
你的 QQ 头像(或者微博头像)右上角加上红色的数字,类似于微信未读信息数量那种提示效果。 类似于图中效果

这个问题需要用到PIL库,涉及到一些非常基本的用法。代码如下:

作为一个Python初学者,写这段程序的时候遇到了很多错误,首先是路径,“\”需要用转义字符来转义一下。
在实例字体对象的时候,需要加载系统中的字体,windows系统的字体文件在C:\windows\fonts目录下面,一开始加载的时候直接用了资源管理器中显示的名称,并且理所当然的认为文件应该是ttf文件。结果报错
IOError: cannot open resource
肯定是找不到文件了,于是从fonts目录拷贝了一种字体到其它文件夹,发现文件名称弄错了,而且有些字体看起来是一个文件,拷贝到其它文件会变成好几个文件,而且文件名也跟看起来不太一样。
为了图省事,直接把字体文件拷贝到了工作目录下的pictures文件夹了。
最后调用text()方法给图片添加文字时,出现了喜闻乐见的编码错误:
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 37: ordinal not in range(128)
利用万能的Google,解决方法如下:

做为 Apple Store App 独立开发者,你要搞限时促销,为你的应用
生成激活码
(或者优惠券),使用 Python 如何生成 200 个激活码(或者优惠券)?
知识点:
1、range生成随机数
2、int类型转换成char类型用chr() 函数
3、从list中随机取数,用random.sample()

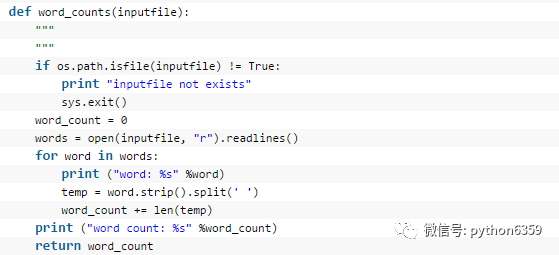
任一个英文的纯文本文件,统计其中的单词出现的个数
1、strip()没有参数时,删除空白符,包括\n \r \t 空格。strip() 函数只能用于str类型,list类型等不可用。
2、split()用于分割,分隔符可以自己制定
你有一个目录,装了很多照片,把它们的尺寸变成都不大于 iPhone5 分辨率的大小。

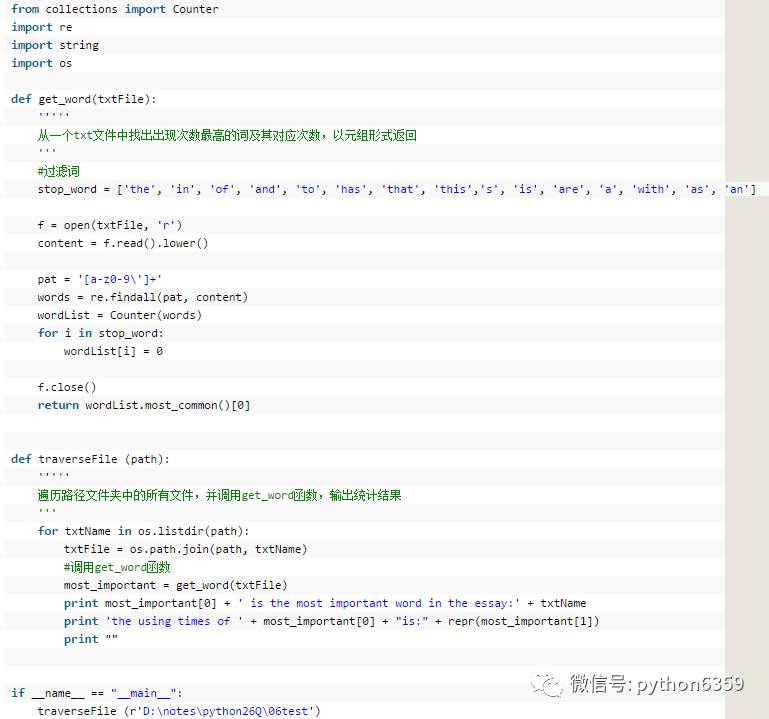
你有一个目录,放了你一个月的日记,都是 txt,为了避免分词的问题,假设内容都是英文,请统计出你认为每篇日记最重要的词。
简单分析题目可知,可以把整个程序设计分为以下两个部分来完成:
函数1:遍历目标目录下的所有文件,对于每个txt文件调用函数2统计单词,输出结果。
函数2:对传入的txt文件进行单词计数统计,返回最高频使用的词及其出现次数。
可以看出本题的重点在于函数2的实现。
下面重点分析一下函数2的实现:
1.从txt文件中读出文章内容后,因文章中单词大小写不一,不方便后续处理,使用 string.lower() 方法,将文章内容统一小写化
2.使用 re.findall() 方法进行正则表达式匹配,值得注意的是 re.findall() 方法匹配后会返回一个由文章所有词组成的列表,且重复出现的单词不会被去重
3.使用 list.Counter() 方法对列表中单词出现次数进行排序,会返回一个单词—出现次数一一键值对应的字典
4.排除一些代词、冠词的干扰,即代码中使用stop_word进行的过滤词
5.使用 Counter.most_common() 方法对字典中的词按值排降序,会返回一个由许多元组所组成的列表,按值的大小依次降序排列
有个目录,里面是你自己写过的程序,统计一下你写过多少行代码。包括空行和注释,但是要分别列出来。

from bs4 import BeautifulSoup
import requests
r = 'http://www.toutiao.com/a6389133537292304642/'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
url = requests.get(r,headers=headers)
soup = BeautifulSoup(url.text,'lxml')
print(soup.get_text())

使用 Python 生成类似于下图中的
字母验证码图片

|
#
coding=utf-8
|
|
|
import
os
|
|
from
PIL
import
Image
|
|
from
PIL
import
ImageDraw
|
|
from
PIL
import
ImageFont
|
|
import
numpy,random,numexpr
|
|
path
=
os.path.split(os.path.realpath(
__file__
))[
0
]
|
|
NewArray
=
numpy.zeros((
100
,
300
,
3
),
dtype
=
numpy.uint8)
|
|
Sh
=
NewArray.shape
|
|
for
i
in
range
(Sh[
0
]):
|
|
for
j
in
range
(Sh[
1
]):
|
|
for
k
in
range
(Sh[
2
]):
|
|
NewArray[i][j][k]
=
random.randint(
0
,
255
)
|
|
im
=
Image.fromarray(NewArray)
|
|
D
=
ImageDraw.Draw(im)
|
|
L
=
[
chr
(i
+
65
)
for
i
in
range
(
26
)]
+
[
chr
(i
+
97
)
for
i
in
range
(
26
)]
|
|
for
i
in
range
(
4
):
|
|
D.text((
75
*
i
+
10
+
random.randint(
-
10
,
10
),random.randint(
0
,
40
)), random.choice(L),
font
=
ImageFont.truetype(os.path.split(path)[
0
]
+
"
/public/msyh_3.ttf
"
,
55
),
fill
=
(random.randint(
0
,
255
),random.randint(
0
,
255
),random.randint(
0
,
255
)))
|
|
im.save(path
+
"
/code.jpg
"
)
|
敏感词文本文件 filtered_words.txt,里面的内容为以下内容,当用户输入敏感词语时,则打印出 Freedom,否则打印出 Human Rights。

敏感词文本文件 filtered_words.txt,里面的内容 和 0011题一样,当用户输入敏感词语,则用 星号 * 替换,例如当用户输入「北京是个好城市」,则变成「**是个好城市」。










