
6 月 29 日,台湾大学,卷积神经网络之父、FacebookAI 研究院院长 Yann LeCun 以「Deep Learning and the Path to AI」为题,对深度学习目前的发展现状和面临的最大挑战、以及应对方法进行了综述和分析。新智元结合台湾大学在 Facebook 上公布的视频、台湾科技媒体 iThome 的报道,以及 Yann LeCun 今年早些时候在爱丁堡大学的演讲资料,为您综合介绍。
深度学习的特点在于“整个程序都是可训练的”
演讲从模式识别(Pattern Recognition)的起源说起。1957年,Perceptron 诞生,成为第一个 LearningMachine。LeCun 说,目前的机器学习算法大多衍生自 Perceptron的概念。
从那时起,模式识别的标准模型就可以分为 3 步走:1.程序被输入一张图像,通过特征提取,将图像特征转换为多个向量;2. 输入这些向量到可训练的分类器中;3.程序输出识别结果。
他表示,机器学习算法其实就是误差校正(Error correction),通过调整权重,来进行特征提取。也就是说,如果输入一张图,算法识别后,结果值低于预期类别的值,工程师就将输入的图增加 Positive 的权重,减少 Negative 的权重,来校正误差。

深度学习是当今最广泛使用的模式识别方法。LeCun 认为深度学习的特点在于“整个程序都是可训练的”。他解释,构建深度学习的模型不是用手动调整特征提取的参数来训练分类器,而是建立一群像小型瀑布般的可训练的模组。

当开发人员将原始的影像输入系统后,会先经过初步的特征提取器,产生代表的数值,在这一个阶段可能会先识别出一些基本的纹理,接下来这些纹理的组合会再被拿来识别更具体的特征,像是物件的形体或是类别,整个训练的过程就是不断地经过一层又一层这样的模型,每一层都是可训练的,所以我们称这个算法为深度学习或是端到端训练(End to End Running)。
LeCun 解释,深度学习模型之所以工作良好,是因为现在的影像都是自然景象加上其他物体,也就是混合型的图像,而每个物体又由不同的特征所组成,会有不同的轮廓和纹路,图片的像素也是一个问题,因此,可以将影像分级成像素、边缘、轮廓、元件和物件等,初级的特征提取会先侦测出影像中最基本的轮廓,比如明显的纹路和色块,进一步的特征提取则是将上一层的结果组合再一起,拼成一个形体,最后再拼成一个物体。

这种分层式的组合架构(Hierarchical Compositionality)其实不只适用于影像,LeCun说明,它对文字、语音、动作或是任何自然的信号都适用,这种方式参考了人脑的运作模式。大脑中的视觉中枢,也是用类似分层式的组合架构来运行,当人类看到影像后,由视网膜进入到视丘后方外侧膝状体,再到大脑中主要的视觉中枢,最后来到颞叶皮质,人类看图像也是由大脑经过多层的结构,在100毫秒内就能识别图片。

深度学习的问题在于如何训练,在1980年代中期,误差反向传播算法(Back Propagation Algorithm)开始流行,但其实误差反向传播算法很早就被提出来,只是当时没有受到重视。误差反向传播算法一开始先经过简单线性分类,再将这些结果带到非线性的线性整流函数(Rectified Linear Unit,ReLU),线性整流函数就是找到要调整参数的方向,来减少错误判断,不过现在都已经有可用的套件或是框架,像是Torch、TensorFlow 或是 Theano等,还有一些套件是可用来计算输出结果和预期结果之间的误差。
Yann LeCun认为,现在要撰写机器学习算法并不难,用 3 行 Python 就可以完成,不过这还停留在监督式学习阶段,所谓的监督式学习就是输入大量的训练样本,每一套训练样本都已经经过人工标注出原始图片和对应的预期结果。以影像处理为例,训练集由多个(X,Y)参数组成,X就是影像的像素,Y则是预设的识别结果类别,像是车子、桌子等,之后再用大量的测试集来测试程序,若判断结果正确,不用调整,若判断有误则调整程序中的参数。
监督式机器学习存在二大问题
因此,Yann LeCun表示,监督式的机器学习就是功能优化(Function Optimization),资料输入和输出的关系通过可调整的参数来优化,经由调整参数的方式,将结果的错误率降至最低,其中,调整参数的方式有很多种,很多人都会用梯度下降算法(Stochastic Gradient Descent),梯度下降算法可以找到最适合的回归模型系数.即时地根据输入的资料动态调整模型。
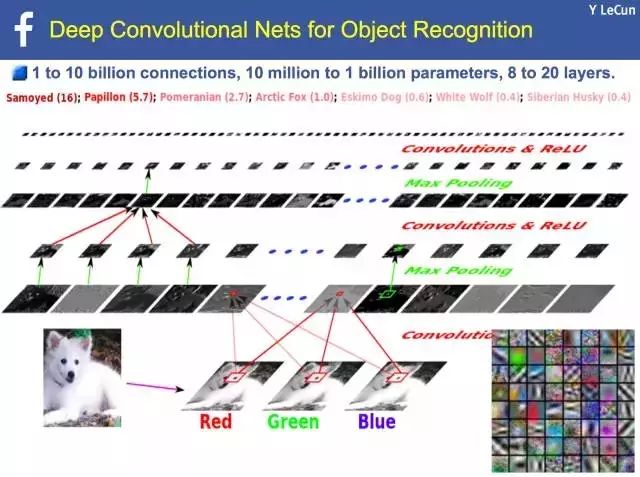
身为「卷积神经网络之父」的 Yann LeCun 也介绍了卷积神经网络(Convolutional Neural Network,CNN),卷积网络就是将输入的影像像素矩阵经过一层过滤器,挑选出特征,再透过池化层(PoolingLayer),针对输入特征矩阵压缩,让特征矩阵变小,降低计算的复杂度。CNN影像和语音识别都有很好的成效,不仅如此,还能识别街上移动的路人、街景的物体,Facebook 也用 CNN 来识别 Facebook 用户上传的照片,他表示一天 Facebook 就有10亿以上的照片,可以準确地识别物体的类别,像是人还是狗、猫等,还能识别照片的主题,像是婚礼或是生日派对等。

不过,Yann LeCun提出,监督式的机器学习有2大问题,第一是要如何建立复杂的算法来解决复杂的问题,第二则是手动调整参数的知识和经验都是来自于不同任务,许多工程师想要处理的领域,像是影像识别、语音识别都需要建置不同模型,因此,监督式机器学习可以在训练过的专案上有很好的表现,但是没有训练过的资料,程序就无法辨别,简单来说,如果要程序识别椅子,不可能训练所有椅子的特征资料。
事实上,Yann LeCun 表示现实中有种机器具备数百万的调整钮(Knob),这些调整钮就像机器学习中的参数和 Perceptron 的权重一样,可以用上百万的训练样本来训练模型,最后分类出上千种的类别,但是,每一个特征的识别都必须经过数十亿次的操作,因此,可想而知,现今大家所使用的神经网络是非常复杂的,如此庞大的运作不可能在一般的 CPU 上执行,“我们面对的是非常大规模的优化问题。”他说。
AI系统的架构

AI系统的架构大致上可以分为感知(Perception)、触发器(Agent)和目标(Objective)3个模组,先由感知器侦测真实世界的数据,像是影像、语音等,这些数据经由触发器,会依据状态触发目标,执行相对应的程序并产生结果,其中触发器就是AI 的精髓,触发器必须要负责规划、预测等智能工作,而目标则是由本能和固定的两个元件所组成,以视觉识别(VisualIdentity)系统为例,经由感知收集影像数据,透过触发器触发分析情绪的程序,再判断影片中的人是开心还是不开心。
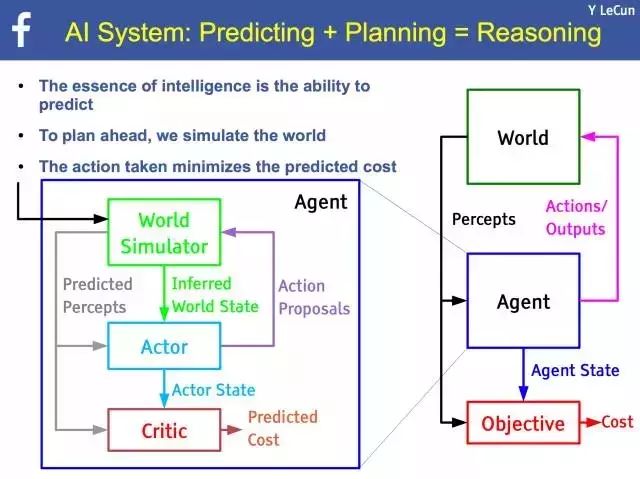
AI 架构中的触发器(Agent)主要负责预测和规划,运作过程又可分为模拟器(Simulator)、执行器(Actor)、回馈器(Critic),模拟器接收到状态后,传送给执行器,执行器就会启动相对应的动作,并同时对模拟器提出要求,启动相对应的动作之后送到回馈器,经由回馈器分析要採取的动作,决定后才送往目标(Objective)执行。
AI 最大局限是没有人类的“常识”

市场上 AI 好像无所不能,但其实,Yann LeCun个人认为,AI 还是有些局限,像是机器必须会观察状态、了解很多背景知识、世界运行的定律,以及精确地判断、规划等,其中,Yann LeCun 认为 AI 最大的局限是无法拥有人类的「常识」。

由于目前比较好的AI应用都是采用监督式学习,能够准确识别人工标示过的物体,也有些好的成果是用强化学习(Reinforcement Learning)的方式,但是强化学习需要大量地收集资料来训练模型,Yann LeCun表示,对应到现实社会中的问题,监督式学习不足以成为“真的”AI。
他指出,人类的学习是建立在与事物互动的过程,许多都是人类自行体会、领悟出对事物的理解,不需要每件事都要教导,举例来说,若有个物体被前面的物体挡住,人类会知道后面的物体依然存在的事实,或是物体没有另一个物体支撑就会掉落的事实。
“人脑就是推理引擎!”他说明,人类靠着观察建立内部分析模型,当人类遇到一件新的事物,就能用这些既有的模型来推测,因为生活中人类接触到大量的事物和知识,而建立了“常识”。这些常识可以带领人类做出一些程序无法达到的能力,像是人类可以只看一半的脸就能想像另外一半脸,或是可以从过去的事件推测未来等。
他举例,若人类看到一张战利品放不下行李箱的图片,再看到一个句子说:”这些战利品放不下行李箱,因为它太小了。“人类能够很清楚地知道“它”指的是行李箱,人类也因为知道整个社会和世界运行的规则,当没有太多的信息时,人类可以依照因果关系自动补足空白的信息。










