【时长14'07'',建议在WiFi条件下观看视频】
本视频出自
2016万有青年大烩

大家可以花一秒钟想一下。
我认为区别在于
操作
的能力。举个例子,Siri,是一个很聪明的电脑,它可以跟你对话,但它不能拿东西,它没有办法去没有操作任何现实世界的物品。

但一提起哆啦A梦,你会觉得它是一个机器人。

大家仔细观察哆啦A梦是怎么拿东西的?你会发现
它会伸出一个小手指
。

不记得是2011年还是2010年,PNAS曾发表一篇论文,由芝加哥大学、康奈尔大学几个研究组一起合作,研究出了一个现实版的哆啦A梦的手。

这边就是当时论文里面得不同的配图,有它的结构,有它的原理,有它对不同物体识别的方式,以及最后测评的一个效果。
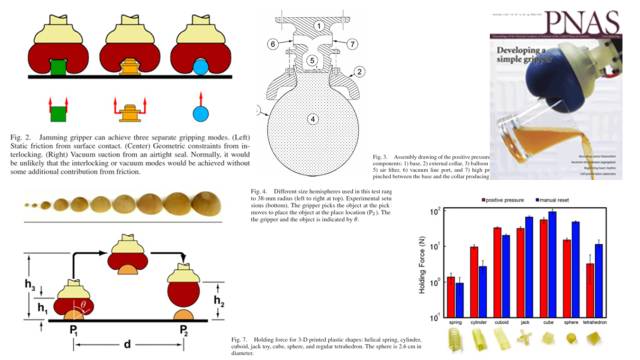
这个东西有几种不同的实现,它的原理非常简单。下图中,最左边就是我在2011年的时候自己实现的,我当时在一个气球里面装满了大米,然后拿一个吸尘器吸,其实当时直接用嘴吸都可以达到这个效果。
中间是南洋理工的一群人自己在网上做的,大家在网上可以搜到。右边那个是正式拿了发明者的授权成立了商业公司做成的产品,是一个商业级别的真正的gripper(抓手)。

Manipulation(操控)主要分成三个部分,这也是机器人做任何具体的动作,做任何具体的事情要经过的三个步骤,分别是
感知、规划和操作或者是运动
。这可以认为是我这5年来干的事情。
我们做了一个通用机器人,它的实现形式是一个移动的操作臂,也就是机械臂,叫做mobile manipulator。下面这个是在我们办公室里面,机械臂自己导航到仓库,看盒子里面有什么东西,去判断盒子里东西的位置、姿态是什么样子的示例。
机器人从底座的移动到机械臂的移动,到如何实现对物品的识别,到抓取,到避开,都是完全自动的,没有任何的人工帮助。这本身也是两台机器人配合的一个过程。

先讲第一个感知的部分。感知就是
要描述你周围的世界,你周围的环境是什么样子的
。这是借用现在最火的自动驾驶的图,自动驾驶其中很重要的能力就是感知。

这张图显示的是recognition的部分,它可以识别一个图片里有什么东西,大概在哪个方位。这也是传统的CV里做的最多的一点。

这张是segmentation,就是把图片做一个分割,比如把人全部染成绿色,道路全部染成紫色,识别出来标志信号是黄色的。把画面里这些不同的功能加以区别,这样一来机器人就可以进行下一步的动作。
而我们目前集中力量做的,也是做真正有操作能力的机器人需要攻克的难点,是
pose estimation,也就是判断一个物品的姿态。
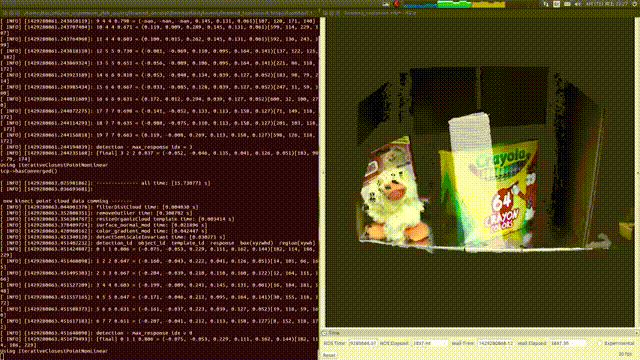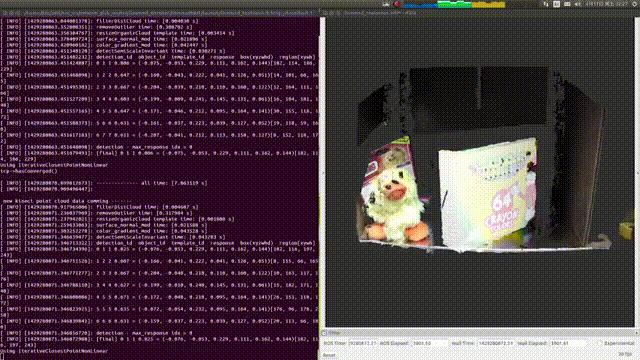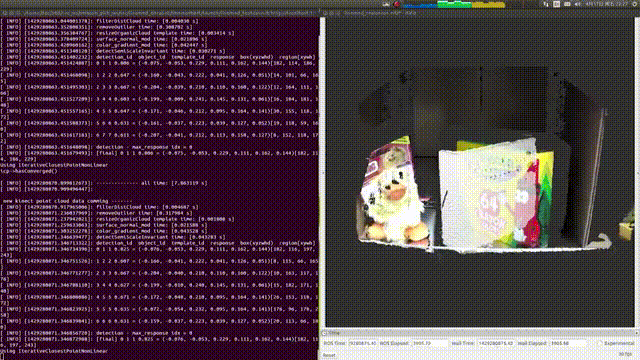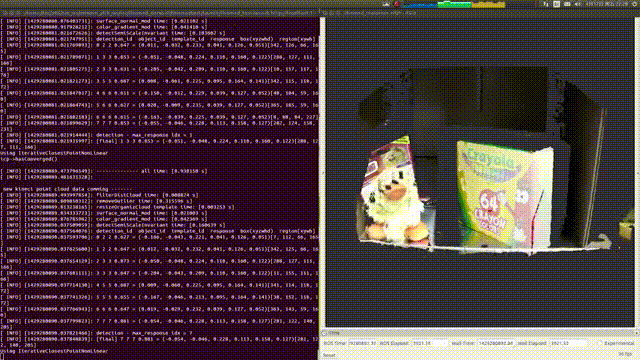
大家可以看到,右面图里有个白色的区域,这是系统识别零食盒的一个模板,当零食盒被转动之后,系统能够重新识别出它再画面里具体哪个位置,通过重新计算之后白色的区域又再次准确识别了零食盒的方位,更重要的是
它朝着什么方向
。
那么感知还有其他的方式,比如说
触觉
。

这是基于
电子
的触觉传感器的原理图。

这是基于
光学
的触觉传感器的一个原理图。

这个
触觉传感器
非常非常昂贵,大概是15000美金一支。它是基于
流体内部的定位、电压区别
,做的一个触觉的传感器。

在所有的这些事情里面,科学的部分和工程的部分,其实并不是泾渭分明的,但是大家可以看到哪些部分属于科学,比如说光学、比如说电的基本原理,电阻是怎么工作的,电路本身是怎么工作的,比如说在做视觉识别的时候,怎么做模式识别,怎么用神经网络判断什么东西是什么,在什么地方,这都是属于科学研究的部分,特别是像计算机里面相关的内容,都是属于我们叫做形式科学的部分。
那么工程部分则涉及到,比如说视觉这件事情,就涉及到你如何去组视觉的服务器,你如何选镜头,你如何搭建后面的算法,你在算法实现成代码的时候,你如何取组织代码,包括传感器你如何去选材料,如何去制作,这就是工程的部分。
在sense-plan-act大图里面的第二块,也是最主要的一块,是Motion Planning,或者叫运动规划,就是解决
如何从A点移动到B点,不碰到周围的障碍物
的问题。这是我们刚才视频里面有展示的图,就是机器人做运动规划的一个图。

大家可以仔细看有一个虚幻的机械臂的动作,就是它在计算运动规划的过程,可是这个臂的运动太快了,它一直在追那个规划,追自己的幻影。

运动规划讲起来是一个比较大的复杂的话题,简单说明一下。

假如这个画面上绿色的三角形是一个机器人,右上角的圆点
是机器人的参照坐标,中间那个大的蓝色部分是一个方形的障碍物。对于这个机器人来说,实际上是有三个不同的参数可以用来描述它的完整状态——X、Y的坐标,以及它的旋转方向。
在这个情况下,我假设它的旋转方向是不变的,也就是XY两个参数就可以描述这个机器人的一个完整的状态。
假如说我
以坐标蓝点作为一个参照点的话,这个机器人能够到达,或者说它的参考坐标点能够到达的那个区域就是红线以外的区域
。这是一个很重要的概念,后面所有的东西都是以这个基础的。

再假设,这个三角形的机器人本身发生了形变。左边是机器人的工作空间,右边是它的配置空间(configuration space)。在工作空间里,机器人完整的形体由蓝色三角形来描述;
在配置空间里面,机器人的状态由一个小绿点来描述。
当机器人本身的形状变化的时候,虽然障碍物没变,但是机器人在配置空间里能够达到的位置是一直在变化的
。

刚才谈论的是一个二维的情况,这是一个三维的情况。大家可以看到右边的平面里面的小三角形机器人,如果它拥有旋转的能力,它的状态空间就会形成这样的三维的形状,看起来就会非常非常的复杂。
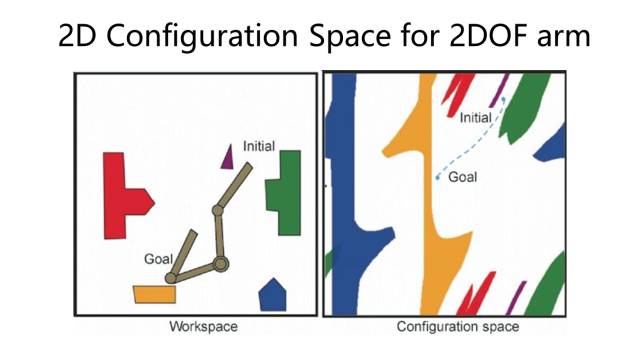
左边是一个在二维空间里面的机械臂,右边是它对应的configuration space。

这个是在motion panning里面最经典的两个算法,左边这个叫
Dijkstra
,右边这个叫
A*
。A*的算法是给一个机器人寻找最优路径的一个算法,它可以更快的去搜索到最后的结果,白色的部分就是机器人已经经过的搜索过的空间,很明显A*比Dijkstra要快很多。
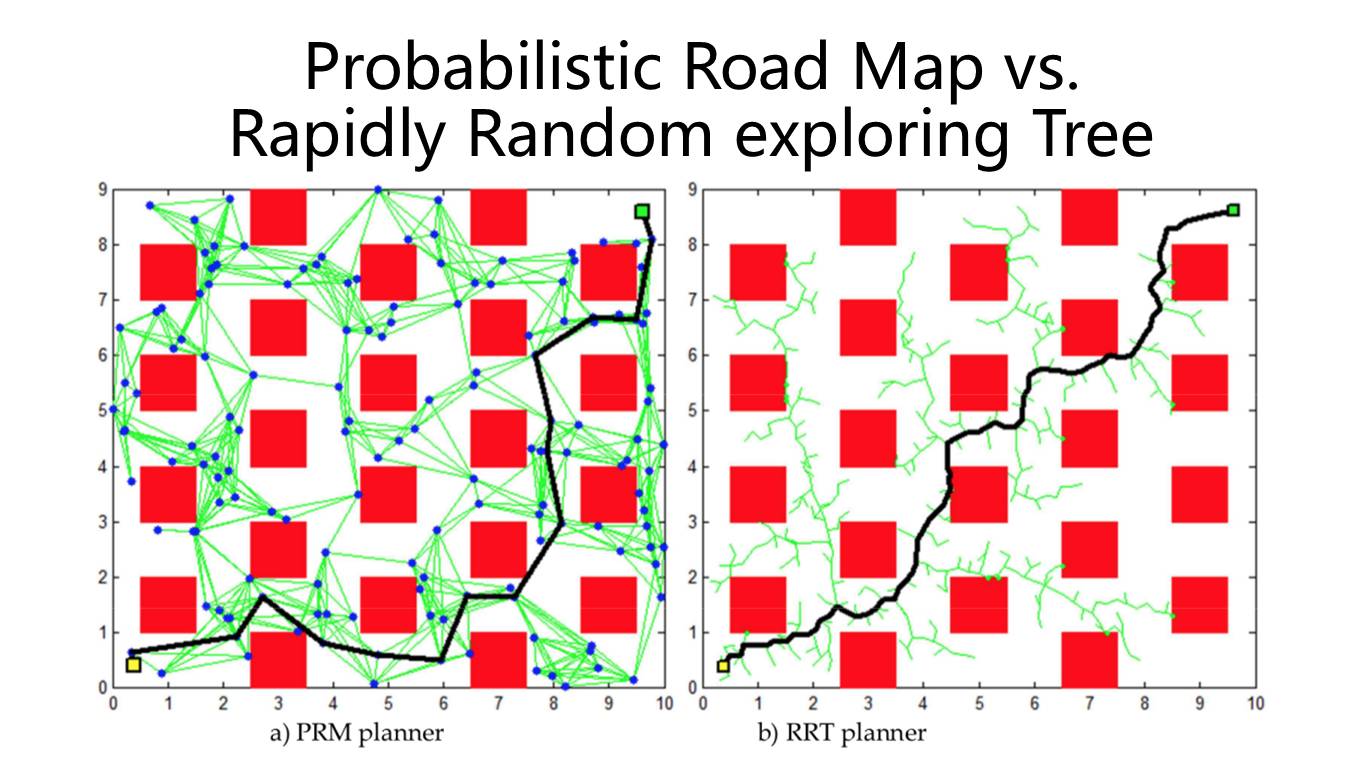
这是motion panning里面其他的比较流行的算法。左边是
PRM(Problistic Road Map)
,红色的是障碍物,绿色的是提前算好一些的连接,黑色是最后算出来那条轨迹。
右边这个叫做
Rapid Random Exploring Tree
,这是现在最常用的,也是最实用的算法——怎么在空间里面从起点到终点拉一条线。
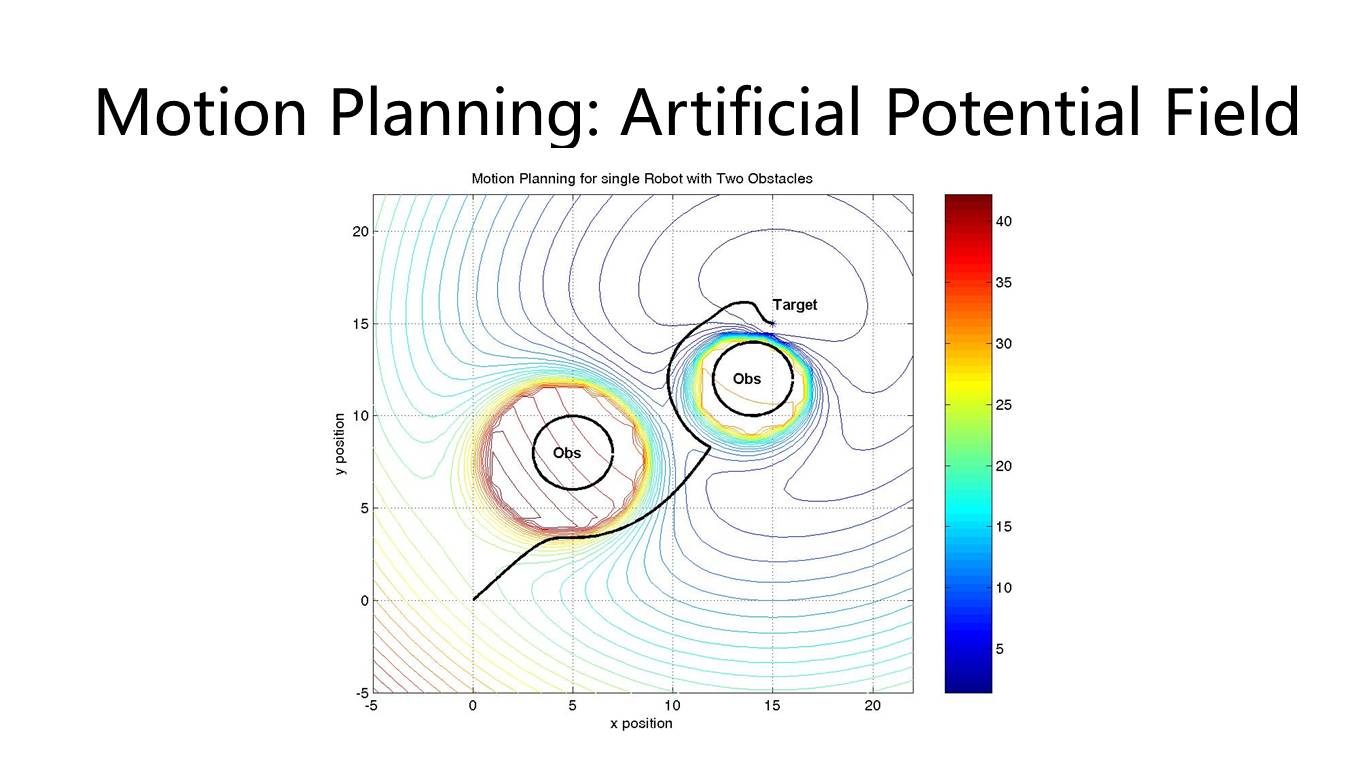
这个也是比较常用的一个算法,叫做
人工势长法
。
上面讲的是二维的状态空间、三维的状态空间,其实真正的机器人的状态空间自由度非常高,维度也非常高。

这个图左边是我们的机器人,我们叫Dorabot Picker,它有10个自由度,底盘有前后移动、左右移动,旋转和升降共4个自由度,机械臂有6个自由度,加起来就是10个自由度。如果再算上手指的6个自由度,那总共就是16个自由度。
右边是NASA的机器人叫做Valkyrie,NASA的humanoid机器人是类人机器人,这个机器人全身上下能动的关节一共32个,也就是说不管是左边的机器人还是右边的机器人,如果要运动的话都必须要在非常高维的空间里做好规划才能实现。

而grasp planning则是解决机器人怎么去抓取一个物体的问题。

这个是基于simulator的,基于模拟器的一个grasp plan。











