|
|
专栏名称: TechSugar
| 做你身边值得信赖的科技新媒体 |
目录
相关文章推荐

推荐文章

|
丁香医生 · 玻璃杯、不锈钢杯、陶瓷杯……水杯你真的用对了吗? 8 年前 |

|
包容万象 · 为什么被拐卖的女人基本都跑不掉?看完浑身发抖 7 年前 |

|
护肤奇扒说 · 女生夏日必备神器,你需要提升一下幸福感了~ 7 年前 |

|
金融圈 · 用脚投票的选择,中国人口正在进行一场大迁移 7 年前 |
|
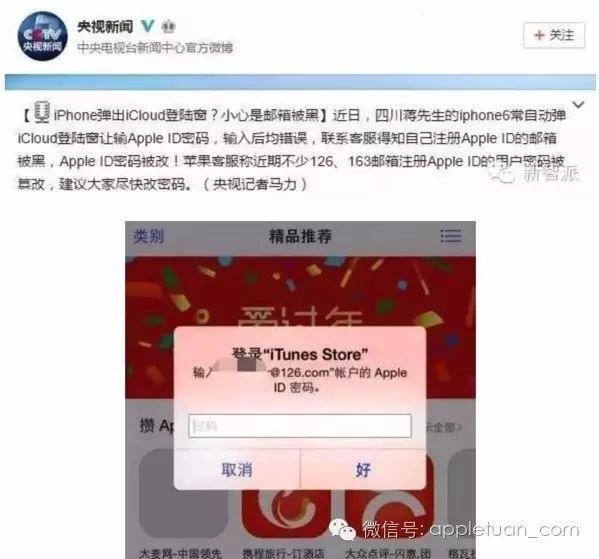
苹果团(AppleTuan) · 请大家注意保护自己的 Apple ID开启二次验证~ 7 年前 |