关于好的架构是设计而来还是进化而来的争论,架构师们众说纷纭莫衷一是。本篇文章的目的不在于得出一个普世性的结论,而在于通过两种截然相反的观点,给大家带来一些启发,引出一些讨论。读完全文后,请给我一个你的答案。 作者:杨波,LVMH集团中国区首席架构师
大概在7~8年前,我曾经有一个美国对口的架构师导师,他对我讲架构其实是发现利益相关者(stakeholder),然后解决他们的关注点(concerns),后来我读到一本书《软件系统架构:使用视点和视角与利益相关者合作》,里面提到的理念也是这样说:系统架构的目标是解决利益相关者的关注点。
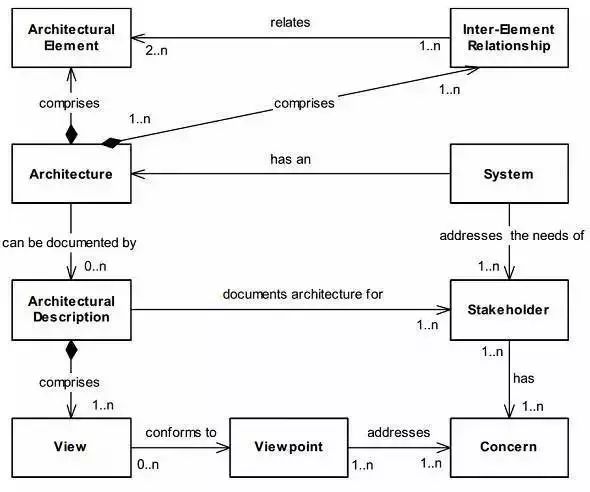
这是从那本书里头的一张截图,我之前公司分享架构定义常常用这张图,架构是这样定义的:
每个系统都有一个架构
架构由架构元素以及相互之间的关系构成
系统是为了满足利益相关者(stakeholder)的需求而构建的
利益相关者都有自己的关注点(concerns)
架构由架构文档描述
架构文档描述了一系列的架构视角
每个视角都解决并且对应到利益相关者的关注点。
架构系统前,架构师的首要任务是尽最大可能找出所有利益相关者,业务方,产品经理,客户/用户,开发经理,工程师,项目经理,测试人员,运维人员,产品运营人员等等都有可能是利益相关者,架构师要充分和利益相关者沟通,深入理解他们的关注点和痛点,并出架构解决这些关注点。
架构师常犯错误是漏掉重要的利益相关者,沟通不充分,都会造成架构有欠缺,不能满足利益相关者的需求。利益相关者的关注点是有可能冲突的,比如管理层(可管理性)vs技术方(性能),业务方(多快好省)vs 技术方(可靠稳定),这需要架构师去灵活平衡,如何平衡体现了架构师的水平和价值。
关于架构的第二点定义是说架构主要关注非功能性需求(non-functional requirements),即所谓的-abilities。

这个是我上次公司内分享的一个图。

这个是slideshare一个ppt里头截取的,两个图都是列出了架构的非功能性关注点;关于架构的水平该如何衡量,去年我看到一句话,对我影响很大。
Architecture represents the significant design decisions that shape a system, where significant is measured by cost of change.
翻译为中文就是,架构表示对一个系统的成型起关键作用的设计决策,架构定系统基本就成型了,这里的关键性可以由变化的成本来决定。这句话是Grady Booch说的,他是UML的创始人之一。
进一步展开讲,架构的目标是用于管理复杂性、易变性和不确定性,以确保在长期的系统演化过程中,一部分架构的变化不会对架构的其它部分产生不必要的负面影响。这样做可以确保业务和研发效率的敏捷,让应用的易变部分能够频繁地变化,对应用的其它部分的影响尽可能的小。
我刚入软件开发这个行业之初,谈的架构主要是性能,高可用等等。现在,见过无数遗留系统,特别是国内企业IT的现状,无数高耦合的遗留系统,不良的架构像手铐一样牢牢地限制住业务,升级替换成本非常巨大, 所以我更加关注可理解,可维护性,可扩展性,成本 。我想补充一句,创业公司创业之初获得好的架构师或技术CTO非常重要。
作者:王庆友,前1号店首席架构师
软件是人类活动的虚拟,业务架构是生产活动的体现,应用架构是具体分工合作关系的体现。
单体应用类似原始氏族时代,氏族内部有简单分工,氏族之间没有联系;分布式架构类似封建社会,每个家庭自给自足,家庭之间有少量交换关系;SOA架构类似工业时代,企业提供各种成品服务,我为人人,人人为我,相互依赖。微内核的SOA架构类似后工业时代,有些企业聚焦提供水电煤等基础设施服务,其他企业在之上提供生活服务,依赖有层次。
业务架构是生产力,应用架构是生产关系,技术架构是生产工具。业务架构决定应用架构,应用架构需要适配业务架构,并随着业务架构不断进化,同时应用架构依托技术架构最终落地。
企业一开始业务比较简单,比如进销存,此时面向内部用户,提供简单的信息管理系统(MIS),支持数据增删改查即可,单体应用可以满足要求。
随着业务深入,进销存每块业务都变复杂,同时新增客户关系管理,以更好支持营销,业务的深度和广度都增加,这时需要对系统按照业务拆分,变成一个分布式系统。
更进一步,企业转向互联网+战略,拓展在线交易,线上系统和内部系统业务类似,没必要重做一套,此时把内部系统的逻辑做服务化改造,同时供线上线下系统使用,变成一个简单的SOA架构。
紧接着业务模式越来越复杂,订单、商品、库存、价格每块玩法都很深入,比如价格区分会员等级,访问渠道(无线还是PC),销售方式(团购还是普通)等,还有大量的价格促销,这些规则很复杂,容易相互冲突,需要把分散到各个业务的价格逻辑进行统一管理,以基础价格服务的方式透明地提供给上层应用,变成一个微内核的SOA架构。
同时不管是企业内部用户,还是外部顾客所需要的功能,都由很多细分的应用提供支持,需要提供portal,集成相关应用,为不同用户提供统一视图,顶层变成一个AOA的架构(application orientated architecture)。
随着业务和系统不断进化,最后一个比较完善的大型互联网应用架构如下图所示:
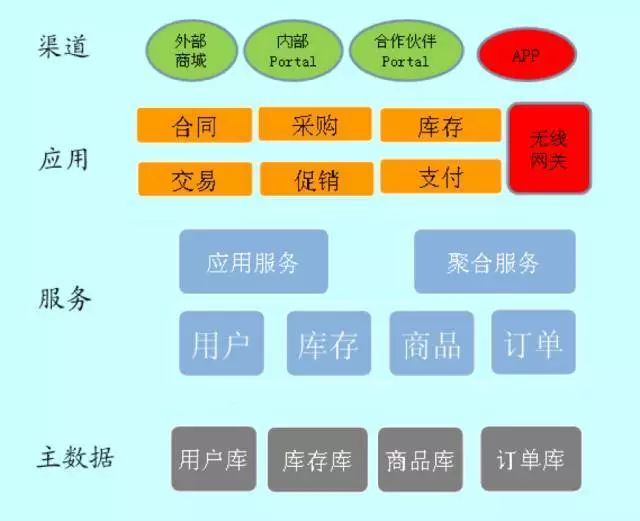
最终整个系统化整为零,形神兼备,支持积木式拼装,支持开发敏捷和业务敏捷。应用架构,需要站在业务和技术中间,在正确的时间点做正确的架构选择,保证系统有序进化。
以58同城的架构演进为例
作者:沈剑,58到家技术委员会主席
对很多创业公司而言,在初期的时候,我们很难在初期就预估到流量十倍以后、百倍以后、一千倍以后网站的架构会变成什么样。当然,如果在最初的时期,就设计一个千万级并发的流量架构,那样的话,成本是也是非常之高的,估计很难有公司会这样做。所以,我们主要来讲架构是如何进行演化的。我们在每个阶段,找到对应该阶段网站架构所面临的问题,然后在不断解决这些问题的过程中,整个战略的架构就是在不断的演进了。
其实,在 58 同城建立之初,站点的流量非常小,可能也就是是十万级别,这也就意味着,平均每秒钟也就是几次的访问。此时网站架构的特点:请求量是比较低,数据量比较小,代码量也比较小。可能找几个工程师,很容易就做一个这样的站点,根本没什么「架构」可言。
这也是很多创业公司初期面临的问题,最开始58同城的站点架构用一个词概括就是「ALL IN ONE」,如下图所示:
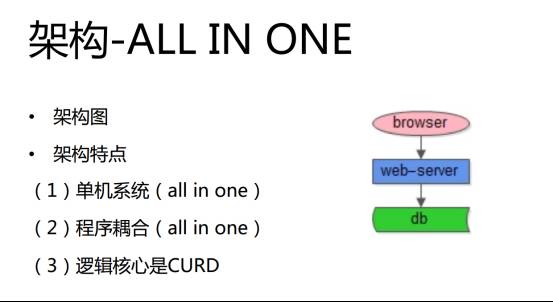
就像一个单机系统,所有的东西都部署在一台机器上,包括站点、数据库、文件等等。而工程师每天的核心工作就是 CURD,前端传过来一些数据,然后业务逻辑层拼装成一些 CURD 访问数据库,数据库返回数据,数据拼装成页面,最终返回到浏览器。相信很多创业团队,初期做的工作也是类似,每天写代码,写 SQL、接口参数、访问数据等等。
这里需要说明一个问题,大家都知道目前 58 同城使用的是 Windows、iis、SQL-Sever、C# 这条路。现在很多创业公司可能就不会这么做。58 同城为什么当时选择了这条路?原因是公司招聘的第一个工程师和第二个工程师只会这个,所以只能走这条路。
很多创业的同学可能会想,如果我们初期希望做一个产品的话,我们应该使用什么架构? 如果让我们重来,可能我们现在会选 LAMP,为什么?首先是无须编译,而且快速发布功能强大,从前端到后端、数据库访问、业务逻辑处理等等全部可以搞定,最重要的是因为开源产品,是完全免费的。如果使用 LAMP 搭建一个论坛,两天的时间就很足够了。所以,如果在创业初期,就尽量不要再使用 Windows 的技术体系了。
随着 58 同城的高速增长,我们很快跨越了十万流量的阶段。主要需求是什么?网站能够正常访问,当然速度更快点就好了。而此时系统面临问题包括:在流量的高峰期容易宕机,因为大量的请求会压到数据库上,所以数据库成为新的瓶颈,而且人多的时候,访问速度会很慢。这时,我们的机器数量也从一台变成了多台。现在的架构就采用了分布式,如下图所示:
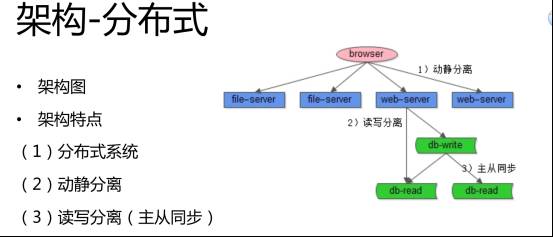
首先,我们使用了一些非常常见的技术,一方面是动静分离,动态的页面通过 Web-Servre 访问,静态的像图片等就单独放到了一些服务器上。另外一点就是读写分离。其实,对 58 同城或者说绝大部分的站点而言,一般来说都是读多写少。对 58 同城来说,绝大部分用户是访问信息,只有很少的用户过来发贴。那么如何扩展整个站点架构的读请求呢?常用的是主从同步,读写分离。我们原来只有一个数据库,现在使用多个不同的数据库提供服务,这样的话,就扩展了读写,很快就解决了中等规模下数据访问的问题。
大流量:将整个 Windows 技术体系转向了 Java 体系 流量越来越大,当流量超过一千多万时,58 同城面对最大的问题就是性能和成本。此前,我提到58同城最初的技术选型是 Windows,应该是在 2006 年的时候,整个网站的性能变得非常之低。即使进行了业务拆分和一些优化,但是依然解决不了这个问题,所以我们当时做了一个非常艰难的决定,就是转型:将整个 Windows 技术体系转向了 Java 体系,这涵盖了操作系统、数据库等多个维度。

其实,现在很多大的互联网公司在流量从小到大的过程中都经历过转型,包括京东、淘宝等等。对技术的要求越来越高,任何一个站点都不能挂,对站点的可用性要求也是越来越高。
如何提供整个架构的可用性?首先,在上层我们进行了一些改进和优化,再做进一步的垂直拆分,同时我们引入了 Cache,如下图所示:
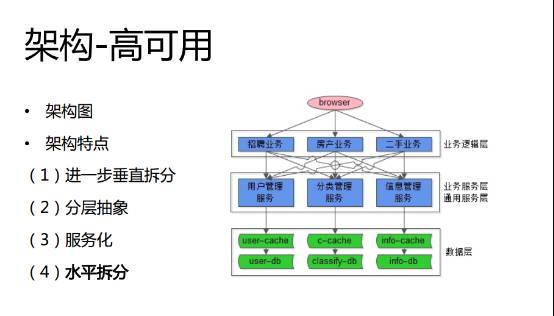
随着用户量、数据量并发量进一步的增长,58同城也拓展了很多的新业务,那么对产品迭代速度要求就非常高,整体的架构对自动化的要求越来越高。

为了支撑业务的发展,技术团队对架构做了进一步的解耦,另外就是引入了配置中心。另一点就是关于数据库,当某一点成为一个业务线重点的时候,我们就会集中解决这个点的问题。最后一点就是效率矛盾,此时很多问题,靠「人肉」已经很难进行搞定了。这就需要自动化,包括回归、测试、运维、监控等等都要回归到自动化。
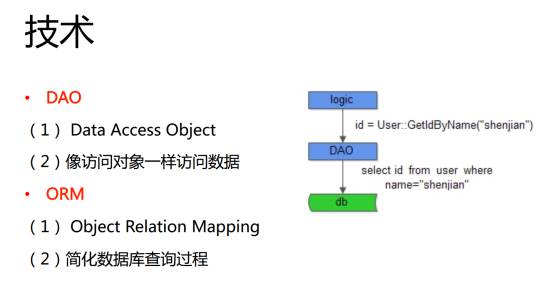
网站在不同的阶段遇到的问题不一样,而解决这些问题使用的技术也不一样,流量小的时候,我们主要目的是提高开发效率,在早期要引入 ORM,DAO 这些技术。随着流量变大,使用动静分离、读写分离、主从同步、垂直拆分、CDN、MVC 等方式不断提升网站的稳定性。面对更大的流量时,通过垂直拆分、服务化、反向代理、开发框架(站点/服务)等等,不断提升高可用。在面对上亿级的更大流量时,通过中心化、柔性服务、消息总线、自动化(回归,测试,运维,监控)来迎接新的挑战。未来的就是继续实现 移动化,大数据实时计算,平台化…
4 观点2:好的架构需要精心设计,千万别把问题留给进化 以Google的经验为例
作者:郄小虎(Tiger),前Google全球研发总监
我认为好的架构,都需要经过这么几个过程:设计 – 进化 – 进化 …… – 被推翻 – 再设计,是这样循环往复的过程。最开始的架构,肯定是从无到有,根据产品的需求和当时业务的需求设计出来的。
我觉得,一个系统的演化,一般会经过这样的阶段:第一个系统肯定是under-engineer的,从无到有被设计出来后,肯定是不完善的;第二个版本,一般是over-engineer的,因为随着之前那个版本的使用,积累了一定量需求后,会发现想要增加很多内容在上面;到第三个版本,应该是最恰当的,减去了一些没必要的设计之后,更合适。但当到了某一个时间点,发现现有的系统架构已经没有办法再维持下去,跟不上需求增长时,就需要推倒再重新设计。
拿谷歌的广告系统来说,我03年加入了Google,当时的架构还是比较简单的,只分为两层,web serving层和存储层。所有的数据都存在MySInfoQL里,前端的web server会把用户搜索的关键词转化成一个数据库的query,然后把所有的查询结果做聚合和排序。
但很快就遇到了问题。我们有两个customer,一个是eBay、一个是Amazon,他们什么关键词都买,所以他们一家就要占用一个独立的数据库,他们的量还不断往上涨 当时的解决方案呢,就是多做一层分离,把存储数据和需要响应在线搜索的数据通过分开,增加一层cache server。
后来很快用customer做分片也不足够了。我们就转为了用keyword的fingerprint做shard key,从增长最快的数据着手解决。其他还做了的包括异地容灾,多套primary数据中心同时运行等等,都是后来的升级了。架构的演进,一般是这样一个周而复始的循环过程。
Google AdWords 经历的重大调整和优化 除了上面提到的,还有过一次升级,大概是在04年到05年之间。这一次在结构上有更加根本的改变,主要是考虑了geographical的redundancy。因为那时候赚的钱已经很多了,服务一旦down掉后果是非常严重的。虽然我们是从数据存储上有很多replica,但是primary还是很容易down掉的。我们后来就建了两套primary,在primary的更新会被push到其他所有的replica datacenter去。
一旦某一个primary DC出了问题,比如地震之类的,我们可以很快switch到另一个DC去,正常情况下两套系统会同时运行。我们的每个replica datacenter也会有两套不同的stream,data也分别来自于不同的primary。这两套stream是完全独立的,一旦一个stream出现问题,可以很快的switch上另一个stream上去。
当时也没有成熟的Auto failover的机制。当时能买到的就是Oracle,但是没办法scale到那种程度的 。理论好像有了很多年了,但是真正在实践中一个在很多Master中投票,选出winner的算法也是没有的。这个也是Google当时才实现出来的。其实还有很多底层问题,也有一些比较有意思的事情。
比如说当你有五十个datacenter的时候,你怎么把data push过去,也是一个挺大的问题,因为数据量很大。当时我们也没有用现成的solution,也没有任何的现成的solution可以用,我们就自己研究了一套。说白了它就是一个pub-sub或者说是一个multi-cast的问题吧。
一开始的时候,data push的latency是用小时来计算的,就有人利用了这个延时长的缺陷刷了很多广告的impressions。因为我们的replica DC需要几个小时才能知道某个customer的预算已经用完了。后来经过了一系列的优化,我们才把跨DC的latency做到了分钟级别,如果是同一个DC,那就是秒级别了。
我觉得没有一种general purpose solution是可以拿过来就能用的。尤其在Google我们当时很清楚地意识到我们将会面临的挑战是其他人都没有遇到过的,而且用那样的方式一定是行不通的。但是,Google的经验确实可以帮助把握好大的技术方向。
比如说,从一个rule-based的推荐系统切换成一个model-based的系统,一定会有一个比较大的提升。之后的算法还可以优化,也会带来提升,但可能很难再超越之前的提升幅度。具体的算法实现、优化就得靠团队里的这群年轻人了。
作为技术领导者,技术、管理之外,还需要什么?业务、产品、心理、商业、资本……陌生的领域、全新的知识体系,带来全新的挑战与探索的激情。2017年7月,GTLC全球技术领导力峰会将在上海举办,并将以“探索圆外的世界”为主题,与参会CTO们一起探寻技术之外,更广袤的未知世界。点击 「 阅读原文 」了解更多详情,聆听更多技术领导力实践,与更多CTO交流碰撞!

今日荐文
点击下方图片即可阅读











