AI 科技评论按
:2017年是ImageNet挑战赛举办的最后一年,夏威夷当地时间7月26日,作为ImageNet创始人之一的李飞飞和他的学生邓嘉在CVPR 2017期间的一场workshop上做了主题演讲,他们对ImageNet 八年来所走的路做了深情回顾和总结。

ImageNetc创办至今共举办八届挑战赛,从最初的算法对物体进行识别的准确率只有71.8%上升到现在的97.3%,识别错误率已经远远低于人类的5.1%。
尽管ImageNet挑战赛已结束了它短暂的生命周期,但ImageNet数据集还会一直存在,截止目前已经有超过1300万张图片,并且未来还会增长,继续为计算机视觉领域做贡献。
谈及为什么提出建Imagenet数据集,李飞飞说“尽管很多人都在注意模型,但我们要关心数据,数据将重新定义我们对模型的看法”。
而时间也最终证明了李飞飞最初的想法是正确的,没有能反映真实世界的训练数据,再好的算法模型也没有用。
ImageNet创立之初
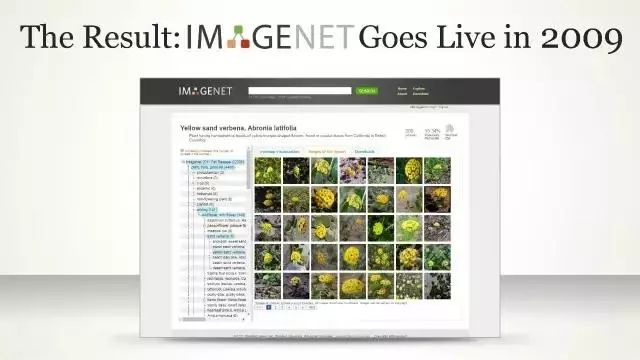
2005年,李飞飞从加州理工大学拿到电子工程学博士学位后进入了学术界,开始在伊利诺伊州香槟分校担任教职。那时她看到整个学术界和工业界重心都放在如何做出更好的算法,认为无论数据如何,只要算法好就会有好的决策。她意识到了这样做的局限,并且想到了一个解决方法,就是做一个能详细描绘出整个世界物体的数据集。她回忆起当时的情景深情地说道;“当时每个人对此都是一副怀疑的态度,但是 Kai Li( 李凯,普林斯顿Princeton大学教授,美国工程院院士) 做了两件厉害的事情,他说:‘飞飞,你的教授生涯刚刚开始,你想要做的事情,我实验室的所有的机器都可以拿来帮你,而且我还会给你一个学生。’如果没有这样的支持,我是没办法开始做 ImageNet 的。”

于是李飞飞、Jia Deng( 邓嘉,李飞飞的学生) 等研究员在 CVPR 2009 上发表了一篇名为《ImageNet: A Large-Scale Hierarchical Image Database》的论文,没过多久,这个数据集就迅速发展成一项竞赛,通过对数据集中的物体进行识别,选出识别错误率最低的算法。

赛事一经公布,便有多家科技企业参与进来。2010年选出的第一界竞赛优胜者,现在都出任了百度、谷歌和华为等公司高管(
如林元庆,余凯,张潼
)。马修·泽勒(Matthew Zeiler)2013年赢得ImageNet挑战赛后,在获奖算法基础上创办了Clarifai公司,目前获得了4000万美元风险投资。 谷歌与两位牛津大学的研究者共同获得2014年的ImageNet挑战赛冠军。随后,牛津大学的两位研究人员很快就被谷歌吸收,并进入谷歌收购的DeepMind实验室工作。 现在,参与ImageNet挑战赛获奖的企业和个人已遍布科技行业的每个角落。
ImageNet遇到难题
关于如何利用数据体现世界多样性一直是当时李飞飞需要解决的难题之一,最终她留意到了WordNet。 在WordNet里面,dog(狗)放在canine(犬科)下面,canine则会放在mammal(哺乳动物)下面,以此类推。这种语言组织方式依赖的是机器所能读懂的逻辑,并由此汇集了超过15.5万个索引单词。李飞飞研究了WordNet后,就去找了一直从事WordNet研究的克里斯蒂安·菲尔鲍姆(Christiane Fellbaum)。菲尔鲍姆认为,WordNet可以为每个单词找到一张相关的图片,但主要是为了参考,而不是建计算机视觉数据集。通过那次见面以后,李飞飞设想了一个更大胆的想法——组建一个庞大的数据集,为每个单词都提供更多例子。
李飞飞首先想到的就是雇佣本科生手工寻找图片,然后添加到数据集中。但她很快发现,按照这样的速度大约需要90年才能完成。
后来又想到能否让计算机视觉算法从互联网上选取图片,人工来验证图片的准确性?但经过几个月的研究后,发现同样不可行——算法将会随着时间的推移受到限制,只能在整理数据集时才能发现哪些算法具有识别能力。
直到有一次和一名研究生闲聊时,知道了亚马逊有一个众包平台 Mechanical Turk,可以把任务分发给全世界坐在电脑前的人。李飞飞得知后非常兴奋,感觉自己的ImageNet一定能做起来。随后接触发现 Mechanical Turk本身也面临一些缺陷,比如,如果某些参与该平台的人试图欺骗系统该怎么办? 李飞飞带领团队针对Mechanical Turk参与者的行为开发了一批统计模型,确保数据集中只包含正确的图片。
最终借助Mechanical Turk花了两年半时间才完成这个数据集。其中包含320万张经过标记的图片,共分成5,247种类别,12个子树,像“哺乳动物”、“汽车”和“家具”等。
ImageNet迎来辉煌
2017年是这场挑战赛的最后一年。这八年中,获奖者的算法正确识别率就从71.8%提升到97.3%,已远远超越了人类,并证明了越大的数据集确实可以带来更好的决策。
2009年,在京都一个计算机视觉会议上,一位名叫Alex Berg的参会人员拉住李飞飞,提议大赛中应该额外加入用算法定位图像目标的任务,而不仅仅是识别图像。李飞飞想了想说,你来加入我们吧。Berg、Jia Deng和李飞飞三人用这些数据集写出了五篇论文。其中第一篇论文成为了今后大赛如何用算法对大规模图片进行分类的比赛标准,也就是ImageNet挑战赛规则的前身。
“我们意识到,如果想把这个数据集大众化,我们还需要做更深入的研究。”李飞飞在第一篇论文中写道。
随后,李飞飞奔赴欧洲找到图像识别大赛PASCAL VOC的组委会,希望对方能和她合作,并帮助宣传ImageNet。PASCAL数据集当时有一定影响力,但只有20个类,而ImageNet当时有1000个类。

随着ImageNet接下来连续两年举办,它很快成为衡量分类算法在当时最复杂的图像数据集上的表现的一个基准。
研究人员后来也发现,他们的算法在使用ImageNet数据集训练时,表现效果会更好。
“当时很意外地发现用ImageNet训练过的模型可以做其他识别任务的启动模型,之后经过微调就能完成任务,”Berg说,“这不仅是神经网络的突破,也是常规认知的飞跃。”
到了2012年的ImageNet挑战赛,计算机视觉领域取得了重大成果。那一年,多伦多大学的Geoffrey Hinton、Ilya Sutskever和Alex Krizhevsky提出了一种深度卷积神经网络结构:AlexNet,成绩比当时的第二名高出41%。AlexNet现在依然在研究中被广泛使用。










