作者:
Alon Brody,数据分析与数据仓库平台panoply.io的资深数据系统架构师。
译者:
白云鹏
Spark并非完美无瑕,目前发展到了什么程度呢?我们来一起看看Spark的优劣之处吧。
可以读一读
Panopoly
带来的
The Evolution of the Data Warehouse
,也就是目前这些系统所面临的主要挑战。
如果你要寻求一种处理海量数据的解决方案,就会有很多可选项。选择哪一种取决于具体的用例和要对数据进行何种操作,可以从很多种数据处理框架中进行遴选。例如Apache的Samza、Storm和Spark等等。本文将重点介绍Spark的功能,Spark不但非常适合用来对数据进行批处理,也非常适合对时实的流数据进行处理。
Spark目前已经非常成熟,数据处理工具包可以对大体量数据集进行处理,不必担心底层架构。工具包可以进行数据采集、查询、处理,还可以进行机器学习,进而构建出分布式系统的数据抽象模型。
处理速度也是Spark的亮点,MapReduce在处理过程中将数据放到内存中,而不放在磁盘上进行持久化,这种改进使得Spark的处理速度获得了提升。Spark提供了三种语言环境下的类库,即Scala、Java和Python语言。
除了上述这些优点之外,Spark自身也存在一些问题。例如,部署过程过于复杂,可扩展性差。本文对此也会进行论述。
Spark的功能架构模型
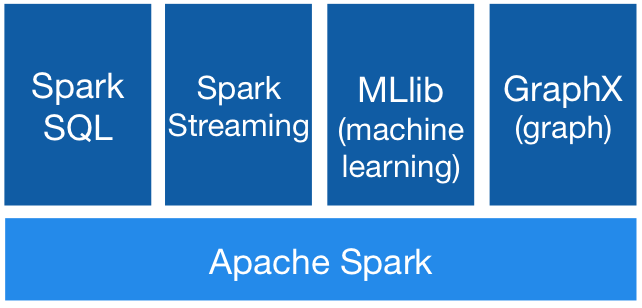
图片源自
http://spark.apache.org/
上图显示了Spark所包含的不同功能模块。虽然这些模块的主要功能是处理流式数据,但还包括一些帮助执行各种数据操作的组件。
-
Spark SQL:Spark自带SQL接口,也就是说,可以使用SQL语句进行数据查询。查询操作会被Spark的执行引擎执行。
-
Spark Streaming:该模块提供了一组API,用来在编写应用程序的时候调用,执行对时实数据流的处理操作。该模块将进入的数据流拆分成微型批处理流,让应用程序进行处理。
-
MLib:该模块提供了在海量数据集上运行机器学习算法的一组API。
-
GraphX:当处理由多个节点组成的图类型数据时,GraphX模块就派上用场了,主要的突出之处在于图形计算的内置算法。
除了用来对数据进行处理的类库之外,Spark还带有一个web图形用户接口。当运行Spark的应用时,通过4040端口会启动一个web界面,用来显示任务执行情况的统计数据和详细信息。我们还可以察看一个阶段任务执行的时间。如果想要获得最佳的性能,这样的信息是非常有帮助的。
用例
数据分析
——对进入的数据流作实时分析是Spark很在行的事情。Spark能够高效处理来自各式各样数据源的大量数据,支持HDFS、Kafka、Flume、Twitter和ZeroMQ,也能对自定义的数据源进行处理。
趋势数据
——Spark能够用来对进入的事件流进行处理,用于计算趋势数据。找到某个时间窗口的趋势,对于Spark来说变得异常简单。





