苦等四个月,周杰伦最新单曲《不爱我就拉倒》终于发布!英伦摇滚曲风诠释忧郁情歌,一贯的周氏风格旋律十分抓耳,但看到歌词,处座就坐不住了……
离开之前 不要爱的抱抱
反正 我又不是没有人要
哥练的胸肌
如果你还想靠....
——《不爱我就拉倒》
这是什么土味情歌?处座一秒出戏,不仅忧郁不起来,甚至有点想笑,十级伦吹也不能夸这首歌歌词写得好。处座不禁陷入了沉思:周董是参加了最近流行的土味情话训练班么?

还是说狂吸奶茶的幸福中年人只能写出这样的水平?

其实周杰伦对自己的作词水平是很有自信的,还曾经在歌里cue方文山:
文山啊等你写完词
我都出下张专辑喽
没关系慢慢来
这首歌我自己来
——《梯田》
真的想说,周董,爱惜下自己的羽毛吧,写词这种事还是交给方文山比较好啊!你看看求生欲强烈的歌迷是如何踊跃地在方文山微博评论里留言,甚至愿意众筹给杰伦写词。
其中有一条评论脱颖而出,吸引了处座的目光——

WHAT?方文山已经这么久没写词了么?
带着疑问,处座查了下方文山最近的行程。最近一两年,方文山不仅参加了各类综艺,还在在网络平台开课讲《方文山的音乐诗词课》,从去年到现在,更是在台湾、香港、深圳、以及美国波士顿等多地做了“填词创作”的线下演讲。
但在行程满满的情况下,方文山还是联手吴梦奇给王俊凯写了《我在诛仙逍遥涧》,而去年年底,他联手张亚东给张艺兴写了《梦想起飞》。
这样看来,方文山不是690天没有写词,而是690天没有给周杰伦写词啊,怪不得周·小公举·杰伦要写出《不爱我就拉倒》了。
两人的下次合作不知要等到什么时候,众筹也不知是否会开启,如果周董下首歌还是这种风格,处座真的要苦涩地昏过去了。但是请不来方文山,就写不出方文山风格的歌词了么?凭借专业的敏锐觉察,处座不由得想到,如果开发一个“填词机器人”,能不能成为“方文山第二
”
,说不定就可以把歌词卖给周杰伦呢!
模仿方文山的重点在于,能否让机器人通过阅读方文山写的歌词,学习他歌词的结构和表达形式,最终实现歌词创作。
这里,处座打算利用TensorFlow创建LSTM RNN模型来训练写作机器人。
RNN(循环神经网络)和传统神经网络相比,优势在于允许信息的持久化,这意味着RNN可以利用学习到的知识来推断后续的事件,也使得通过学习歌词,积累歌词经验来创作歌词成为可能。
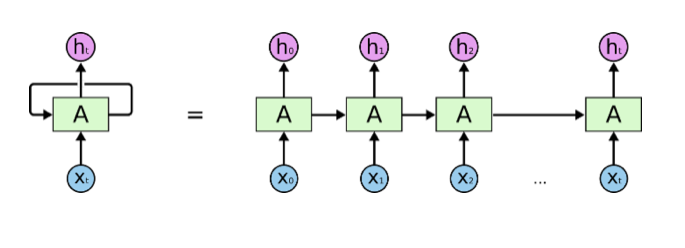
(上图中,A是神经网络的模块,通过读取x_i和上一步循环中A的信息,输出h_i,并将A传递给下一步循环)
LSTM(Long Short Term)则是一种特殊的RNN类型,通过刻意的设计来避免RNN中存在的长期依赖问题。
简单解释一下两者的区别:如果把RNN理解为大脑,原生RNN就是金鱼的大脑,只能保留短期的记忆,对越久远的知识记忆力越弱,如果用来训练写歌词,很可能造成训练了大量的样本,但仍然写不出通顺短语的尴尬情况。而LSTM则像是给了金鱼一个小日记本,将学习到的每个知识都记录在日记本里,这样就算很久远的信息,金鱼也能通过快速翻阅日记本来记住之前的知识,并运用到下一句歌词的写作中。
想要再现方文山和周杰伦的经典合作,首先处座打算要过滤掉周杰伦自己写的词(并没有diss周董的意思)。获取周杰伦所有的歌曲后,并从中挑出方文山作词的82首,并人工删除了live、remix等歌词相同的歌曲版本。
由于时间轴和创作者等额外的信息大多有统一的格式,比如时间轴都是用[]括起来,编曲作词作曲等信息也都会在姓名前标注人员类型,可以直接用正则表达式去掉。
清洗前:

清洗后:

“
填词机器人”模型的构建,参考了“Python 深度学习库”tensorflow_poems(https://github.com/jinfagang/tensorflow_poems)中比较成熟的经验,通过学习示例,可以帮助快速学习神经网络的搭建。构建细节本文不做介绍,有兴趣的同学可以自行去GitHub上查阅。本次搭建的是一个基于LSTM的seq2seq模型,并在此基础上进行不同模型配置下的实验。
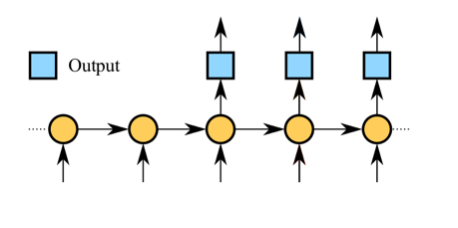
(seq2seq模型图)
生成过程中需要先输入一个关键词,然后拓展为短语,并生成第一行歌词。接下来每一行歌词都是结合已经生成的歌词进行生成。
为保证训练效果,本次实验使用了三层 LSTM,虽然会导致训练时间变得很长,但训练的结果会比较好。根据第一次训练效果可以看出,大多数句子语句不通,但作为歌词的话,已经有一些意象,比如“哭泣的墙”、“天上是云来”之类的。
教堂的夜里 我只是一瞬间
不能在空上的风 就像我的生活
哭泣的墙 断开撕破纱窗
我不能在的感觉你会怎样
没有得少是单车 生活的时候
天上是云来
我看到痛的一种悄悄
我不想要 你的声音
由于训练样本较少,第一版生成的8行歌词中,大多数都不能称之为句子,缺少基本的逻辑关联。为此,处座增加了样本量,把方文山为其他歌手填词的作品也爬取了下来,歌曲列表参考了网易云音乐上的歌单(
http://music.163.com/#/playlist?id=451721655
),一共312首歌。但由于方文山的创作中也不全是中国风,也包含了很多大白话的口水歌,处座担心机器人不小心走歪掉,于是丧心病狂的加入了“宋词三百首
”
。重新训练后,跑出了第二版歌词。
这一版中,由于增加了学习样本,看上去已经很像歌词了,比如“前世离愁,脸颊北风落下”、“一路斜阳回忆奔走”,但仔细看就会发现,每一句都不知道在说什么,更像是词汇的堆砌——
一盏过往 看窗外你的风景
我无力抵抗 教堂影子
谁的故事 一路斜阳回忆奔走
为什么了断弹奏声 充满想象力已不在
前世离愁 脸颊北风落下
微笑的 是的稀有
过往不在挫折 女孩温柔我们
雾气露出破绽 旧的旅行剥落
为了让歌词更有内涵,不再是无意义的词语堆砌,处座又重新优化了模型,将创造歌词的过程拆分为两个步骤,分别由
规划模型
和
生成模型
负责。规划模型负责每一句歌词的主旨,通过输入文本,进行关键词抽取和RNN模型进行拓展,最终获得一个主题词汇的序列,作为歌词每一句的大纲。生成模型在原seq2seq模型基础上,增加了一个encoder为规划模型中生成的主题词汇获得一个向量表示;另一个encoder负责编码已经生成的歌词;Decoder综合两个encoder的内容,生成歌词的下一句。
经过两次优化后的机器人在歌词创作上表现更好,不仅歌词更加流畅,整体上也更像是有逻辑的表达,而非简单的词语堆砌了,甚至有几句还押了韵。摘取其中两段
。
歌词片段一:
任他江山多娇 与尔远离人世喧嚣
错过花开 恰逢凋谢 沐浴迎面的风雪
穿不透的心房
流水野桥 世外古道 往事莫追柳絮飘
飘落灿烂 花已向晚 不知魂已断
过尽千帆 寻不回离岸的船
邀明月 举杯饮尽这风雪
执手相看 转身已是永远
歌词片段二:







