以上是学习判别器 D 的过程。因为学习 D 的过程是计算 JS 散度的过程,并且我们希望能最大化价值函数,所以该步骤会重复 k 次。
-
从先验分布 P_prior(z) 中抽取另外 m 个噪声样本 {z^1,...,z^m}
-
通过极小化 V^tilde 而更新生成器参数θ_g,即极大化
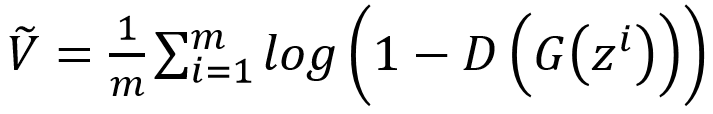 ,且生成器参数的更新迭代式为
,且生成器参数的更新迭代式为
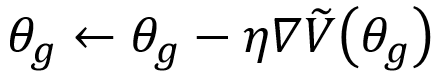
以上是学习生成器参数的过程,这一过程在一次迭代中只会进行一次,因此可以避免更新太多而令 JS 散度上升。
实现
在上一期机器之心 GitHub 项目中,我们从零开始使用 TensorFlow 实现了简单的 CNN,我们不仅介绍了 TensorFlow 基本的操作,并从全连接神经网络开始简单地实现了 LeNet-5。在第一期 GitHub 实现中,我们陆续上传了三段实现代码,第二次上传补充的是全连接网络进行 MNIST 图像识别,我们逐行注释了该模型的所有代码。第三次上传补充的是使用 Keras 构建简单的 CNN,我们同样添加了大量注释。本文是第二期 GitHub 实现,首先提供的是 GAN 实现代码与注释,随后我们会将以上的理论分析与实现代码相结合并展示在 Jupyter Notebook 中。虽然首次实现使用的是比较简单的高级 API(Keras),但后面我们会补充使用 TensorFlow 构建 GAN 的代码与注释。
GitHub 实现地址:
https://github.com/jiqizhixin/ML-Tutorial-Experiment
机器之心首先使用基于 TensorFlow 后端的 Keras 实现了该生成对抗网络,并且我们在 MNIST 数据集上对模型进行训练并生成了一系列手写字体。这一章节只简要解释部分实现代码,更完整与详细的注释请查看 GitHub 项目地址。
生成模型
首先需要定义一个生成器 G,该生成器需要将输入的随机噪声变换为图像。以下是定义的生成模型,该模型首先输入有 100 个元素的向量,该向量随机生成于某分布。随后利用两个全连接层接连将该输入向量扩展到 1024 维和 128*7*7 维,后面就开始将全连接层所产生的一维张量重新塑造成二维张量,即 MNIST 中的灰度图。我们注意到该模型采用的激活函数为 tanh,所以也尝试过将其转换为 relu 函数,但发现生成模型如果转化为 relu 函数,那么它的输出就会成为一片灰色。
由全连接传递的数据会经过几个上采样层和卷积层,我们注意到最后一个卷积层所采用的卷积核为 1,所以经过最后卷积层所生成的图像是一张二维灰度图像,更详细的分析请查看机器之心 GitHub 项目。
def generator_model():
#下面搭建生成器的架构,首先导入序贯模型(sequential),即多个网络层的线性堆叠
model = Sequential()
#添加一个全连接层,输入为100维向量,输出为1024维
model.add(Dense(input_dim=100, output_dim=1024))
#添加一个激活函数tanh
model.add(Activation('tanh'))
#添加一个全连接层,输出为128×7×7维度
model.add(
Dense(128*7*7))
#添加一个批量归一化层,该层在每个batch上将前一层的激活值重新规范化,即使得其输出数据的均值接近0,其标准差接近1
model.add(BatchNormalization())
model.add(Activation('tanh'))
#Reshape层用来将输入shape转换为特定的shape,将含有128*7*7个元素的向量转化为7×7×128张量
model.add(Reshape((7, 7, 128), input_shape=(128*7*7,)))
#2维上采样层,即将数据的行和列分别重复2次
model.add(UpSampling2D
(size=(2, 2)))
#添加一个2维卷积层,卷积核大小为5×5,激活函数为tanh,共64个卷积核,并采用padding以保持图像尺寸不变
model.add(Conv2D(64, (5, 5), padding='same'))
model.add(Activation('tanh'))
model.add(UpSampling2D(size=(2, 2)))
#卷积核设为1即输出图像的维度
model.add(Conv2D(1, (5, 5), padding='same'))
model.add(
Activation('tanh'))
return model
拼接
前面定义的是可生成图像的模型 G(z;θ_g),而我们在训练生成模型时,需要固定判别模型 D 以极小化价值函数而寻求更好的生成模型,这就意味着我们需要将生成模型与判别模型拼接在一起,并固定 D 的权重以训练 G 的权重。下面就定义了这一过程,我们先添加前面定义的生成模型,再将定义的判别模型拼接在生成模型下方,并且我们将判别模型设置为不可训练。因此,训练这个组合模型才能真正更新生成模型的参数。
def generator_containing_discriminator(g, d):
#将前面定义的生成器架构和判别器架构组拼接成一个大的神经网络,用于判别生成的图片
model = Sequential()
#先添加生成器架构,再令d不可训练,即固定d
#因此在给定d的情况下训练生成器,即通过将生成的结果投入到判别器进行辨别而优化生成器
model.add(g)
d.trainable = False
model.add(d)
return model
判别模型
判别模型相对来说就是比较传统的图像识别模型,前面我们可以按照经典的方法采用几个卷积层与最大池化层,而后再展开为一维张量并采用几个全连接层作为架构。我们尝试了将 tanh 激活函数改为 relu 激活函数,在前两个 epoch 基本上没有什么明显的变化。
def discriminator_model():
#下面搭建判别器架构,同样采用序贯模型
model = Sequential()
#添加2维卷积层,卷积核大小为5×5,激活函数为tanh,输入shape在‘channels_first’模式下为(samples,channels,rows,cols)
#在‘channels_last’模式下为(samples,rows,cols,channels),输出为64维
model.add(
Conv2D(64, (5, 5),
padding='same',
input_shape=(28, 28, 1))
)
model.add(
Activation('tanh'))
#为空域信号施加最大值池化,pool_size取(2,2)代表使图片在两个维度上均变为原长的一半
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, (5, 5)))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#Flatten层把多维输入一维化,常用在从卷积层到全连接层的过渡
model.add(Flatten())
model.add(Dense
(1024))
model.add(Activation('tanh'))
#一个结点进行二值分类,并采用sigmoid函数的输出作为概念
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
训练
训练这一部分比较长,也值得我们进行详细的探讨。总的来说,以下训练过程可简述为:
以上是下面训练过程的简要介绍,我们将结合上文的理论推导在 GitHub 中展示更详细的分析。
def train(BATCH_SIZE):
# 国内好像不能直接导入数据集,我们试了几次都不行,后来将数据集下载到本地'~/.keras/datasets/',也就是当前目录(我的是用户文件夹下)下的.keras文件夹中。
#下载的地址为:https://s3.amazonaws.com/img-datasets/mnist.npz
(X_train, y_train), (X_test, y_test) = mnist.load_data()
#iamge_data_format选择"channels_last"或"channels_first",该选项指定了Keras将要使用的维度顺序。
#"channels_first"假定2D数据的维度顺序为(channels, rows, cols),3D数据的维度顺序为(channels, conv_dim1, conv_dim2, conv_dim3)
#转换字段类型,并将数据导入变量中
X_train = (X_train.astype(np.float32) - 127.5)/
127.5
X_train = X_train[:, :, :, None]
X_test = X_test[:, :, :, None]
# X_train = X_train.reshape((X_train.shape, 1) + X_train.shape[1:])
#将定义好的模型架构赋值给特定的变量
d = discriminator_model()
g = generator_model()
d_on_g = generator_containing_discriminator(g, d)
#定义生成器模型判别器模型更新所使用的优化算法及超参数
d_optim = SGD(lr=0.001, momentum=0.9, nesterov=True)
g_optim = SGD(lr=0.001, momentum=0.9, nesterov=True)
#编译三个神经网络并设置损失函数和优化算法,其中损失函数都是用的是二元分类交叉熵函数。编译是用来配置模型学习过程的
g.compile(loss='binary_crossentropy', optimizer="SGD")
d_on_g.compile(loss='binary_crossentropy', optimizer=g_optim)
#前一个架构在固定判别器的情况下训练了生成器,所以在训练判别器之前先要设定其为可训练。
d.trainable = True
d.compile(loss='binary_crossentropy', optimizer=d_optim)
#下面在满足epoch条件下进行训练
for epoch in range(30):
print("Epoch is", epoch)
#计算一个epoch所需要的迭代数量,即训练样本数除批量大小数的值取整;其中shape[0]就是读取矩阵第一维度的长度
print("Number of batches", int(X_train.shape[0]/BATCH_SIZE))
#在一个epoch内进行迭代训练
for index in range(int(X_train.shape[0]/BATCH_SIZE)):









