颜萌 整理编辑
量子位 出品 | 公众号 QbitAI

近日,在DeeCamp创新工场深度学习训练营期间,创新工场AI工程院副院长王嘉平开讲《low-level的计算机视觉》一课。
量子位把课程全部内容整理如下:
今天要和大家一起聊一聊的是low-level的computer vision。
当下这个时代,high-level vision已经有了长足的进展,在包括face recognition, 自动驾驶等的领域提到的次数也越来越多。
那我为什么要讲low-level vision呢?我们知道在high-level vision task的中,machine learning很强大,只要给它一些数据,足够的资料,它就可以学出来。但我们更需要关心一下数据是怎么来的,数据本身有些什么样的问题。这些都和low-level vision有关。如果了解了low-level vision,做 high-level vision的时候有非常大的帮助。
我举一个例子。
很久以前在做OCR的时候, 我们要在image中把图像识别出来,而machine learning task拿到的数据不是无限的,只cover了一部分,这当中隐含了一些不想要的数据的变化,比如OCR上的光照的变化,渐变和一些distortion,而且跟这个字具体是哪个字无关。
但是如果你不去掉这些变化,直接往machine learning model里面丢,如果数据足够的多,当然model可以把这些无关的变化和有关的变化分开,但事实上没有那么多的数据。如果你学了low-level vision,你就可以想是否能预先把这些variation去掉,再送到machine learning 里面去,会使后面的machine learning更高效,依赖于更少的数据。
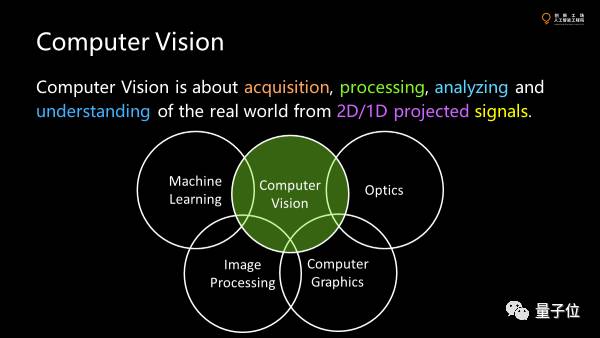
CV涉及很多方面,从信号的获取,处理分析到最后的understanding,和很多学科都有关系,像machine learning,optics,computer graphics,并这关乎我们对于真实世界的理解,但由于传感器的限制,我们这样的理解通常来自二维或者一维的投影,而不是完整的三维的数据。
所以这件事情基本上是整个CV,尤其是3D CV最大的挑战。

首先对于CV,计算机看到了什么?
对于这张图来说,虽然已经是三维空间的投影,但也不是三维空间本身,我们只看到了一个侧面。很多物体被遮挡了,很多信息被丢失了。

对一张图像来讲,我们量化了每个方向上接受的光子的通量,并且离散化,拿到了一个包含很多值的数据集。每个值代表了传感器上一小块面积所接收到的单位时间里的光通量。光强越大,值就越大。这就是计算机看到的图像。
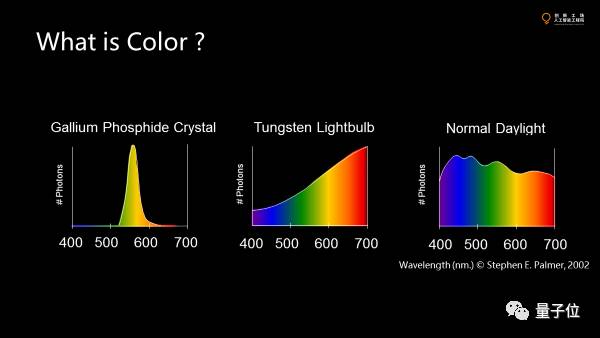
我们先讲一个pixel上的value是怎么来的。要提到的是,它上面可能是luminance,也可能是luminance per channel。我们现在看到RGB,也就是3个channel。
channel代表颜色。而颜色没有单位,因为颜色不是物理量,是主观的量,本质上是我们的传感器也就是眼睛看到不同的光谱时在感光器上激发的量,真正的背后的物理量是光谱,也就是在不同频段上能量的分布。
人之所以感觉到颜色,是人类视觉系统用这三个积函数去积分了所接受的光谱,最后形成了三个感光细胞所拿到的系数,然后映射到RGB的色彩空间。
色彩既然是主观的,不同的生物也不一样,这和生物在整个生态系统所处的位置是有关系的,是生物进化导致的。
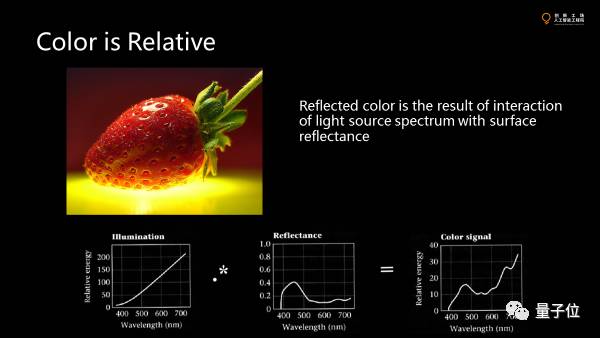
颜色不是绝对的。
除了直接去观察光源,大部分颜色是光源的颜色和物体表面所反射的系数乘积得到的颜色,是叠加反射系数的颜色最终看到的。这就意味着我们看到的不是物体本真的反射光谱的分布,而是它跟光源交互的结果。所以在现实中不同的物体反射出的差别很大。

描述各种反射特性的物理量叫BRDF。
首先是反射系数,多少量的光强达到这个表面上有多少量的光强被反射出去了,并且这个光强和入射角度和出射角度都是有关系的,进去一个球面的角度,出去一个球面的角度,所以总共它是一个四维的函数。
这个在图形学里面被非常heavy的study。因为我们要在计算机里重现真实世界中物体的外观,这个函数就决定了这个物体的外观是什么样子的。我们做一个matching,做stereo,从不同的角度看物体,试图去找到对应的点。
这里的挑战是假设这个函数是一个常量,就意味着对这个特定的点,不论从哪个角度,颜色一样。真实世界不是这样的。
真实的世界中,这个BRDF并不是一个常量。即使是同一个点不同视角去看颜色也是不一样的。

早年的vision里面,会假设一个所谓的lambertian surface。
反射是由于物体表面粗糙的微元面导致的,光打上去后会朝不同的方向去发散反射。假设光强在各个方向的反射是均匀的,这个就叫diffuse reflection。
粉笔和石膏就和这个十分接近。diffuse reflection意味着什么呢?早年的stereo算法都假设对特定的点从不同角度去看都是一样的,我们就可以用不同角度图片上的feature点去做对应,推演其三维空间的位置。但是实际问题是specular reflection。

光源反射不均匀,通常会在镜面方向上多一点,然后形成沿着镜面光源散射的specular peak。
如果这个specular peak很瘦,就会形成一个很亮的点。极限情况下它可能是一个冲击函数,这个时候物体看起来就像一面镜子。有点时候又会宽一点,比如哑光的材料。
这个会带来很多困难。因为multiple view的时候颜色会发生变化,尤其specular很强的时候,就会导致stereo,matching等很难做,很多算法也会受到影响。
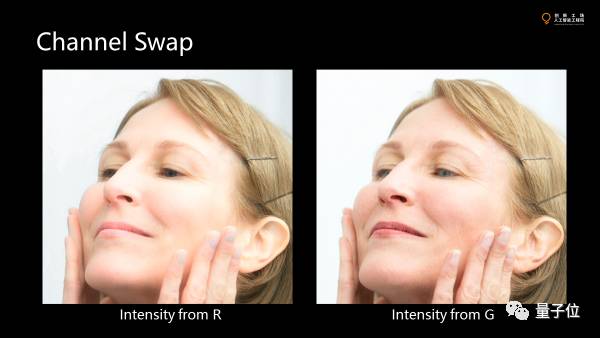
这是一个简单的磨皮算法。大概三四行代码就可以实现。
大家怎么看一个磨皮算法的效果?就看在去掉脸上皱纹的同时,眉毛和头发有没有留下。磨皮算法本质上要把空间中一些细节去掉,但对于计算机来讲,很难区别纹路,是皱纹还是毛发。
这里的两张图,左边的图里把所看到的亮度的变化的G和B去掉,只用R来构造亮度的变化。当然只把亮度替换掉,把颜色留下。另外一张则把G留下。
由于不同波长的光在皮肤里散射的不同,散射强的红色就会把皮肤的褶皱给blur掉,但毛发不受影响。绿色就基本没有做什么blur,留下了皮肤上各种粗糙的东西。
有种说法是尼康相机适合拍人像,原因是什么呢?人类构造图像有三条三原色的曲线。相机为了接近人类的视觉,构造出人类最后可以看到的图像,同样也有类似的三条曲线,尼康的传感器里构造RGB系统时分量系统往绿色和蓝色的分量少一点。当系统把很高维的分量投射到三维里面去的时候,背后的光路是不一样的,虽然投影后颜色是一样的。佳能往高能量的光谱多一些。因此尼康拍人像的时候,细节更多来自红色的通道,所以皮肤就会看起来很好。当然这个差异不是非常的大。
说完光谱的事情,我们现在假设所有的事情在一个通道上发生。
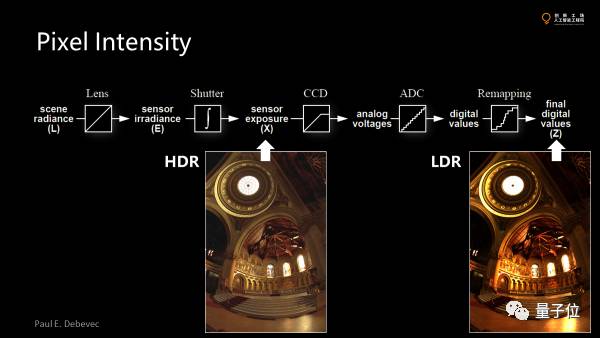
对于现有的大部分传感器,光进来后经过一系列的处理最终变成图像上面pixel上的value,这里有几个步骤。
首先经过一个镜头并处理后,有一个exposure。因为传感器不是真的拿一个snapshot,其实是积分了一段时间才能测量到光的强度。然后经过模式转换器,把光通量模拟量转换成一个数据量。最后还有一些post-processing。
为了尽可能多得看清细节,亮部暗部都要有一些。但我们发现最终的图像有些部分饱和掉了看不清楚了。
那么在vision的采集系统里都有哪些坑?
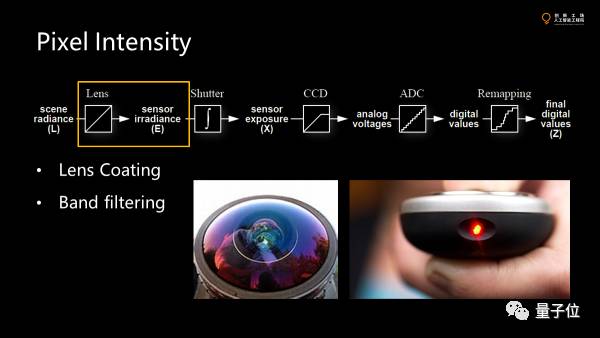
首先,过镜头的时候会滤掉一部分波长的光,因为大部分系统不是为vision understanding设计的,是为拍照设计的。为了得到更好的成像的质量就会滤掉一些对于构造图片没有用的光。紫光一般被反射出去了。
这是一个増透膜,使得更多的光进入镜头,可以提高照片质量。
大部分CCD和相机其实对红外光都是很敏感的,我们可以拿遥控器对着手机看是很亮的,所以几乎所有的镜头都会对红外光有一个过滤。如果不过滤,几乎是一片白。
这部分做了一个filter mask,把我们不想看的紫外红外干掉。剩下可见光透过镜头。
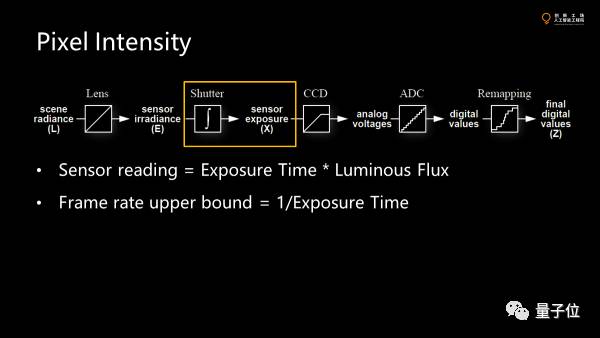
接着是曝光。
最后,sensor上面读到的数据等于曝光时间乘以光通量。因为传感器的敏感度是有限的,进光量很小的时候为了把照片拍出来就需要比较长的曝光时间,那么为了完整地获取图像的一帧,就需要帧率不能超过曝光时间分之一。
自动获取图像模块把曝光时间调大,一旦调大到帧率分之一还大,帧率就会降下来。
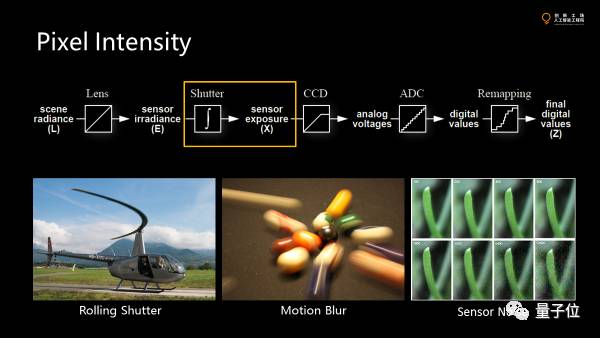
这里的第一个问题是rolling shutter。
大家看到这里直升机的螺旋桨拍下来不是直的。因为当我们的成像的时候,图像上的像素不是在同时获得的,最上面的pixel可能是0.0001秒,第二行是0.0002秒。整张图像是扫描获得的,而物体运动足够快的时候,不同行获得的信息不一致,但扫描的过程是连续的,所以最后的图片就变成这样一个连续的扭曲了。
第二个是motion blur。
同样拍运动物体。为了测量不同pixel上的进光量,就需要一个一段时间的积分。如果在那段很短的时间内有很多的snapshot,我们把它们叠加到一起。如果物体运动得够快,哪怕10毫秒可以造成图像很大的不同。在exposure的瞬间,物体已经跑了一段距离了,那么最后拿到的是积分的结果。比如识别路牌,motion blur 对此就很不利。
为了减少这两种问题,最好的方法是减少曝光时间,这意味着在成像过程中,会有更少的光子来。假设传感器的敏感度不变。不同的照片在不同的iso上拍的。
由于成像系数在前面计算,不涉及量化的问题。如果把曝光减少,不调iso,图像就会变暗。而当曝光时间很小,猛调传感器系数时,就会出现噪音。因为传感器本来就有热噪声。所以曝光时间是一个矛盾的事情,太大了会blur,太小了有噪声。

我们再说到CCD上面,传感器上会发生两件事。
第一是饱和。光是线性的,为了拍出暗部,把亮的部分砍掉。意味着我们可以确定亮度范围,把超出的部分砍掉,然后去做量化。
这里会有几个问题。
我们为了拿到暗部的细节,就会丢掉亮部的细节。如果为了留下亮部的细节,要使整张图片都没有饱和。亮度除以一万倍,最亮才能fit到量化空间里,但暗部的细节就没有了。
本质上说图片量化精度不够,而没有那么多量化点。我们会人为选择的量化范围。要不留下亮度的细节,要不留下暗部的。线性量化的时候,有时候量化精度不够,比如gif图像通常量化的层级不够。我们有时可以过渡。
这些都是因为我们的传感器和处理电路的限制。一般的图像是8位。有些人要拿raw,就意味着拿CCD原始的东西。有的CCD里面的raw是10个bit或者12个bit一个变量,这样量化要好些。
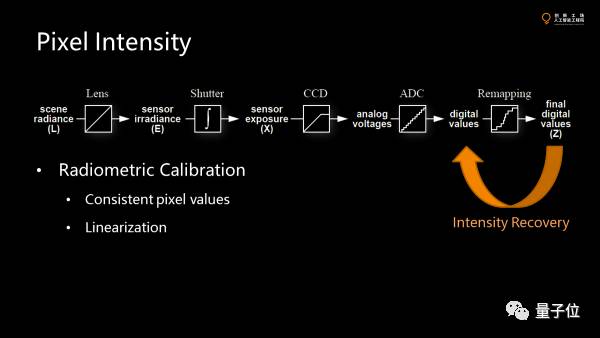
最后是对模式转换器做最后的变化。
前面全部是线性变化。这一步是非线性的变化,比如白平衡,色彩的矫正,伽玛矫正。
这里面的伽玛通常是值的1.2次方或1.5次方,这个可以近似人眼对光强的反应:人眼的反应不是线性的,这意味着暗部的量化精度高于亮部。
大部分手机或单反拿到的图像,引入非线性意味着什么呢?
比如我们要做人脸识别,要去掉或者归一化光照。假设pixel的值是线性。其实不是,都被处理过。真正做归一化,先要做intensity recovery,通过拍摄不同亮度的照片反求这个函数。
因为是单调的函数,所以可以反过来算原来的线性空间的值。严格的做法是把值线性化,叫radiometric calibration。这是很多做vision task的第一步,但是很多被忽略了。
这个是可以保证我们拿到的pixel 是线性化之后的值。如果做线性变换,同比增加亮度,拿到的值不是2:1。线性化之后以后比例才能一致,才能准确地把光照条件带来的variation去掉。

在这个过程中我们可能会丢失很多信息。尤其一个场景一旦饱和掉,不同pixel的值就都一样了。
为了改善这件事,有个东西叫HDR,用最后从传感器拿到的图像重构光进入传感器前的场景。HDR其实是高动态范围的图像,最大值和最小值的差距很大。
重构原理是因为拍照只留下设定的亮度范围,只有这一段会被量化。那么我们不断改变曝光量,得到这个序列当中各个亮度范围的细节,再把图像叠到一起。假设曝光时位置不变,那么每个pixel就可以对起来。
我们把没有饱和的像素都选出来,做平均——这个首先要在线性化以后的值上做,把原来的值线性化——叠加完后拿到HDR图像,每个通道上的值都是一个浮点数,这样就可以表达很大的动态范围。

然而我们的vision不是孤立地看一个,要看很多像素。这些像素有固定的结构和pattern,local feature在很多vision task里面都要用到。
vision代表着图像中物体的piece,它虽然对物体的feature没有理解,但它企图去抓feature,这就是认定图像有一致的localization,不管在什么位置,不管物体的位置和朝向,这个特定的feature点都跟着物体走。
feature找到后,要去encode这个feature,这个的对slam或stereo非常有用。
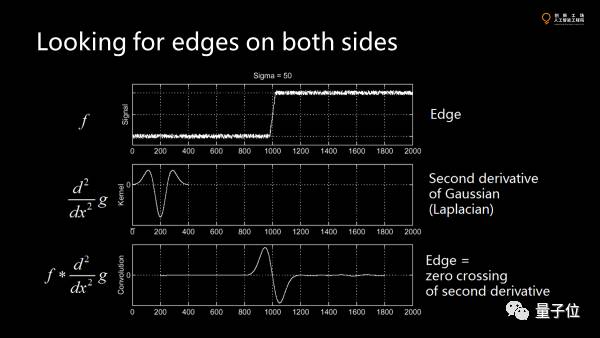
我们再回归边缘检测。边缘检测就是在图像中找到比较显著的不连续的边界。
在一维里,用高斯函数的二阶导卷积图像里得到一些小波浪,这些小波浪会跟着图像走,这就是有localization特性。然而对一个pattern,要用两个边界去刻画。我们不仅需要知道feature的位置,还要知道大小。
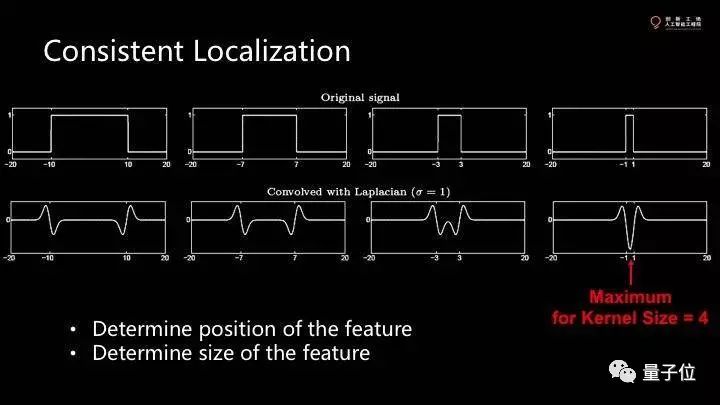
这个函数的积分信号和卷积和不是我想要的。信号的size当和卷积和的kernel size差不多的时候,我们可以得到一个local minimum,这个点就是我们想要的。
这个点可以告诉我们feature的位置和大小。实际上遍历各种不同大小的kernel去卷积,我们把它拓展到二维,就是一维函数沿轴旋转一下。
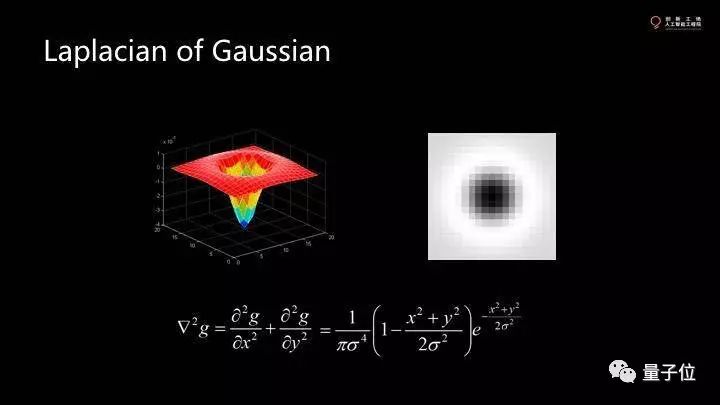
二维函数的本身是高斯和的二次求导。这个函数能够在不同的宽度间拿到不同的值,使得不同的层互相比,到处找local minimum。最后拿到的数据中,每个圆圈的中心表示feature在哪里,每个圆圈的大小表示feature有多大。
最关键的在于如果我把这个图像挪动,缩小,转动,这些feature点也会跟着走。还有就是卷积的图像不只是一张。这些feature点是在不同的层上找的。因此找minimal不是在x,y上找,而是在x,y,z上找,然后投影。

所以当我们很好的抓到这些位置之后,那么首先要确定feature的位置,当feature点位置确定,要确定来自同一个函数,意味着我们要有一个尺度的衡量,我们不仅要知道一个feature点的大小和位置,我们还要在知道内容是什么。
基于算法找到feature后,用一个向量表示feature的内容,并抵御缩放带来的影响。这个feature里物体的远近出来的值差不多。x,y的移动已经归一化。z轴也归一化掉。
这个大量被使用在3D重构。本质思想是线条朝向记下来,计算梯度,用朝向刻画内容,再用8个bit去刻画。由于相机的图像是在不同的位置拍摄的,假如没有运动的很快,就会是有重叠的,但拍的时候由于在动,不能简单的叠加,要一对一对的解图像间的关系并拼起来。
抓到feature点后就来找对应。对应里可能会有很多的错误。求解的就是把所有的对应关系联立上面大方程。每一个点做一个变换。这个变化是一个3×3的矩阵。只要超过9个方程,矩阵就可以求解。

不正确的对应关系不能包含在线性系统里面,不然结果会偏掉,假设正确的对应远大于错误的,随便找几个对应关系。求解t,大部分正确但有偏差的。反向验证对应关系,跟transformation是否一致,过于不一致就丢掉。
拍摄的时候光照的参数有点不一样,细节一致,绝对亮度稍微有点不一样。这就已经不是vision的事情了,是graphics的问题。有个泊松image的方法,梯度留下,绝对亮度丢掉。点与点之间的相对梯度关系连起来求泊松方程,解出image。这样解完以后边界就会消失了。
摒弃了绝对亮度,利用梯度的亮度重新生成。
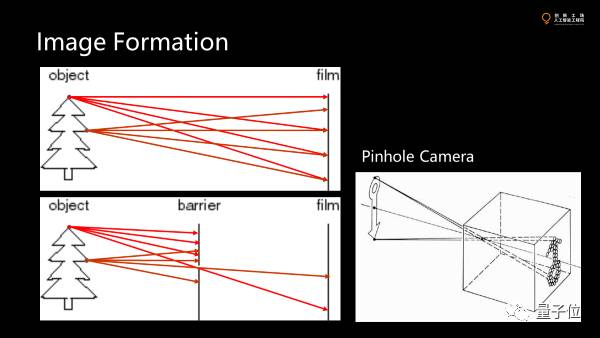
那么三维空间的投影是怎么发生的,成像是怎么成的呢?
现实中每个物体对所有方向都在发光,放一个胶片或传感器上每一个点上的光照强度都来自于目标物体所有点的光强。要成像就要使得传感器上受到的光照来自物体的一个特定的点。
可以在光圈留一个很小的洞,唯一找到小孔反向求焦到真实世界的一个点。这就是小孔成像,也是最经典的pinhole camera的模型。
之所以能成像,要使得这一个点被照的内容,来自于尽量少的目标物体的点,小孔越小,光锥越小,点只贡献到接收面上的很小一个点。小于一个像素就可以成很清晰的像。
但当孔很小的时候,跑到传感器上的光很少,图像会很暗。理论上可以无限增长曝光时间,不断积分,但并不实际。
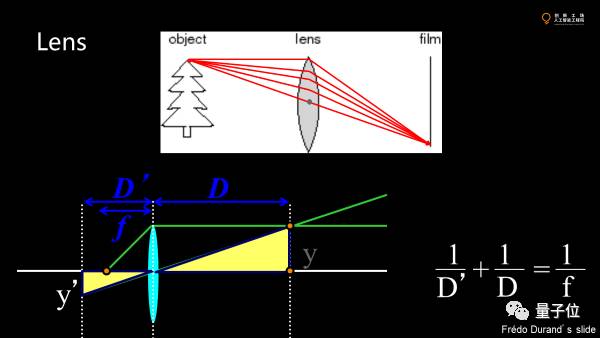
如果可以改变光的方向,聚到一个地方去,图像就可以清晰且不会太暗。于是人们发明了镜头,使点偏离光轴方向发生偏转,形成聚焦。物距和焦距定了,像就定了。

但传感器是平的,只能捕获一个方向的像素。实际物体时三维的,有一些点的最佳成像位置不同。有一些点会正好落在传感器上。这就是景深。
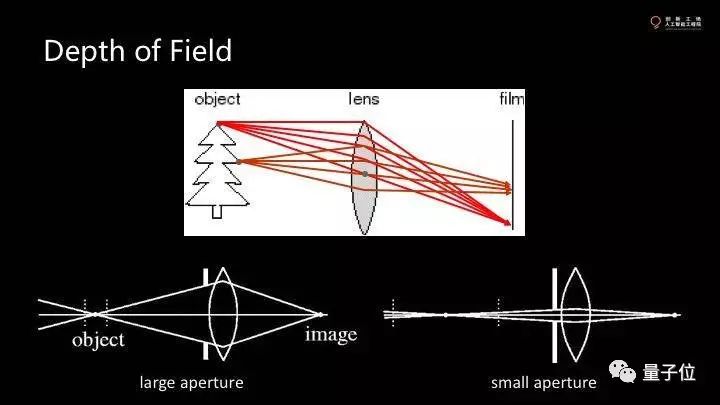
只要在景深的范围内成像就是比较清晰。其他点一定存在blur,只要小于一个像素,就仍旧是清晰的。有时候因为距离的不同,真正的焦点会相差了一点点比如0.1毫米,这在图像上会造成多大范围的模糊,还由光圈决定。
光圈小,blur的半径会小一点,前后都清晰,但进光量会小。光圈大,镜头得大。意味着相机会大。而传感器大,单元面积大,接收更多的光子。如果焦距越短,张角越大,就像监控的广角相机,一般大家不想要这种效果。
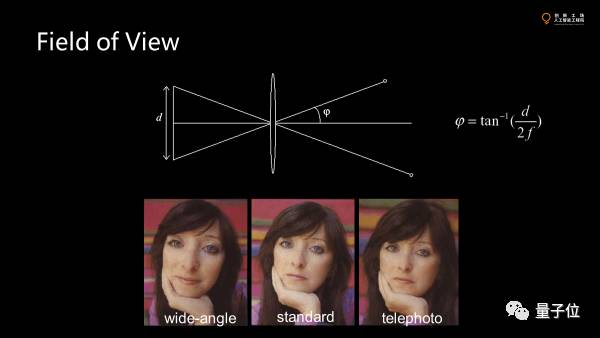
视角变大就会引入径向的畸变。径向畸变一个是因为镜头的不完美,另一个是视场角,太大会形成突出的球面的效应。球面映射到平面总会有扭曲。

畸变可以建模,扭回来。但是范围就会奇怪,意味着就会裁掉一些东西,浪费一些像素。


为了更方便地去描述3D场景是怎么样被投射到二维的,机器视觉里引入了一个叫齐次坐标的东西。
因为使用除法后就不是线性系统,所以我们给它升维,这样做的好处是升过维的向量可以和后面所有这些transformation可以formulate到一起去,变成一个线性的东西,最后成像的时候计算图像空间点的位置,在最后除一下就行。
图像距离越远就会越接近光轴,那么这个除法先不做,最后成像后再做,前面计算过程中就可以回避非线性的问题。
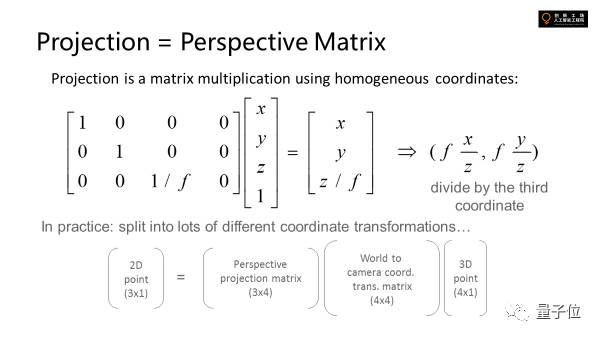
这些在数学中的公式就是perceptive matrix,四维投射成三维的矩阵乘法。真实世界中空间中有一个三维的点,有一个world坐标到image坐标的转换过程。
比如世界坐标系先建好,所有的点都定义进去,这时候相机可以放在特定位置,会有一个矩阵来描述,把世界坐标系转化为相机坐标系,再乘perspective matrix,再相机坐标系转换到图像坐标系。
这就是三维成像的基础。
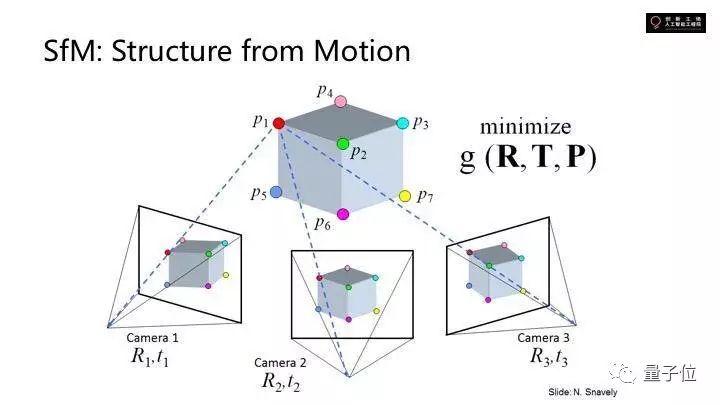
这是处理大规模三维重建的方法。空间中的点拿到的图像乘了一个空间变换矩阵。现在相机和点的位置不知道,同样一个物体被几个相机拍了,联立可以求得物体上的点和相机的位置。这个就是它的目标函数。
假设旋转矩阵为已经知道了,translation和perspective都知道了,对应空间中的所有的feature点,点在图像上的正确位置是知道的。
要猜测求出空间中的位置,minimize这个错误。可以拿到相机的位置。这是非常大规模的,要优化几百万个点的位置,几千张照片对应几千个不同的相机的位置,还要同时优化相机的位置,最终做一起minimize。


比如去互联网上搜集某个景点游客拍摄的图片。做joint optimization。做local featurization会发现各有一堆的feature点,任何两张feature点可以构造几千个点,算出空间的位置。
如果联立照片中三维点的位置就能重现一个点云出来,用点云刻画三维场景中点的位置。但因为只是一个点云,不是完整地构造几何的表面。
同时对于那么多图像,可以算出每一张是哪个位置拍的,google的街景就是这样,这些点云可以自己算出来是哪个位置拍的并精确到pixel level的位置。这样就可以让你很好的在照片与照片间游走。就重建这个三维。

回想一下,这里用到的技术。每个点成像怎么来的,根据这个定义local feature ,找到两个点的对应关系并进行transformation。
所有的变化是在image space里面变换的。这里的不同位置是有视差的,求解不是图像空间的变换,是三维空间的变换。两两去做会发生最后的点云和重构的点云接不起来。因为传递会积累误差。
如果距离很远的话我们就要去重构一个大范围的物体差别在于不同的图像重叠部分有多大,如果很大,那么drafting也会很大。
那如果每次都重叠很小,transformation是通过链条积累起来的。这个就需要大量的feature点联合。
总结

high-level vision task的时候,成像是一个imperfect的,而且有一个假设,不是我们想获得什么数据。同时获得的数据是不是有问题的。告诉我们图像的变化是怎么来的,是不是我们想要的。如果可以预先知道,提前去掉,使得数据的使用率大大提高。一旦high-level里数据不够,出现误差,不能收敛,我们就需要去看看数据怎么来的,回头看看low-level vision怎么来的。做machine learning等的时候,有时候去死调你的算法参数不如获得更多的信息更好的数据有用,根据场景设计你的传感器系统,camera放在什么位置,什么光源。这个对high-level understanding能不能做好很重要。
问答环节:
1. 点云生成后下一步是什么呢?
基本的思想是两个方面的信息,告诉你每个点的位置直接连线,不一定可靠。每个点周围有很多点。先构建一个graph,和周围联系起来,但不能保证重构起来的是合法的流形。此时就有一堆几何处理的算法砍掉不正常的边和点。
当图像足够多的时候还可以知道每个点的法向量。
如果对同一个点,拍的照片能发现不同光照的亮度,根据拍摄时间和朝向估算光源的位置。在图像空间中重构法向量,不但给位置也给法向量。一旦有法向量就知道和graph哪些边是不能连的,可以更好的构造面。
2. VR里vision是否需要更多算法去提高渲染质量?
不是vision的事情,更多是graphics的事情。
为了得到高质量渲染的图像,对物体的material要有很好的描述,比如BRDF能在计算机里渲染出和照片一样逼真的画。
第二个是光照。除了photography上的应用,在computer graphics里也很有意义。早期看到的graphics渲染的东西很artificial,很大问题是点光源化。
现实中不存在绝对的点光源,光还会间接照射这个物体,本身是全局的光照计算照射系统。用HDR图像刻画整个场景对它的光照,不是一个点去照射,而是一个球面积分,这样渲染的质量会更接近真实的世界。VR现在机能没有那么强。
3. 三维空间的表面反射比较强部分,怎么重建三维?
最基本的方法是找到不同视角对应的点,反算在空间的位置。但一旦对应关系不能被建立,就不能通过找对应重构。
这里用photometric stereo,对物体打个侧面的光。打很多侧面的光,如果有物体表面反射一定假设,就能求出每个表面的法向量。只要改变光源的位置就能求出空间中每一个法向量是多少了。
有了法向量,积分就可以求出物体的曲面,位置。另外一套算法是把场景弄成一片一片,每一片都可以求到一块集合。先用法向量来做。
比如说有的物体表面反射光强和奇怪,不能找对应。那么把图片单独做,把面上的法向量求出来,和视角无关。我们就可以回到原来的路,找对应,不是用RGB color找对应,而是用法向量构成的feature来做。
4. 机器学习中识别RGB ,如何用光度的方法如何把法向量丢进去学?
比如卷积神经网络,后面几层都一样。关键是前面几层。现在前面的卷积的kernel,灰度图像除了5×5之外,只有一个5×5的卷积网络。如果后面是RGB后面就需要有三个。但因为向量是normalize过的单位向量,所以只要2个5×*5的就够了。
我只关心每个pixel上有几个维度,每个维度内容是什么我不关心,只不过每个维度的value不一样。本质还是刻画图像的原本的特征,但是一个是RGB的体现,一个是法向量的体现。比如一个RGB的kernel,每个点上面,除了RGB还有D,不做更好的优化,可以直接丢到CNN里面,但是对前面卷积的5×5需要换成5×5来对应于每一个channel,这个实现就够了。
有时候我们还是要care一下range不一样。数据可以直接丢,也可以做一个归一化,但归一化可以让全连接网络去学也不难,但是你开始不要直接丢进去学。前期已经知道模型的时期就不要丢进去学。要准备的数据也会变少,过程也会变简单。
5. 法向量可以丢进去,我们在标法向量的时候很难标定条件怎么办?
法向量是算出来的,光源也是算出来的。假设光源远,就可以放一个球,预先知道球的法向量,反算光源的位置。如果点光源近,就可以放四个球,预先知道四个球的法向量,通过光求的最亮点反求出方向和距离,就可以知道每个法向量是多少。
8月9日(周三)晚,量子位邀请三角兽首席科学家王宝勋,分享基于对抗学习的生成式对话模型,欢迎扫码报名
▼
量子位AI社群6群即将满员,欢迎对AI感兴趣的同学加入,加群请添加微信号qbitbot2;
此外,量子位的专业细分群(
自动驾驶
、
CV
、
NLP
、
机器学习
等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请添加微信号qbitbot2,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。





