
作者 | XLNet Team
译者 | 孙薇
责编 | Jane
出品 | AI科技大本营(ID: rgznai100)
【导语】几周前,XLNet 团队发布了新型预训练语言模型 XLNet,这个新模型在各项基准测试中都优于谷歌之前发布的BERT模型,其中模型
XLNet-Large
的数据量更是 BERT 模型的 10 倍左右。那 XLnet 和 BERT 到底要选谁?
这次 XLnet 团队进行了一次对比实验,为了确保对比的公正性,在对比实验中
作者采用相同的环境和配置,相同的训练数据,并确保在 BERT 和 XLNet 两个模型的训练方法中,几乎每个超参数(hyperparameter)都是相同的,这些超参数都是由 BERT作者发布,并在BERT中使用的。即是说,这些超参数是为BERT模型设计选择的,很可能是针对BERT最优化的,而非XLNet。具体超参数设置如下
(两个模型的超参数完全相同):
-
Batch-size: 256
-
训练步数:
1M
-
优化器:
Adam,学习率 1e-4,warmup 1万,线性衰减
-
训练语料库:
Wikipedia + BooksCorpus,在处理Wikipedia时使用了与BERT repo相同的工具,但出于某种原因,我们的Wiki语料库仅有20亿单词,BERT使用了25亿单词,因此XLNet的训练数据略少于BERT。
-
模型结构参数:
24层,1024个隐层,16 heads
-
微调(finetuning)超参数搜索空间
此外,作者还修改了一些数据相关的实现细节,以便与BERT模型进行一对一的比较。
-
在之前的实验中,预训练环节,未被mask的token无法看到分类token CLS和分隔token SEP,而现阶段的实现中可以看到了,与BERT模型保持一致。
-
在微调环节,与BERT一样,用“BERT格式”取代了普通的 XLNet格式,即使用[CLS, A, SEP, B, SEP] 取代了 [A, SEP, B, SEP, CLS]。
另外,我们考虑了BERT模型的三种变体,并报告了各个单独任务的最佳微调结果。
三种变体如下:
-
模型1(Model-I):BERT
作者发布的原始BERT模型
-
模型2(Model-II):
同样来自作者的中文全词覆盖模型
-
模型3(Model-III):
由于考虑到下句预测(NSP)可能会影响表现,我们使用BERT已发布的代码针对没有NSP loss的新模型进行了预训练
注意:由于通过不同变体可以获得各个任务的最佳表现,以上设置也许会让BERT模型更占优势。
GLUE 和 SQuAD上的开发设置结果,及 RACE 上的测试设置结果如下(并未使用数据增强、集成或多任务学习):
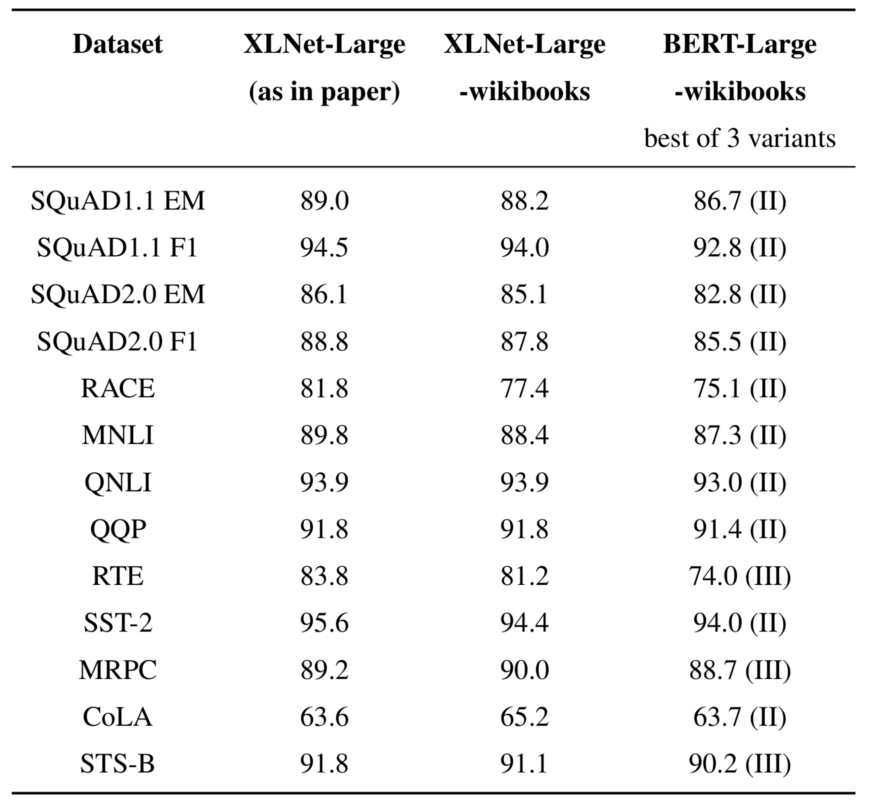
不同模型对比。
XLNet-Large (as in paper)所使用的训练数据更多一些,batch size也稍大。
BERT模型,针对每个数据集我们只报告3个变体中微调最优的结果。
表格中有些观测结果非常有趣:
-
使用相同的数据,以及几乎完全相同的训练方法来训练时,针对所有数据集,XLNet都以相当的优势胜过了BERT模型。
-
投入10倍多数据(对比XLNet-Large-wikibooks与XLNet-Large)的性能提升,要小于在11个基准测试中将其中8个从BERT模型换成XLNet模型的性能提升。
-
在某些基准测试(比如CoLA和MRPC)中,使用较少数据训练的模型,其表现要优于使用较多数据训练的模型。
我们相信,从以上结果中我们也许可以得到一些结果了。
XLNet的性能提高了:
观测结果1与我们早期基于基础模型的对比实验结果一致,证明在指定相同的训练条件时,XLNet模型要优于BERT模型。
XLNet-Large可以优化到更佳:
观测结果2与观测结果3似乎表明,我们之前发布的XLNet-Large(使用更多数据训练)并没有充分利用数据规模。
因此,我们会继续研究相关方法,正确扩展使用XLNet模型进行语言预训练的规模。
根据目前有限的观测结果,我们推测以下训练细节可能发挥着重要作用:
Facebook AI近期 GLUE 排行榜,可能也说明了训练细节的重要性。
总之,本实验将算法/模型的影响,与类似训练细节、大型计算及大数据这样的其他因素明确分离开来。
根据以上结果,XLNet 团队认为:
算法与模型至少是与其他因素同等重要的,它们很可能都是实现自然语言理解最终目标所必需的条件。
原文链接:
https://medium.com/@xlnet.team/a-fair-comparison-study-of-xlnet-and-bert-with-large-models-5a4257f59dc0
(*本文为 AI科技大本营编译文章,转载请联系微信 1092722531)
“只讲技术,拒绝空谈
!
”2019 AI开发者大会将于9月6日-7日在北京举行,这一届AI开发者大会有哪些亮点?一线公司的大牛们都在关注什么?AI行业的风向是什么?2019 AI开发者大会,倾听大牛分享,聚焦技术实践,和万千开发者共成长。
目前,大会早鸟票抢购中~扫码购票,领先一步!
推荐阅读









