
机器学习算法与自然语言处理出品
@公众号原创专栏作者 刘聪NLP
学校 | 中国药科大学 药学信息学硕士
知乎专栏 | 自然语言处理相关论文
最近一直在做自然语言推理和文本蕴含的相关工作,为了加深自己对论文的理解,在这里写下论文笔记。上一篇分享的文本蕴含论文bilateral multi-perspective matching (BiMPM)模型,这次分享的论文是Enhanced Sequential Inference Model(ESIM)。如果有错误的地方,请大家及时指正。
刘聪NLP:论文阅读笔记:文本蕴含之BiMPMzhuanlan.zhihu.com
一、背景介绍
文本蕴含或者自然语言推理任务,就是判断后一句话(假设句)能否从前一句话(前提句)中推断出来。ESIM论文首先证明了基于链式LSTM的顺序推理模型可以优于之前使用非常复杂的网络结构的模型,在此基础上,进一步表明了通过增加局部推理和推理组合,可以很好地改进顺序推理模型。在这篇论文中,不仅介绍了ESIM模型,还介绍了包含语法分析信息的树型LSTM网络。我主要介绍ESIM模型部分。
二、模型介绍
模型主要包括四层:输入编码层(Input Encoding Layer)、局部推理层(Local Inference Layer)、推理组合层(Inference Composition Layer)和预测层(Prediction Layer),如图1所示,其中左边部分为ESIM模型,右边部分为树型LSTM网络。
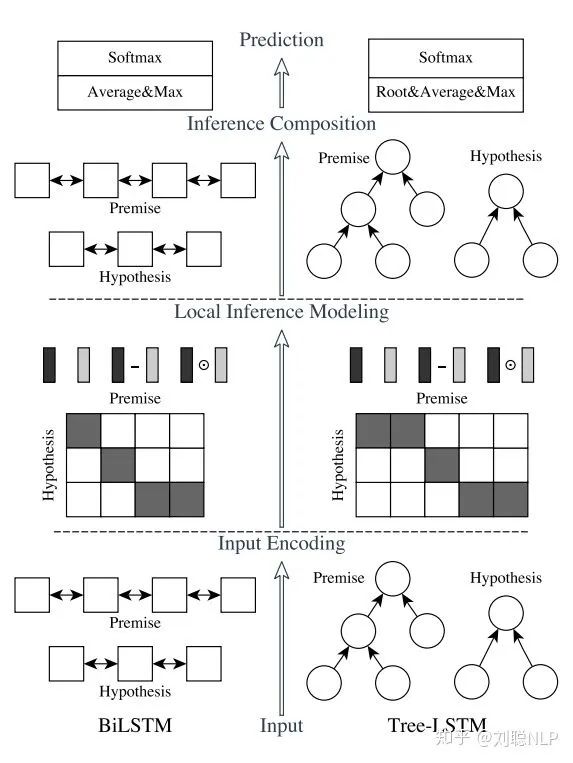 图1 模型框架图
图1 模型框架图下面将对各层进行介绍:
1、输入编码层(Input Encoding Layer)
在这一层中,本模型首先对前提句和假设句中的每个词映射成一个向量,然后用一个双向LSTM分别编码前提句和假设句的词向量。在这里,BiLSTM使句子中的学每个单词具有其上下文含义。
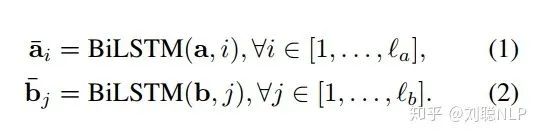
其中,  和
和  分别表示前提句和假设句,
分别表示前提句和假设句,  和
和  分别表示编码后的前提句和假设句,而这里的两个BiLSTM是权值共享的(权值共享的目的,见上一篇分享,这里不过多描述了)。
分别表示编码后的前提句和假设句,而这里的两个BiLSTM是权值共享的(权值共享的目的,见上一篇分享,这里不过多描述了)。
2、局部推理层(Local Inference Layer)
在这一层中,本模型首先使用点积的方式,求解前提句和假设句的相似度矩阵,即
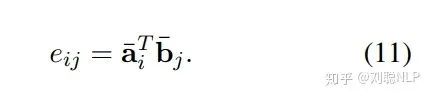
其中, 和 分别表示编码后的前提句和假设句;然后求解前提句和假设句的局部推理,利用相似度矩阵  ,结合 和 ,计算出两个句子之间的相互表示,即
,结合 和 ,计算出两个句子之间的相互表示,即
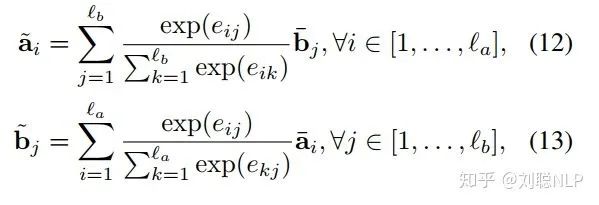
其中, 和 分别表示编码后的前提句和假设句,  和
和  分别是前提句和假设句的句长, 是相似度矩阵,
分别是前提句和假设句的句长, 是相似度矩阵,  是对进行加权求和的结果,也就是说
是对进行加权求和的结果,也就是说 表示中每个词与
表示中每个词与 的相关程度;最后,对局部推理进行增强,即
的相关程度;最后,对局部推理进行增强,即
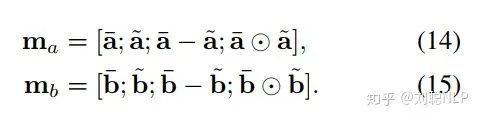
其中,  和
和  分别表示前提句和假设句增强后的局部信息表示。
分别表示前提句和假设句增强后的局部信息表示。
3、推理组合层(Inference Composition Layer)
在这一层中,本模型首先使用BiLSTM对局部信息 和 进行编码,以便得到其局部信息的上下文表示向量,得到  和
和  。模型作者认为如果对得到的上下文表示向量求和可能对序列长度敏感,鲁棒性较差,因此采用了计算上下文表示向量平均池化和最大池化的方法,并将所有池化后向量连接起来,形成最终的固定长度向量
。模型作者认为如果对得到的上下文表示向量求和可能对序列长度敏感,鲁棒性较差,因此采用了计算上下文表示向量平均池化和最大池化的方法,并将所有池化后向量连接起来,形成最终的固定长度向量  ,即
,即
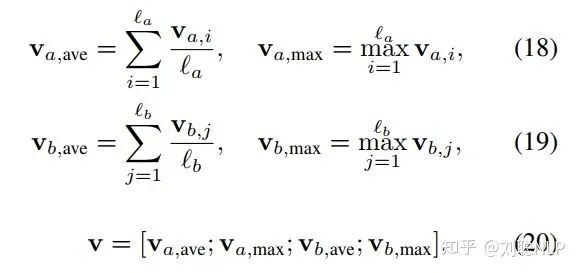
4、预测层(Prediction Layer)
在这一层中,本模型将上述得到的固定长度向量 ,连接两层全连接层,第一层采用tanh激活函数,第二层采用softmax激活函数,最后得到文本蕴含的结果。
三、模型参数
该论文中,word embedding为300维,所有的双向LSTM的隐层节点数为300,dropout rate为0.5,学习率为0.0004,采用adam优化器,第一动量设为0.9,第二动量设为0.999,batch size大小为32。在模型训练过程中,训练词向量。
四、总结
以上就是我对该篇论文的理解,如果有不对的地方,请大家见谅并多多指教。以后会继续做文本蕴含方面的分享,下一篇应该是孪生网络、DIIN或CAFE中的一篇。
ESIM原文链接arxiv.org
重磅!忆臻自然语言处理-学术微信交流群已成立
可以扫描下方二维码,小助手将会邀请您入群交流,
注意:请大家添加时修改备注为 [学校/公司 + 姓名 + 方向]
例如 —— 哈工大+张三+对话系统。
号主,微商请自觉绕道。谢谢!

推荐阅读:
全连接的图卷积网络(GCN)和self-attention这些机制的区别与联系
图卷积网络(GCN)新手村完全指南
论文赏析[ACL18]基于Self-Attentive的成分句法分析





