BCSPS数据实例
Brand& Xie (2010)提出了“负向选择假设”,即家庭背景越差,实际越不可能上大学的人,越有可能从上大学的行为中获益。然而,事与愿违的是,随着近十几年来大学学费的大幅上涨,以及次级劳动力市场就业机会的不断增加,对于那些经济并不宽裕的家庭,大学对他们正逐渐失去吸引力。有调查估计,中国农村学生在整个中学阶段的累计辍学率高达63%。舆论甚至不断出现“读书无用”或“寒门不能出贵子”的悲观论调。我博士论文的其中一章,From Poverty to Prosperity: College Education, Non-cognitive Abilities, and Earnings,关注的就是“大学是如何改变寒门学子命运”这一问题。
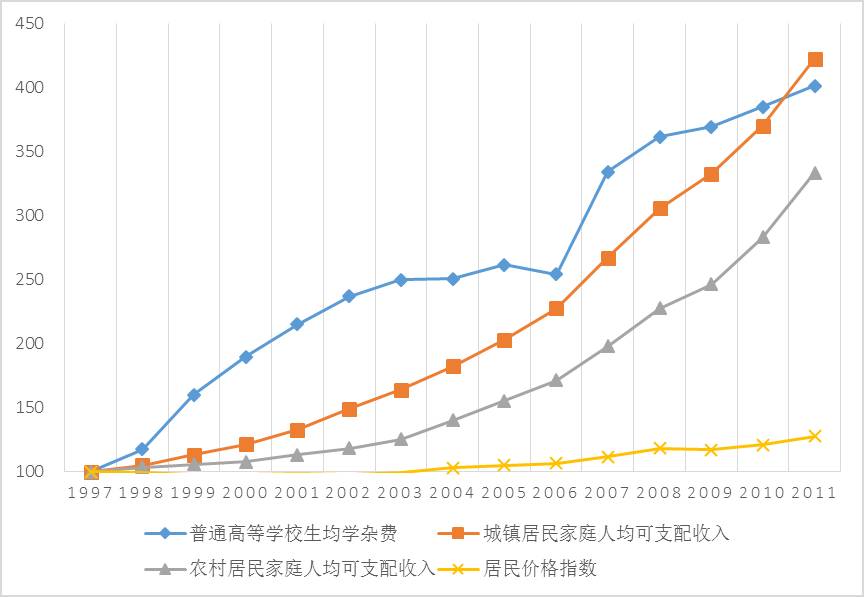
图1.中国普通高校大学生上学费用增长历史变化(1997年=100)
数据来源:《中国教育统计年鉴》、《中国统计年鉴》。
社会分层和流动研究发现,在受过大学教育的人群中,社会经济地位的代际相关性降低甚至消失了。这一发现被作为大学教育促进社会流动的有力证据。然而,其作用机制往往被简单地归因于学生的高度选择性,或者是劳动力市场中大学文凭的符号效应,
而大学本身作为一个重要的教育过程,对学生人力资本积累的影响却甚少被提及或证实。
其中一个重要原因是由于数据的限制:在以往很多的横截面调查中,我们只能观察到个人从大学毕业后的结果,而不可能知道他刚上大学时,或即将毕业前的能力和表现,也就无从判断大学四年间,他们的能力是否有实质性的提高。
而得益于BCSPS的五轮的追踪数据,我们就可以对大学生在校期间的成长经历和从学校走向社会的转变过程进行动态的观测。
越来越多的研究证据表明,在现代社会中,个人的非认知能力对于其在劳动力市场的表现有显著的影响。
而这篇文章的分析结果也证实,即便在同质性较高的大学生群体中,非认知能力的差异也超越了家庭背景,成为了对收入最为重要和稳定的影响因素之一。因此,考察来自不同社会阶层的人在非认知能力上的差距,以及这一差距在大学期间的变化趋势,对于帮助我们理解高等教育对于收入不平等的作用就变得非常必要。
利用BCSPS的五期数据和个人增长曲线模型,
这项研究发现,大学四年的教育过程逐步缩小了贫困大学生与其他普通大学生之间在非认知能力上的差距。
这一平等化的过程使贫困大学生与普通大学生的初职收入差距缩小了一个百分点。虽然这一效应从绝对数值来看并不大,然而,由于会影响工作收入的先赋性因素(比如说家庭出身)本身无法改变,且这一筛选过程早在进入大学前就业已完成,
因此大学教育在短短四年中对于关键人力资本的提升作用可以被看作是高等教育能“改变命运”的直接证据。
与我们的想象不同的是,在大学期间,贫困大学生在学业成绩,荣誉获得,社团活动参与,入党,实习兼职等方面的在校表现都要比非贫困大学生更为优秀,而由于这些活动均与非认知能力的增长有很强的相关性,这有可能提供了一个有效地机制来帮助他们克服家庭出身方面的劣势,并最终消除他们与其他家庭出身较好的大学生在个人能力,以及在之后的劳动力市场表现上的差距。简而言之,
这个研究的发现驳斥了所谓的“读书无用论”,证明了上大学依然是寒门学子改变命运,实现向上流动的重要途径。
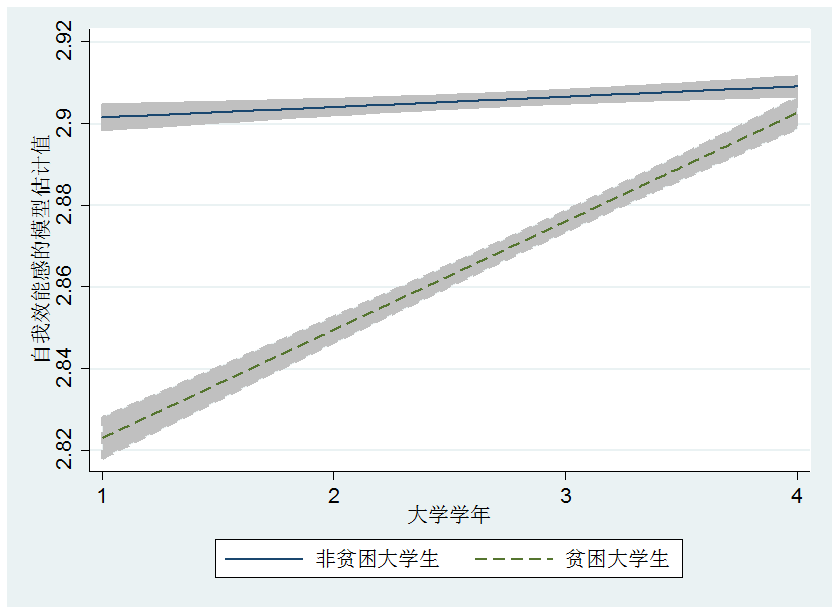
图2. 模型估计出的大学生在校期间自我效能感的变化趋势,按是否贫困划分









