暑期Stata培训班招生啦!!!
接力线上的网课培训,我们在今夏又开始新一轮的线下培训啦!
8月4日至12日
,爬虫俱乐部期待与您的相遇!培训具体内容详见推文
《
暑期Stata编程技术定制培训班
》
。
有问题,不要怕!
点击推文底部“
阅读原文
”下载爬虫俱乐部用户问题登记表并按要求填写后发送至邮箱
[email protected]
,我们会及时为您解答哟~
喜大普奔~爬虫俱乐部的
github
主站正式上线了!我们的网站地址是:
https://stata-club.github.io
,粉丝们可以通过该网站访问过去的推文哟~
好消息:
爬虫俱乐部隆重推出数据定制及处理业务啦,您有任何网页数据获取及处理方面的难题,请发邮件至我们邮箱
[email protected]
,届时会有俱乐部资深高级会员为您排忧解难!
当夏夜的繁花悄然开放,夏日的蝉鸣响彻云霄;当天上的乌云聚成了骤雨,高考的硝烟逐渐散去;此刻,高考成绩如约而至。
从高考结束到出成绩的这段日子,每一位考生似乎都经历了一个不一样的人生——拒绝撕书庆祝、对答案估分、通宵打游戏,再到热搜中出现“我在大学等你”,再到大家不约而同地打开下面这个网页(
http://www.eol.cn/
):

是的,当成绩出来的那一刻,就意味着这段幸福时光戛然而止。每一个严以律己的考生,都会从那段醉美的时光中醒来,尽全力为自己找一个未来四年的归途,亦或是另一个满是硝烟的战场。
详细了解每一所大学的情况,是我们此刻的重中之重。
现在,让我们跟随stata君,先来探索一下国内两千多所高校的热度排行吧!
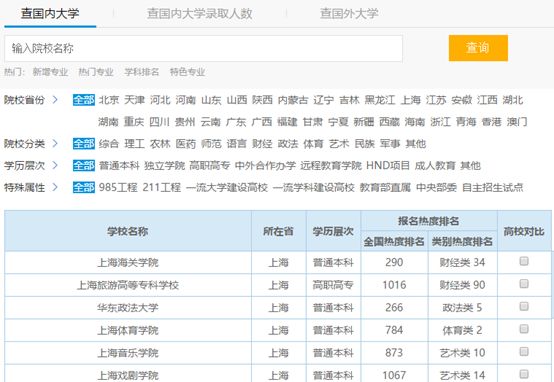
当我们打开上边这个页面时
(https://gkcx.eol.cn/soudaxue/queryschool.html?keyWord1=&schoolflag=&1=1&page=8)
,就会看到几所大学的全国热度排名和类别热度排名,以及它的学历层次和所在省份。但是,我们会发现所有的热度排名都是乱序的。我们能不能把所有大学的信息都导入到一个表中,方便后期查阅呢?当然可以,下面我们就来实现这个想法。
说起爬虫,我们会首先使用
copy
命令抓网页源代码,但是当我们找到网页的源代码之后,通过检索相关信息,发现源代码中并没有我们需要的目标数据。

出现这样的结果,是因为这时我们找到的并不是网页的真实链接,要想继续寻找网页的真实链接,接下来我们需要谷歌浏览器的帮助。
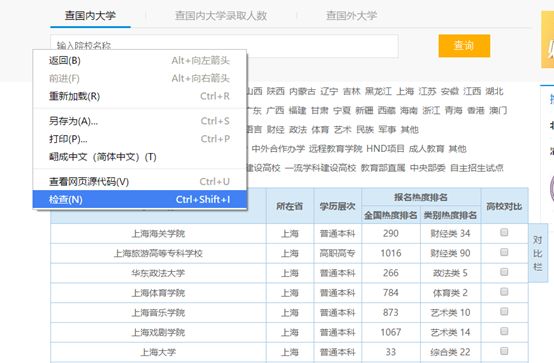
在谷歌浏览器中,我们点击鼠标右键,会出现一个“
检查
”选项,单击“
检查
”,得到如下界面。
点击
network
,再按
F5
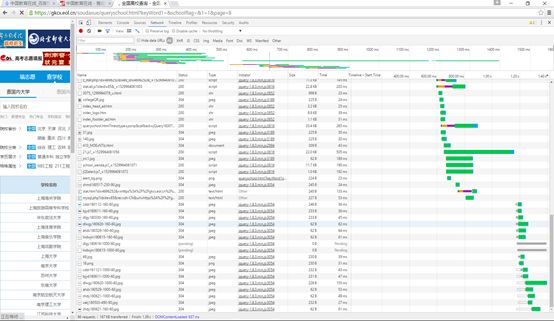
刷新,这样工具列表中就会出现许多与网页相关的链接,如下图所示:
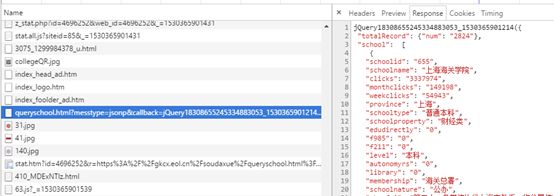
对于这个网页,我们在左侧找到我们需要的链接并单击,查看它的
Response
即返回信息,发现其返回信息和我们所分析的网页信息相同,如下图:
现在,我们就可以在
Headers
中找到网页的真实链接了(
RequestURL
)。如下图:

同时,我们可以发现,该网页的请求方式为
get
方式,网页的一些参数直接在网页的链接里边,找到网页的真实链接之后,我们当然又会想到我们的
copy
命令。所以我们继续使用
copy
抓网页源代码:
copy "https://data-gkcx.eol.cn/soudaxue/queryschool.html?messtype=jsonp&callback=jQuery1830992755553502749_1530151399470&province=&schooltype=&page=8&size=30&keyWord1=&schoolprop=&schoolflag=&schoolsort=&schoolid=&_=1530151399697" temp.txt, replace
我们发现stata报错了:

服务器拒绝了我们的访问!使用
copy
始终没有抓取到源代码,那么接下来,就轮到我们的爬虫神器——“
curl
”出场了!
要想得到这个网页的源代码,就需要我们使用curl模拟浏览器进行抓取。
curl的安装和使用案例在前面的推文中已经有所介绍(详见
《爬虫神器"curl"》
、
《一起来揪出网页真实链接!》
、
《爬虫神器curl继续带你抓网页》
),接下来我们来谈一谈curl在这次爬虫中的具体应用。
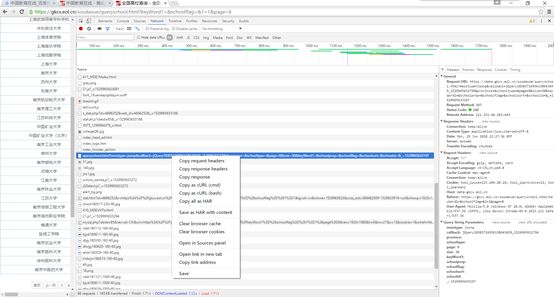
右击左侧我们需要的链接,单击
Copy as cURL
(
cmd
),然后复制到
do
文件或者
sublimetext
,就得到了下面一条命令:

将命令写在
stata
中,并且在
curl
的前面加上英文状态下的
“!”
,就可以拿到我们所需要的网页源代码了,程序如下:
clear
cap mkdir E:\中国教育在线\
cap mkdir E:\中国教育在线\全国热度\
cd E:\中国教育在线\全国热度\
!curl -o temp.txt ///"https://data-gkcx.eol.cn/soudaxue/queryschool.html?messtype=jsonp&callback=jQuery18303716956138643659_1529965632796&province=&schooltype=&page=8&size=30&keyWord1=&schoolprop=&schoolflag=&schoolsort=&schoolid=&_=1529965633197" ///
-H "Accept-Encoding: gzip, deflate, sdch" ///
-H "Accept-Language: zh-CN,zh;q=0.8" ///
-H "User-Agent: Mozilla/5.0 (Windows NT 10.0;WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112Safari/537.36" ///
-H "Accept: */*" ///
-H "Referer: https://gkcx.eol.cn/soudaxue/queryschool.html?keyWord1=&schoolflag=&1=1&page=8" ///
-H "Cookie: tool_ipuse=223.104.20.26;tool_ipprovince=21; tool_iparea=2" ///
-H "Connection: keep-alive" ///
-H "Cache-Control: max-age=0" ///
--compressed
shellout temp.txt
注意到curl之后有一个
-o
,
-o
的作用是将抓取到的网页源代码下载并保存到名为
temp.txt
的文件中,保存的路径为
stata
默认保存路径。网页源代码见下图:
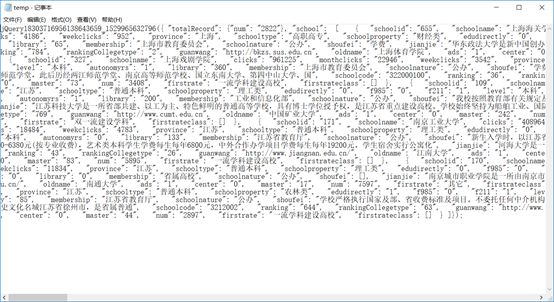
终于,我们拿到了网页的源代码。可以看到,我们拿到的网页源代码是
json
格式的,由于篇幅的原因,我们会在下一篇推文中对如何处理该
json
格式的源代码进行详细的说明,同时,我们也会在下一篇推文中生成我们最终的excel文件,敬请期待!
小伙伴们也可以积极思考如何处理该
json
格式的源代码,并留言进行交流!
注:此推文中的图片及封面(除操作部分的)均来源于网络!如有雷同,纯属巧合!
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
往期推文推荐:
1.爬虫俱乐部新版块--和我们一起学习Python
2.hello,MySQL--Stata连接MySQL数据库
3.hello,MySQL--odbcload读取MySQL数据
4.再爬俱乐部网站,推文目录大放送!
5.用Stata生成二维码—我的心思你来扫
6.
Hello,MySQL-odbc exec查询与更新










