从而实现高质量的近似。如果将这些设计选择合并到一个基准渐进编码器中,那么与原始残差编码器相比,文件大小平均减少了60%以上,而质量不相上下。

可以说,我们每天在网络上创建和共享的大部分信息就是可视化数据,从而形成了对存储和网络带宽的大量需求。根据以往的习惯,只要在内容中没有明显的损失,我们就应该尽可能地压缩图像数据。近年来,随着深度学习的快速发展和广泛使用,使得设计用于学习图像数据的紧凑表示(compact representations)的深度模型成为可能。基于深度学习的方法,比如Rippel和Bourdev的研究,在性能表现上明显优于传统的有损图像压缩方法。在本文中,我们展示了该如何提高那些用于训练有损图像压缩的深度模型的性能。
我们着重关注产生渐进代码的模型设计。渐进代码是一组表示序列,可以通过添加遗漏的细节来进行传输,以改进现有估计(来自之前发送的编码)的质量。这就与非渐进式代码形成了对比,因为在非渐进代码中,必须在可以查看图像之前传输用于特定质量近似的整个数据。渐进代码通过减少图像丰富的页面的加载时间来改进用户的浏览体验。我们在本文中的主要研究成果包括以下两个方面:
1.虽然传统的渐进式编码器经过优化,可以压缩其结构每个阶段的残差(residual-in, residual-out),但我们提出了一个模型,该模型经过训练,以在每个阶段预测前一个阶段残差(residual-in, residual-out)的原始图像数据。研究结果证明,这将更容易进行优化,从而产生更好的图像压缩。相较于传统的残差编码器,由此产生的架构减少了以相似质量再现图像所必须存储的信息量的18%。
2.现有的深度架构没有利用相邻补丁所展示的空间相干性的高度(the high degree of spatial coherence)。我们展示了如何设计和训练一个可以通过学习现有内容中的修复来利用相邻区域之间的依赖关系的模型。我们引入了多尺度卷积,在多个尺度上对内容进行抽样以辅助修复。我们对提出的修复和压缩模型进行了训练,结果显示,修复将必须存储的信息量减少了42%。
修复的影响
我们开始在局部上下文中分析修复网络和其他方法的性能表现。我们将修复网络的性能与传统方法以及基于学习的基线进行比较。表1显示了在每种方法在修复Kodak数据集中所有不重叠的补丁过程中所获得的平均结构相似性(SSIM)。

表1:Kodak数据集中部分上下文修补的平均SSIM。vanilla模型是一个没有多尺度卷积的前馈卷积神经网络。
vanilla网络对应于不使用多尺度卷积(所有滤波器的膨胀因子为1)的32层(是修复网络的4倍)模型,具有相同数量的参数,并且全分辨率(作为我们的修复网络)操作。这表明,修复网络在vanilla模型上的性能改进是使用多尺度卷积的结果。修复网络改进了传统的方法,因为我们的模型学习了传播内容的最佳策略,而不是使用手动传播的内容传播原理。vanilla网络的低性能表明,自我学习并不优于传统方法,多尺度卷积在取得更好的性能方面起着关键作用。
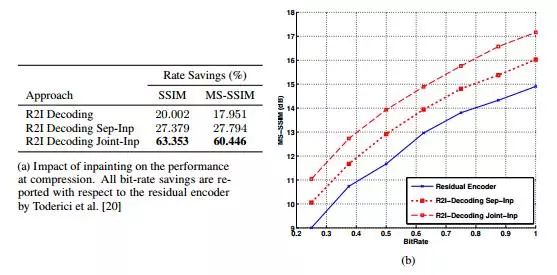
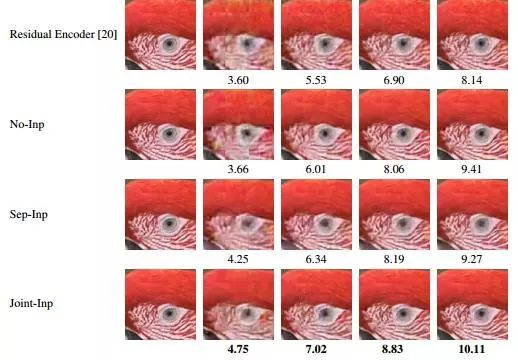
图1:(a)通过不同形式修复的平均节省率。(b)我们提出的每种方法在不同比特率下的图像质量。
鉴于修复提供了该部分内容的初步估计,但它决不会产生一个完美的重建。这就引出了这个初始估计是否比没有估计更好的问题。图1(a)中的表格显示了带压缩和不带修复的压缩任务的性能。这些结果表明,当修复网络与R2I模型联合训练时,文件大小的减少是最多的。我们注意到(从图1(b)),修复大大提高了在较低和较高比特率下获得的结果的质量。
这里引入了修复网络与压缩网络分开训练的基线,以强调联合训练的作用。传统的编码器使用简单的基于非学习的修复方法,其预先确定的表示方法不能对修补残差进行紧凑编码。分别学习单独的修复会提高性能,因为修复后的估计比没有任何估计要好。但考虑到压缩模型没有经过训练来优化压缩残差,为了达到高质量水平,比特率的降低是很微乎其微的。我们表明,通过联合训练,我们不仅可以训练一个更好的修复模型,而且可以确保修复残差可以紧凑地表示。
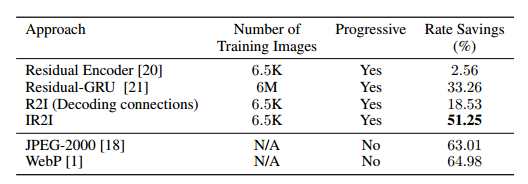
表2:与JPEG相比,平均节省率。柯达数据集计算的节省量是在0-1 bpp范围内测量MS-SSIM的率-失真曲线。
结论和未来的工作
我们研究了一类“图像残差(Residual to Image)”模型,并表明在这个类中,具有解码连接的体系结构与使用其他形式的连接的设计相比,更能近似图像数据。我们观察到,我们的R2I解码连接模型在低比特率下表现较差,我们展示了如何通过利用修复相邻块之间的空间相干性来提高在低比特率下近似图像内容的性能。我们使用多尺度卷积设计了一个新的部分上下文(partial-context)修复模型,并且表明补充修复的最佳方法是利用我们的R2I解码模型联合训练修复网络。
这项工作的一个有趣的扩展是将熵编码纳入我们的渐进压缩框架,以训练产生低熵且可以更紧凑地表示的二进制代码的模型。另一个可能的方向是将我们提出的框架扩展到视频数据,在这里我们发现改进压缩的方法,收获可能会更大。
论文下载:https://arxiv.org/pdf/1709.08855.pdf



回复「转载」获得授权,微信搜索「ROBO_AI」关注公众号
中国人工智能产业创新联盟于2017年6月21日成立,超200家成员共推AI发展,相关动态:
中新网:
中国人工智能产业创新联盟成立





