「机器人圈」导览:关于高分辨率音频的炫酷想必大家都清楚,那么管如何构建呢?物理博士Jeffrey Hetherly在受到深度学习成功应用于图像超分辨率的启发后,开始使用深度神经网络在这一领域探索,下面就和机器人圈一起来学习一下吧。
音频超分辨率旨在重建一个以较低分辨率波形作为输入的高分辨率音频波形。在诸如流式音频和音频恢复之类的领域中,这种类型的上采样存在着若干种潜在应用。一个传统的解决方案是使用音频剪辑的数据库,凭借相似性指标来填充下采样波形中的缺失频率(见
本文
和
本文
)。由于受到深度学习成功应用于
图像超分辨率
的启发,我最近致力于使用深层神经网络来完成原始音频波形的上采样。在制定了几种方法之后,我把注意力主要集中于实施和自定义最近将发表于2017年国际学习代表会议(ICLR)上的
研究论文
。

虽然音频上采样在大量的领域中都可能是有用的,但我只专注于潜在的IP语音应用程序。我为这个项目选择的数据集是一个TED演讲的集合,大小大约为35 GB。每个讲话都位于一个单独的文件中,比特率为16千比特每秒(kbps),这被认为是高质量的语音音频。这个数据集主要包含一些非常精彩的英语演讲,而这是从大量演讲者在面对不同观众的演讲中挑选出来的。这些TED演讲的质量与人们在IP语音对话期间所期望的值近似。

预处理步骤如上图所示。每个文件的第一个和最后30秒被修剪以便删除TED演讲的开始和结束部分。然后将文件拆分为2秒的剪辑,并以4 kbps的速率创建一个独立的,4x下采样的剪辑集合以及一组原始速率为16 kbps的集合。60%的数据集用于训练,20%用于验证,20%用于测试。

上图中列出的训练工作流程使用数据预处理步骤中的下采样片段,并将其批量馈入模型(深层神经网络)以更新其权重。具有最低验证分数的模型(表示为“最佳模型”)被保存以供接下来使用。

在上图中给出了使用“最佳模型”对音频文件进行上采样的过程。该工作流采用整个音频文件,与预处理步骤类似地将其拼接到剪辑中,将它们依次馈送到经过训练后的模型中,将高分辨率剪辑缝合在一起,并将高分辨率文件保存到磁盘中。
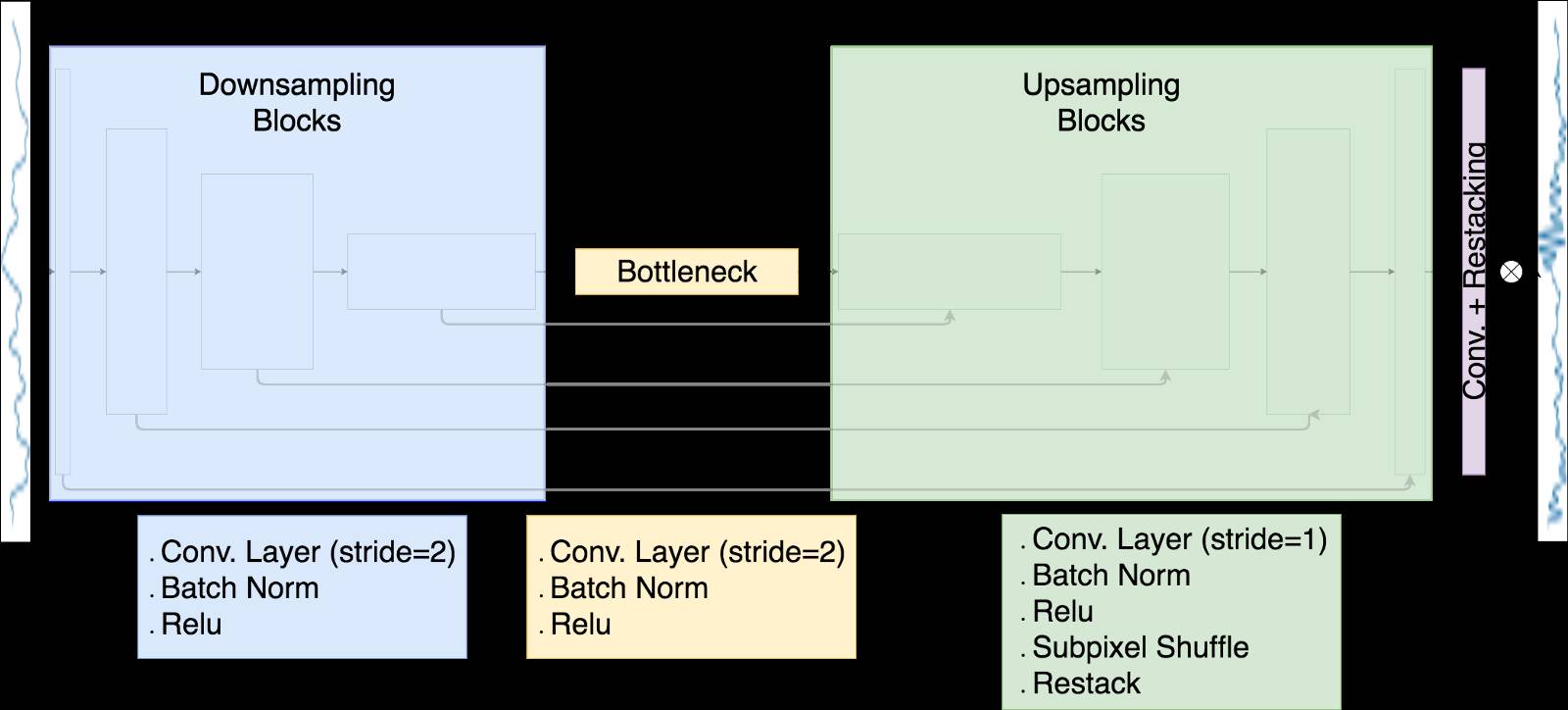
我所实现的模型架构是
U-Net
,它使用的是
子像素卷积
的一维模拟而不是反卷积层。我使用Tensorflow的Python API构建和训练模型,同时使用Tensorflow的C ++ API实现子像素卷积层。该模型的工作原理如下:
下采样波形通过八个下采样块发送,每个采样块都由步幅为2的卷积层组成。在每个层上,滤波器组的数量加倍,使得沿着波形的维度减小了一半,滤波器组的尺寸增加了两个。
该瓶颈层被构造成与下采样块相同,这个下采样块与8个上采样块相连,而这些块与下行采样块是有残留连接的。这些残留连接允许共享从低分辨率波形学习到的特征。
上采样块使用子像素卷积,其沿着一个维度重新排列信息以扩展其他维度。
在原始输入中添加了具有重新排列和重新排序操作的最终卷积层,以便产生上采样波形。
所使用的损耗函数是输出波形与原始高分辨率波形之间的均方差。





