
图:Pixabay
追踪和报道新闻时,记者需要保护消息来源的身份。许多的重磅报道都坚守着这个规则,即便是在披露关键信息和保护消息来源(特别是当消息人士正面临人身安全风险)之间取得平衡通常不易。
当今这个无处不在收集数据的时代,这种挑战尤其凸出。计算机技术的发展,让人们可以处理海量数据,同时造就人们以数据牟利、实施监控等。在众多事例中,原来被视为基本需求的个人隐私反而被视作障碍。从“剑桥分析”(Cambridge Analytica)挪用个人数据进行定点广告投放,到智能设备被用于侵入式数据跟踪,众多事例反映出,随着数据不断被盗取和外泄,人们似乎对保护隐私逐渐麻木。
当可获取数据前所未有的多,记者在报道时也愈来愈依赖数据。不过,记者除了考虑怎样保护机密消息来源,也要衡量如何发布数据,才不会泄露不必要的个人信息。就大多数新闻故事而言,记者可能有需要披露部分个人信息,但没必要点名庞大数据中的每个个体,如是者可以采取“去识别”(de-identification)或“匿名化”(anonymization)来保护个人隐私。
虽然2000年代末期的法律改革确立了对个人信息的定义,但有意无意的数据外泄事件依然持续发生,并且危害着个人隐私,而新闻工作者长期扮演揭发这些外泄事件的重要角色。“美国线上”(AOL)于2006年公布数以百万计的网络搜寻数据,记者单凭个人搜寻记录,包括健康状况、约会偏好等敏感信息,就能整理出个别人士的身份信息。同样,中央情报局前雇员斯诺登(Edward Snowden)披露美国国家安全局(NSA)的大规模监控行动之后,各项研究纷纷揭示通信元资料如何被用于识别及监控通讯设备用户。
当记者决定以数据集作为新闻故事的消息来源,他们就肩负起权衡信息敏感度的责任。要作出准确的评估,首先要了解什么是个人信息,什么不是。
“个人可识别信息”(Personally identifiable information,PII)在欧洲法律上以“个人数据”(personal data)来指涉,而在其他部分司法管辖区则以“个人信息”(personal information)来指涉。“个人可识别信息”通常被理解为可以直接识别个人的任何信息,这些信息按不同程度的可识别度和敏感度,处于图谱上的不同位置。例如,姓名、电邮地址等信息的可识别度高,但低敏感度低,发布这些信息通常不会危害个人;相对地,位置数据、个人健康记录等信息的可识别度低,但敏感度高。为了方便说明,我们可以因应可识别度和敏感度,在图谱上定位各种类型的“个人可识别信息”。
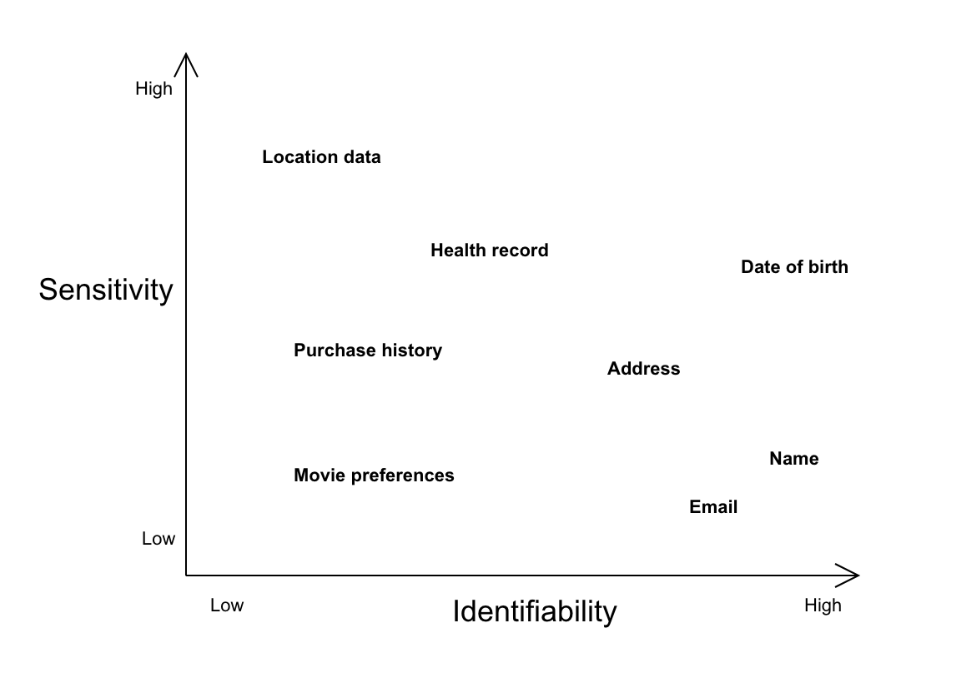
“个人可识别信息”通常被理解为可以直接识别个人的任何信息。图:Datajournalism.com
“个人可识别信息”的可识别度和敏感度,同时取决于文本背景和数据混合后产生的复合效果。例如,发布 Facebook 粉丝数据库中的某君姓名,可能只会产生低风险,但发布一份政治异议人士名单上的某君姓名,带来的风险就会大大增加。多项数据结合应用时,信息的价值也会出现变化,例如单看一个购买记录数据库,很难连系到任何特定个人,但结合位置信息或信用卡号码,可识别度和敏感度则会大大提高。
2016年有这样的一个事例:澳大利亚卫生部发布了一批“去识别”药物数据,数据限定用于学术研究,只让学者解密部分信息;然而当地隐私专员认为,这依然构成个人信息被曝光的可能,因此介入调查。同样在2016年,BuzzFeed 就职业网球员的欺诈行为进行调查报道,并且发布了经过“匿名化”处理的相关数据;然而,一群大学生结合利用其他公开数据,成功“再识别”出报道中没有点名的涉事网球员。这此事例说明,新闻工作者要准确判断数据集中的个人信息性质,就必须兼顾评估数据集包含的信息,以及可能已经公开的其他信息。

尽管这些网球球员的姓名经过了匿名化的处理, 然而,一群大学生结合利用其他公开数据,成功“再识别”出报道中没有点名的涉事网球员. 图:Datajournalism.com
为了隐藏消息来源的身份,新闻工作者可能会以匿名或化名来处理,例如“水门事件”报道中所使用的“深喉”(Deep Throat)。处理信息时,删除个人信息的过程被称为“去识别”(de-identification),或在一些司法管辖区被称为“匿名化”(anonymization)。早在互联网诞生前,新闻工作者已在应用“去识别”技术,例如在外泄文件上涂掉某些姓名。时至今天,新闻工作者配备了更多崭新的“去识别”方法和工具,可以在数字环境中保护隐私,同时更便于分析和处理前所未有的庞大数据。
“去识别”的目的就是防止“再识别”(re-identification),换句话说就是将数据“匿名化”,令数据无法被用于识别任何个人。虽然“匿名化”在法律上存在一些定义,但实质的规范和操作,通常建基于不同行业的规矩。例如在美国,医疗保健记录受《健康保险便利和责任法案》(HIPAA)的规范,病人姓名、住址、社会安全号码等直接标识必须经过“匿名化”处理。而在欧盟地区,《一般资料保护规范》(GDPR)规定姓名、住址、电邮地址等直接标识,以及工作职衔、邮政编码等间接标识,均要作“匿名化”处理。
编写新闻故事时,记者需要判断哪些信息属于关键,哪些信息可以忽略。一般来说,愈有价值的信息愈是敏感。例如,医学研究人员必须掌握临床诊断数据和其他医药数据,尽管这些数据很可能与特定个人存在联系,属于高度敏感数据。为了在数据的实用性和敏感度之间取得平衡,记者在决定发布哪些内容时,可以采取适用的“去识别”技术。
数据改写(Data Redaction)

一份 CIA 数据改写的文档. 图片: Wikimedia
最简单的数据库“去识别”方法,是直接删除所有个人或敏感数据。“数据改写”存在一个明显的缺点,就是可能丢失一些有价值信息,不过这种方法一般用于处理直接标识,例如姓名、地址、社会安全号码,而这些数据通常并非新闻故事的症结所在。










