新智元AI World 2017世界人工智能大会开场视频
中国人工智能资讯智库社交主平台新智元主办的
AI WORLD 2017 世界人工智能大会
11月8日在北京国家会议中心举行,大会以“AI 新万象,中国智能+”为主题,上百位AI领袖作了覆盖技术、学术和产业最前沿的报告和讨论,2000多名业内人士参会。新智元创始人兼CEO杨静在会上发布全球首个AI专家互动资讯平台“新智元V享圈”。
全程回顾新智元AI World 2017世界人工智能大会盛况:
新华网图文回顾
http://www.xinhuanet.com/money/jrzb20171108/index.htm
爱奇艺
上午:
http://www.iqiyi.com/v_19rrdp002w.html
下午:
http://www.iqiyi.com/v_19rrdozo4c.html
阿里云云栖社区
https://yq.aliyun.com/webinar/play/316?spm=5176.8067841.wnnow.14.ZrBcrm
新智元编译
作者:常佩琦 弗格森
【新智元导读】
今天介绍Github上的开源项目,专门用于更新最新的研究突破,具体说来,就是什么算法在哪一个数据集上取得了state-of-the-art 的成果,包括语音、计算机视觉和NLP、迁移学习、强化学习。在这里,你可以读懂2017机器学习领域究竟在哪些方向上取得了突破,各大前沿机构和学术大牛们在哪些方向上发力。比如,Hinton掀起深度学习革命的Capsule 网络、再到谷歌的“一个模型学习所有”“Attention is all you need”以及Facebook在机器翻译上的屡次突破,以及让大家兴奋的AlphaGo Zero等等。

学术领域,最新的机器学习技术都做到了什么水平?Github上有一个开源项目,专门用于更新最新的研究突破,具体说来,就是什么算法在哪一个数据集上取得了state-of-the-art 的成果。大类包括:监督学习、半监督学习和无监督学习、迁移学习、强化学习,小类包括语音、计算机视觉和NLP。
这一份列表几乎囊括了2017年机器学习领域所有最重大的突破,从微软对话语音识别错误率将至5.1%、到Hinton掀起深度学习革命的Capsule 网络、再到谷歌的“一个模型学习所有”“Attention is all you need”以及Facebook在机器翻译上的屡次突破,以及让大家兴奋的AlphaGo Zero。
这不仅仅是一份论文和代码资源的列表,更是2017年机器学习和人工智能里程碑的表单,在这里,你可以读懂2017机器学习领域究竟在哪些方向上取得了突破,各大前沿机构和学术大牛们在哪些方向上发力。
作者说:“本库为所有机器学习问题提供了当前最优结果,并尽最大努力使库保持随时更新状态”,我们也同样期待这一列表不断更新,出现更多让人拍案叫绝的最新研究成果,将人工智能不断往前推进。
最新更新时间:2017年11月17日
本库的分类如下:
1. Speech
2. 计算机视觉
3. NLP
1. Speech
2. 计算机视觉
3. NLP
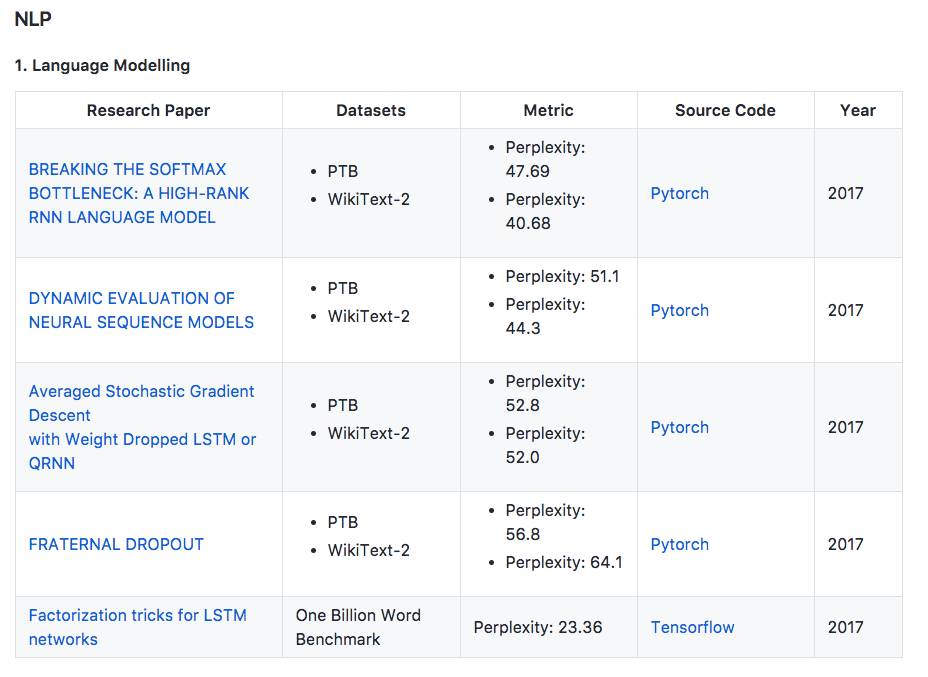
1. 语言建模
地址:https://arxiv.org/pdf/1711.03953.pdf
本文将语言建模作为一个矩阵分解问题,并表明基于Softmax的模型(包括大多数神经语言模型)的表达受到Softmax瓶颈的限制。 鉴于自然语言高度依赖于上下文,这意味着在实践中Softmax与分布式词嵌入没有足够的能力来建模自然语言。 本文提出了一个简单有效的解决方法,并且
将Penn Treebank和WikiText-2中的perplexities分别提高到47.69和40.68
。
地址:https://arxiv.org/pdf/1709.07432.pdf
本文提出使用动态评估来改进神经序列模型的性能。 模型通过基于梯度下降的机制适应最近的历史,将以更高概率分配给重新出现的连续模式。
动态评估将Penn Treebank和WikiText-2数据集上的perplexities分别提高到51.1和44.3
。
地址:https://arxiv.org/pdf/1708.02182.pdf
提出了使用DropConnect作为经常正则化形式的权重下降的LSTM。此外,本文引入NT-ASGD,平均随机梯度方法的变体,其中平均触发是使用非单调条件确定的,而不是由用户调整。使用这些和其他正则化策略,本文在两个数据集上实现了state-of-the-art word level perplexities:Penn Treebank上的57.3和WikiText-2上的65.8。在结合我们提出的模型探索神经缓存的有效性时,在
Penn Treebank上实现了更低的52.8的state-of-the-art word level perplexities,而在WikiText-2上达到了52.0
。
地址:https://arxiv.org/pdf/1711.00066.pdf
提出一个叫做fraternal dropout的技术。首先用不同的dropout mask训练两个同样的RNN,并最小化预测差异。本文评估了提出的模型,
并在Penn Treebank和Wikitext-2上达到了当前最优结果
。
地址:https://arxiv.org/pdf/1703.10722.pdf
提出了两个带映射的LSTM修正单元,来减少参数数量和加快训练速度。
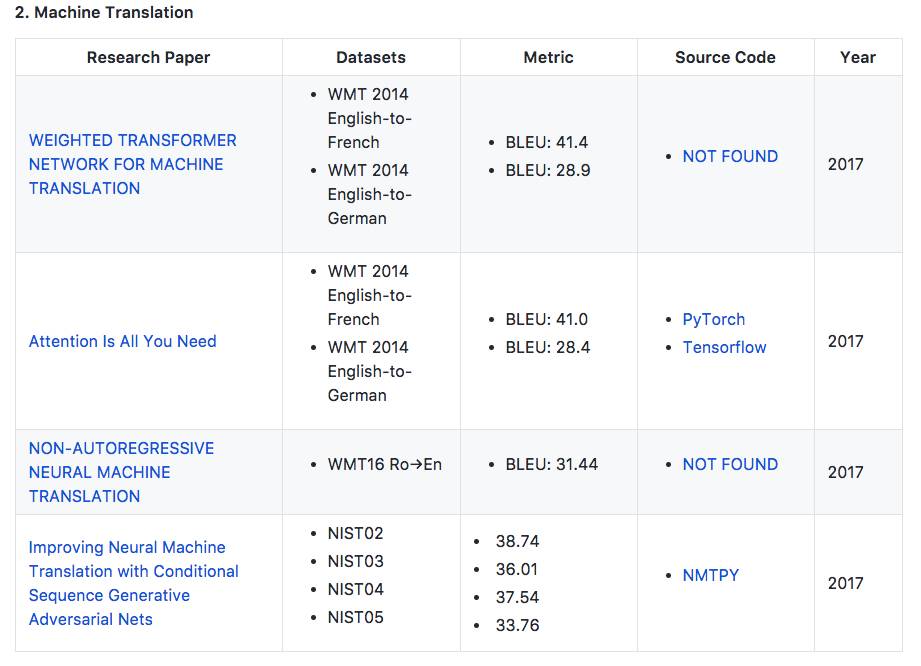
2. 机器翻译
地址:https://arxiv.org/pdf/1711.02132.pdf
在WMT 2014英德翻译任务和英法翻译任务中,模型的性能分别提高了0.5 BLEU points和0.4
。
地址:https://arxiv.org/abs/1706.03762
在WMT 2014英德翻译任务和英法翻译任务中,模型的性能分别提高到28.4 BLEU points和41.0 BLEU points
。










