(点击
上方公众号
,可快速关注)
来源:腾云阁 - 孔德雨
链接:www.qcloud.com/community/article/190
mongodb 可以以单复制集的方式运行,client 直连mongod读取数据。
单复制集的方式下,数据的水平扩展的责任推给了业务层解决(分实例,分库分表),mongodb原生提供集群方案,该方案的简要架构如下:
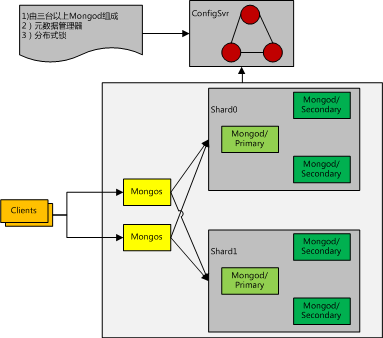
mongodb集群是一个典型的去中心化分布式集群。mongodb集群主要为用户解决了如下问题:
下文通过介绍mongodb集群中各个组成部分,逐步深入剖析mongodb集群原理。
ConfigServer
mongodb元数据全部存放在configServer中,configServer 是由一组(至少三个)mongod实例组成的集群。
configServer 的唯一功能是提供元数据的增删改查。和大多数元数据管理系统(etcd,zookeeper)类似,也是保证一致性与分区容错性。本身不具备中心化的调度功能。
ConfigServer与复制集
ConfigServer的分区容错性(P)和数据一致性(C)是复制集本身的性质。
MongoDb的读写一致性由WriteConcern和ReadConcern两个参数保证。
两者组合可以得到不同的一致性等级。
指定 writeConcern:majority 可以保证写入数据不丢失,不会因选举新主节点而被回滚掉。
mongodb 对configServer全部指定writeConcern:majority 的写入方式,因此元数据可以保证不丢失。
对configServer的读指定了ReadPreference:PrimaryOnly的方式,在CAP中舍弃了A与P得到了元数据的强一致性读。
Mongos
数据自动分片
对于一个读写操作,mongos需要知道应该将其路由到哪个复制集上,mongos通过将片键空间划分为若干个区间,计算出一个操作的片键的所属区间对应的复制集来实现路由。
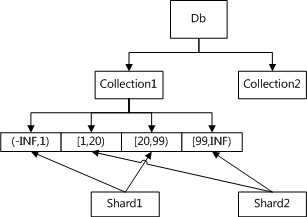
Collection1 被划分为4个chunk,其中
-
chunk1 包含(-INF,1) , chunk3 包含[20, 99) 的数据,放在shard1上。
-
chunk2 包含 [1,20), chunk4 包含[99, INF) 的数据,放在shard2上。
chunk 的信息存放在configServer 的mongod实例的 config.chunks 表中,格式如下:
{
"_id"
:
"mydb.foo-a_"
cat
""
,
"lastmod"
:
Timestamp
(
1000
,
3
),
"lastmodEpoch"
:
ObjectId
(
"5078407bd58b175c5c225fdc"
),
"ns"
:
"mydb.foo"
,
"min"
:
{
"animal"
:
"cat"
},
"max"
:
{
"animal"
:
"dog"
},
"shard"
:
"shard0004"
}
值得注意的是:chunk是一个逻辑上的组织结构,并不涉及到底层的文件组织方式。
启发式触发chunk分裂
mongodb 默认配置下,每个chunk大小为16MB。超过该大小就需要执行chunk分裂。chunk分裂是由mongos发起的,而数据放在mongod处,因此mongos无法准确判断每个增删改操作后某个chunk的数据实际大小。因此mongos采用了一种启发式的触发分裂方式:
mongos在内存中记录一份 chunk_id -> incr_delta 的哈希表。
对于insert和update操作,估算出incr_delta的上界(WriteOp::targetWrites), 当incr_delta超过阈值时,执行chunk分裂。
值得注意的是:
1) chunk_id->incr_delta 是维护在mongos内存里的一份数据,重启后丢失
2) 不同mongos之间的这份数据相互独立
3) 不带shardkey的update 无法对 chunk_id->incr_delta 作用
因此这个启发式的分裂方式很不精确,而除了手工以命令的方式分裂之外,这是mongos自带的唯一的chunk分裂方式。
chunk分裂的执行过程
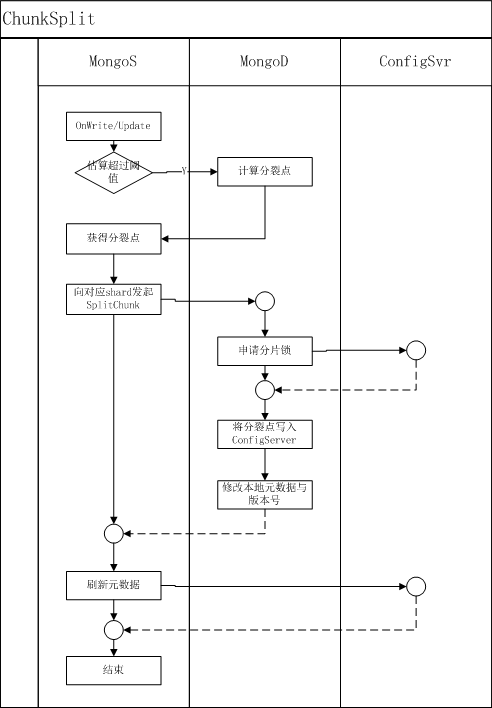
1) 向对应的mongod 发起splitVector 命令,获得一个chunk的可分裂点
2) mongos 拿到这些分裂点后,向mongod发起splitChunk 命令
splitVector执行过程:
1) 计算出collection的文档的 avgRecSize= coll.size/ coll.count
2) 计算出分裂后的chunk中,每个chunk应该有的count数, split_count = maxChunkSize / (2 * avgRecSize)
3) 线性遍历collection 的shardkey 对应的index的 [chunk_min_index, chunk_max_index] 范围,在遍历过程中利用split_count 分割出若干spli
splitChunk执行过程:
1) 获得待执行collection的分布式锁(向configSvr 的mongod中写入一条记录实现)
2) 刷新(向configSvr读取)本shard的版本号,检查是否和命令发起者携带的版本号一致
3) 向configSvr中写入分裂后的chunk信息,成功后修改本地的chunk信息与shard的版本号
4) 向configSvr中写入变更日志
5) 通知mongos操作完成,mongos修改自身元数据
chunk分裂的执行流程图:
问题与思考
问题一:为何mongos在接收到splitVector的返回后,执行splitChunk 要放在mongod执行而不是mongos中呢,为何不是mongos自己执行完了splitChunk再通知mongod 修改元数据?
我们知道chunk元数据在三个地方持有,分别是configServer,mongos,mongod。如果chunk元信息由mongos更改,则其他mongos与mongod都无法第一时间获得最新元数据。可能会发生这样的问题,如下图描述: