来自:DT财经 (ID:DTcaijing) 已获得授权
文章来源: Triphappy
编译:宋辽
端午假期到了,你要出远门么?你是怎么找住宿的?分享的这个案例,是关于如何用数据在陌生城市找到好住所。
▍
世界那么大,找房好困难
我们总希望去陌生的城市看一看,但又总是在决定落脚何处时犹豫不决。
首先,提供住宿预订的网站太多,每一个都会提供一份自己的房屋清单。
其次,你必须选择想要居住的街区,再反复确认这个选址是否为最为便利。
最后,你还需要基于价格和用户评价去挑选一个具体宾馆、旅店或床位。
这整个挑选的过程实在令人生畏。
很多网站虽然提供了交互地图方便用户搜寻住处,但当你打开,会看到可选择街区总是多的令人眼花缭乱,而能得到的引导和帮助少得可怜。
比如下图,看过之后你完全搞不明白在发生什么,依然难以决策。
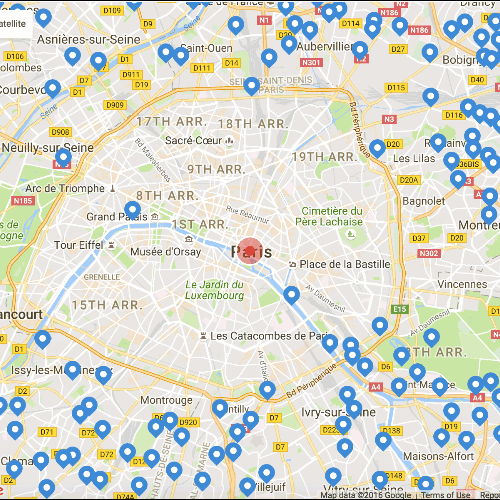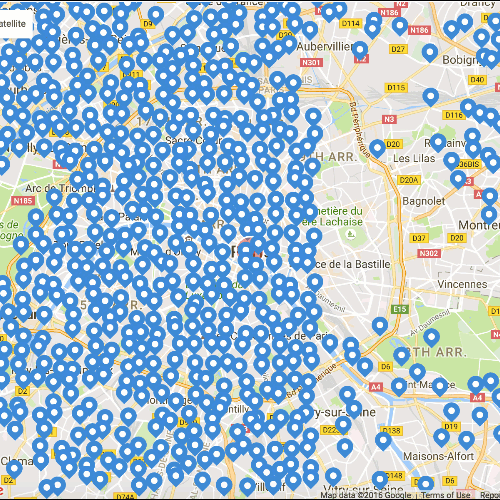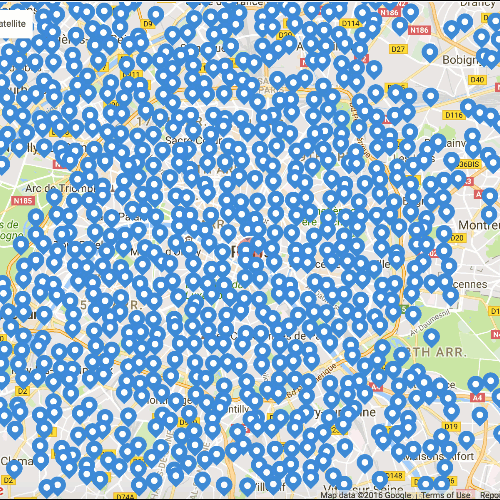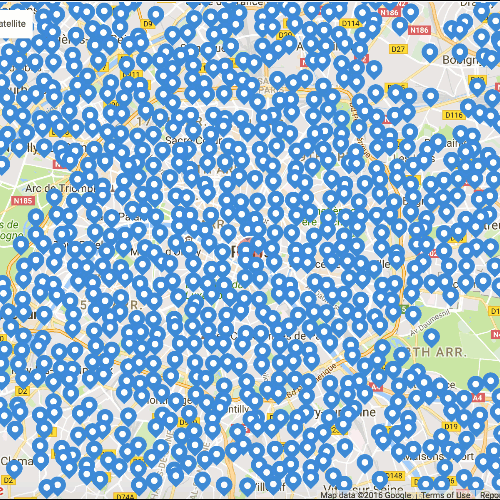
(图片说明:某个在线旅馆预订网站的实时地图,每5秒刷新一次的效果)
美国一家名为Triphappy的在线旅游咨询公司,尝试创造一种能让住宿决策变得简单的工具,帮助旅客在世界上任一个城市,找到最方便、最棒的街区中最好的房子。
它们选择了三个用户最常使用的酒店预订网站:HostelWorld、Booking和Airbnb,并对上面3700万份评价进行分析:首先,通过聚类分析的方法,将获得高分推荐的房源按照不同街区进行整合;然后将最受欢迎的街区展现给用户;同时还将这些地区附近的热门活动展示出来。
当用户锁定自己喜欢的街区后,可以在网站上对比这三个酒店预订网站的房价,然后就可以下手预订了。
▍
如何找出地理位置最好的街区
Triphappy是如何构建这个工具的呢?
首先,他们从数据合作伙伴那里获得了覆盖13000个城市和超过1百万个房源的旅馆、酒店、家庭寄宿的相关数据,以及超过3700万份的房屋评分。
下图是一份巴黎的所有可选择房屋的地图。
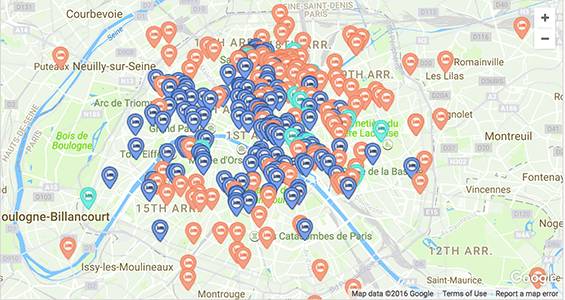
如果就这样展示出来,房屋数量明显太多了,会和其他网站一样让人抓狂。
所以,Triphappy团队先对数据进行一轮过滤和预处理,筛选出对模型有价值的数据。
不同平台上对房源的评分数据有不同的评价标准:首先各个房源都会有一个综合得分,然后是许多各不相同的子评分项目,诸如清洁程度、安全程度和性价比等。
Triphappy决定使用“地理位置”这一子项的评分来大致判断某个街区的质量。
如果一个街区密集分布着大量“地理位置”评分很高的房源,那么即使当中有一间屋子的综合得分很低,只要周边房屋的得分普遍很高,这一带依然会被归为是“很好”的街区。
在分析了巴黎约一万条评论后,Triphappy发现,大家对“地理位置”一项打分时,出现最多的是9分。Triphappy选择了高于9分的房源,将它们标注在地图上。
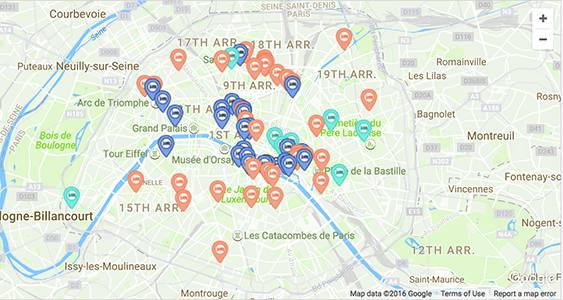
这样看来似乎不那么杂乱了。这些房源主要集中在香榭丽舍大街,蒙马特尔和圣杰维斯附近的街区。
▍
用聚类分析简化结果
接下来,Triphappy对这些街区进行聚类分析。
聚类分析(Cluster Analysis),是指根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法,分析对象是大量样品,在没有先经知识的前提下,按各自的特性来进行合理分类。
聚类算法类型众多,也有着数不清的相关著名文献。Triphappy选择了改进的启发式递归DBSCAN算法(Density-Based Spatial Clustering of Applications with Noise)来对涵盖了各个城市数据的模型参数化。
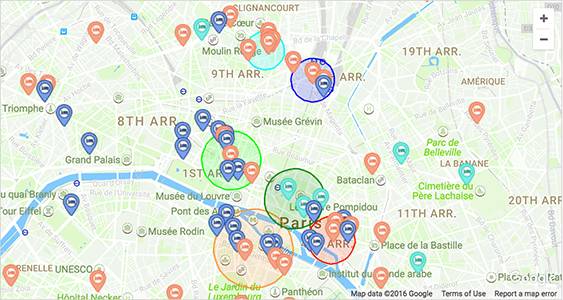
通过输入地理位置得分较高的房源的坐标,算法根据它们之间的位置接近度将其聚成不同的集群。下图可以看到,这种启发式的参数化模型,在塞纳河、蒙马特,和巴黎北火车站附近给出了不错的结果。
解决了后端数据的问题,团队继续考虑前端展示方式。
他们先对初次搜索的结果进行限制,以免让地图显得过于杂乱,然后再在图上加一些兴趣活动地点(灰色记号)。
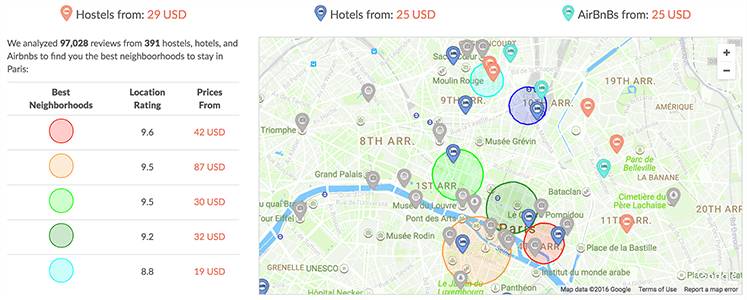
现在看起来好多了。
塞纳河周边的四个街区和蒙马特街区似乎都离一些很棒的活动地点很近。这样一来,人们可以根据自己的行程计划去挑选街区,再从街区中去寻找最完美的住所。
上海和北京最好的街区在哪?










